





Authors:
Linlin Hu、Ao Sun、Shijie Hao、Richang Hong、Meng Wang
Paper:
https://arxiv.org/abs/2408.10934
Introduction
Low-light image enhancement is a crucial task in both academic and industrial communities, aiming to improve the visibility of images captured in low-light conditions. Traditional methods, such as histogram equalization and Retinex-based approaches, have been used extensively but often produce suboptimal results. Recent advancements in deep learning have led to significant improvements in this field, primarily focusing on single-image enhancement. However, these methods often neglect the rich information available in stereo images, which can provide additional depth and disparity information.
In this context, stereo image enhancement methods have emerged, leveraging the correlation between left and right views to improve performance. Despite these advancements, current methods still do not fully exploit the interaction between the two views. To address this issue, the authors propose SDI-Net, a model designed to enhance low-light stereo images by fully exploring dual-view interactions.
Related Work
Single-Image Low-Light Enhancement Methods
Traditional single-image low-light enhancement methods include histogram equalization and Retinex-based approaches. These methods adjust the dynamic range and brightness of images but often fail to capture the complex mapping between low-light and normal-light images. Deep learning-based methods, such as convolutional neural networks (CNNs) and generative adversarial networks (GANs), have shown significant improvements by learning end-to-end mappings. However, these methods are limited to single-image inputs and do not leverage the additional information available in stereo images.
Stereo Image Restoration Methods
Stereo image restoration methods have gained attention for tasks such as super-resolution, deblurring, deraining, dehazing, and low-light enhancement. These methods aim to leverage the correlation between the left and right views to improve performance. For example, iPASSRNet uses a parallax attention mechanism to merge similar features from both views. In the context of low-light enhancement, methods like DVENet and DCI-Net have been proposed, but they still suffer from insufficient interaction between the two views.
Research Methodology
Overall Framework
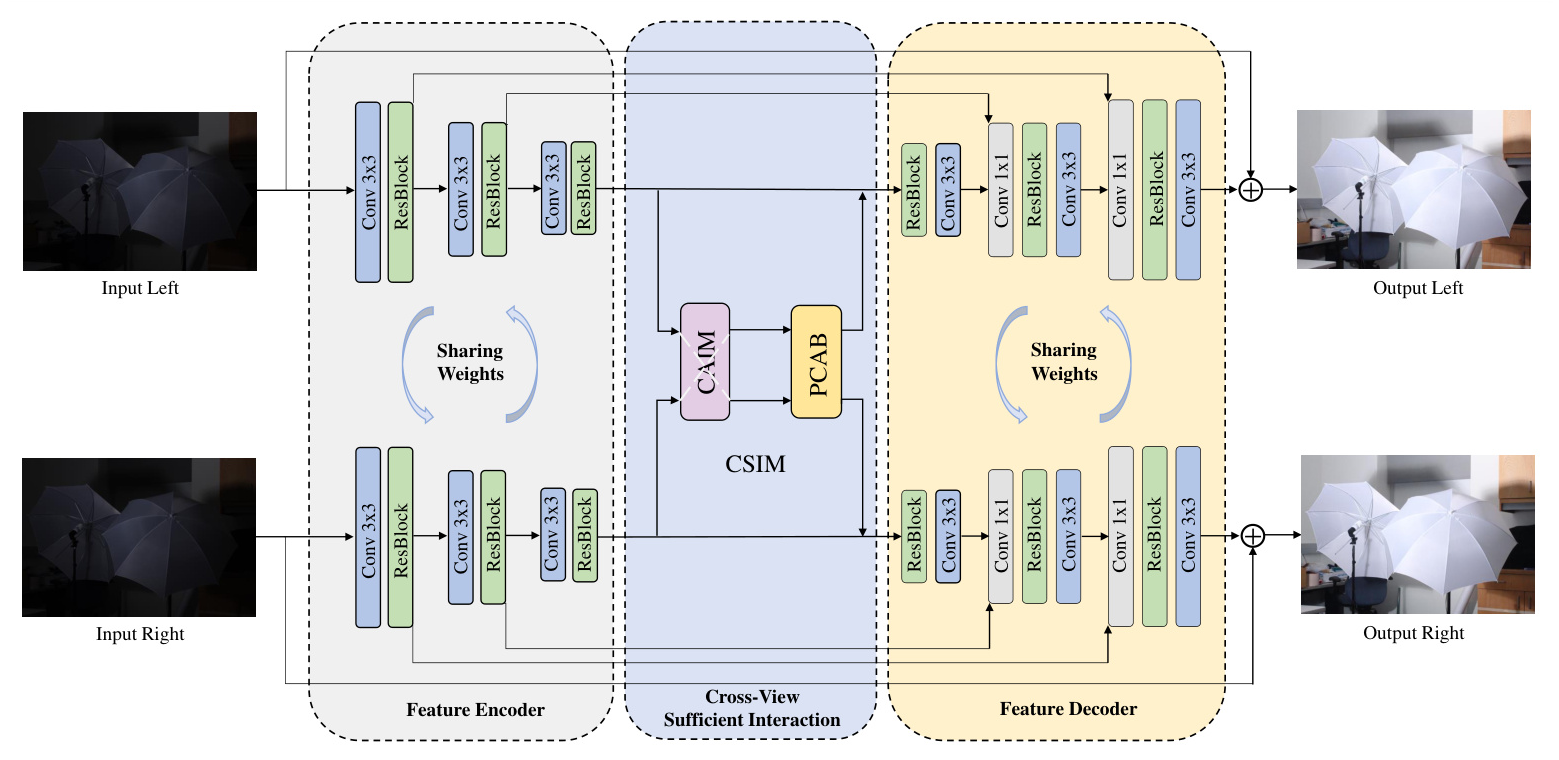
SDI-Net consists of three main stages: Feature Encoder, Cross-View Sufficient Interaction, and Feature Decoder. The model takes low-light stereo image pairs as inputs and uses two identical UNet branches as the backbone structure to learn the mapping from low-light to normal-light images. The Cross-View Sufficient Interaction Module (CSIM) is introduced between the encoders and decoders to refine the learned feature representations.


Cross-View Sufficient Interaction Module (CSIM)
The CSIM module is composed of two parts: the Cross-View Attention Interaction Module (CAIM) and the Pixel and Channel Attention Block (PCAB). CAIM focuses on exploring mutual attention at the view level, while PCAB enhances features at the channel and pixel levels. This module enables sufficient interaction between the two views, resulting in mutually fused features that are then sent to the decoding stage for image reconstruction.

Loss Function
The model is trained using a combination of L1 loss and FFT loss. The L1 loss maintains the overall structure and details of the image, while the FFT loss helps preserve frequency-domain characteristics, improving texture details and edge information.
Experimental Design
Datasets
The effectiveness of SDI-Net is evaluated on two public datasets: Middlebury and Synthetic Holopix50k. The Middlebury dataset consists of high-quality, precisely calibrated stereo images, while the Synthetic Holopix50k dataset offers a broader variety of real-world low-light scenarios.
Evaluation Metrics
The model performance is evaluated using two full-reference quality metrics: PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index). Higher values indicate better performance.
Methods for Comparison
SDI-Net is compared with several single-image and stereo-image low-light enhancement methods. Single-image methods include NPE, LIME, RRM, ZeroDCE, RetinexNet, MBLLEN, DSLR, KIND, DRBN, SNR-Aware, LLFormer, and MIRNet. Stereo-image methods include DVENet, DCI-Net, and iPASSRNet.
Results and Analysis
Quantitative Comparison
The quantitative results on the Middlebury and Synthetic Holopix50k datasets show that SDI-Net outperforms both single-image and stereo-image low-light enhancement methods in terms of PSNR and SSIM.

Visual Comparison
Visual comparisons on the Middlebury dataset demonstrate that SDI-Net produces better visual quality, improving visibility and recovering detailed textures. Error maps highlight the discrepancies between the enhanced results and the ground truth, showing that SDI-Net handles fine details better than other methods.

On the Synthetic Holopix50k dataset, SDI-Net outperforms other methods in reconstructing fine details and producing continuous color textures and smoother image appearance.

Ablation Study
Ablation studies on the Middlebury dataset demonstrate the effectiveness of the CAIM and PCAB modules, as well as the importance of the FFT loss term. The results show that both modules play indispensable roles in the low-light enhancement task.

Overall Conclusion
SDI-Net is a novel model designed to fully explore dual-view interactions for low-light stereo image enhancement. By leveraging attention mechanisms at the view, channel, and pixel levels, SDI-Net facilitates comprehensive information exchange between the two views, resulting in high-quality normal-light images. Experimental results on two public datasets validate the effectiveness and superiority of SDI-Net in both quantitative and visual comparisons. Future work will focus on extending the interaction between the two views into the frequency and semantic domains.



