





Authors:
Thanh Thi Nguyen、Campbell Wilson、Janis Dalins
Paper:
https://arxiv.org/abs/2408.10503
Introduction
Biometric systems have become an integral part of modern security and identification systems. Among various biometric features, hand images are particularly valuable due to their unique and stable characteristics, such as vein patterns, fingerprints, and hand geometry. This paper explores the application of Vision Transformers (ViTs) for the classification of hand images, leveraging their advanced capabilities in image processing. The study also introduces adaptive knowledge distillation methods to enhance the performance of ViTs across different domains, addressing the challenge of catastrophic forgetting.
Related Work
Traditional Methods in Hand Image Classification
Previous studies have employed various feature extraction methods and classifiers for hand image classification. Techniques such as ripplet-I transform, discrete cosine transform, and local binary patterns (LBP) have been used in conjunction with classifiers like SVM and CNNs. For instance, Hardalac et al. [18] utilized LBP features and Euclidean distance classifiers for palm print verification, while Afifi [1] introduced a large dataset of hand images and used CNN and LBP for feature extraction and SVM for classification.
Vision Transformers in Biometric Applications
Vision Transformers (ViTs) have shown superior performance in image processing tasks. Studies like [16] have demonstrated the effectiveness of ViTs in vein biometric recognition. The ViT models, such as Google ViT, DeiT, BEiT, DINOv2, Swin Transformer V2, and ViT-MAE, have been explored for their capabilities in handling large-scale image datasets and providing explainable AI solutions.
Knowledge Distillation and Domain Adaptation
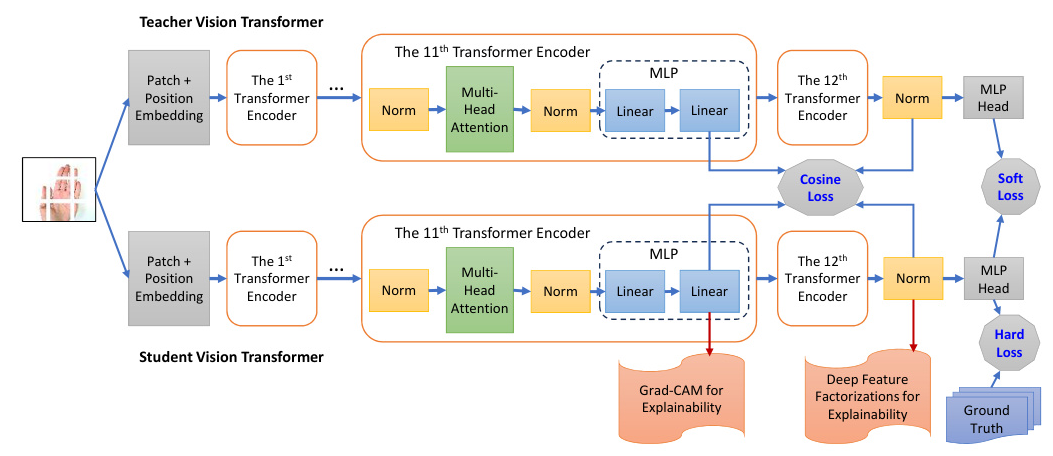
Knowledge distillation, introduced by Hinton et al. [20], involves transferring knowledge from a larger teacher model to a smaller student model. This technique is valuable for model compression and deployment on smaller devices. However, traditional knowledge distillation methods face challenges when the target domain significantly differs from the source domain. This study proposes adaptive distillation methods to address these challenges, enabling the student model to retain knowledge from the source domain while adapting to the target domain.
Research Methodology
Vision Transformer Models
The study investigates six ViT variants:
- Google ViT: Pre-trained on ImageNet-21k and fine-tuned on ImageNet.
- DeiT: Data-efficient image Transformer pre-trained and fine-tuned on ImageNet-1k.
- BEiT: Pre-trained on ImageNet-21k using masked patches and fine-tuned on ILSVRC2012.
- DINOv2: Self-distillation model trained on extensive curated data without supervision.
- Swin Transformer V2: Constructs hierarchical feature maps and uses scaled cosine attention.
- ViT-MAE: Pre-trained using masked autoencoders with a focus on reconstructing raw pixel values.
Explainability Tools
To understand the internal representations of ViTs, the study employs Deep Feature Factorization (DFF) and Gradient-weighted Class Activation Mapping (Grad-CAM). These tools provide insights into the features and regions of images that contribute to the model’s predictions.
Experimental Design
Datasets
- IIT Delhi Dataset: Comprises touchless palm print images from 230 subjects, captured at a resolution of 1600×1200.
- 11k Hands Dataset: Contains 11,076 hand images from 190 subjects, including both palmar and dorsal sides, with detailed metadata.
Experimental Setup
The experiments involve fine-tuning ViT models on the source domain and evaluating their performance on the target domain. The study conducts several scenarios, such as transferring models from left to right hand images and from palm to dorsal side images. The performance is measured using classification accuracy, and the experiments are repeated multiple times to ensure robustness.
Results and Analysis
ViT Models vs Traditional Methods
The results demonstrate that ViT models significantly outperform traditional methods in hand image classification. For instance, in the IIT Delhi dataset, ViT models achieve an accuracy of at least 0.982, compared to the best existing accuracy of 0.940 from traditional methods. Similarly, in the 11k hands dataset, ViT models exhibit superior performance across various experimental scenarios.


Explainability Results
The explainability tools reveal valuable insights into the internal states of ViT models. For example, the Grad-CAM method shows that the ViT model identifies subjects based on features like nail polish, while the DFF method highlights the importance of hand shape and finger dimensions.



Transfer Inference
The transfer inference experiments show varying levels of accuracy when ViT models are transferred to different domains. Transferring from left to right hand images achieves better accuracy compared to transferring from palm to dorsal side images, indicating the challenges posed by significant domain differences.

Domain Adaptation
The adaptive distillation methods proposed in the study demonstrate significant improvements in mitigating catastrophic forgetting. Method 2, which involves imitating the teacher’s internal states, shows superior performance in retaining knowledge from the source domain while adapting to the target domain.

Overall Conclusion
The study successfully demonstrates the effectiveness of Vision Transformers in hand image classification and introduces adaptive knowledge distillation methods to address the challenge of catastrophic forgetting. The proposed methods enable ViT models to achieve high performance on both source and target domains, making them suitable for real-world applications such as access control and identity verification. Future work can explore the application of these methods to other biometric data types, such as fingerprints and iris recognition.
By implementing robust regulations, security measures, and transparency mechanisms, it may be possible to harness the benefits of using our hand image classification methods while minimizing its ethical drawbacks in police surveillance contexts.


