





Authors:
Kangjun Noh、Baekryun Seong、Hoyoon Byun、Sungjin Song、Kyungwoo Song
Paper:
https://arxiv.org/abs/2408.10923
Introduction
Large Language Models (LLMs) have revolutionized natural language processing (NLP) tasks, achieving remarkable success in areas such as response generation. However, their application to tabular data has been limited due to their relatively inferior performance compared to traditional machine learning models (TMLs) like XGBoost. This study introduces the Language-Based-Classifier (LBC), a novel approach that leverages the pre-trained knowledge of LLMs to handle Out-of-Variable (OOV) tasks effectively. OOV tasks involve scenarios where new variables appear in the test data that were not present during training. This capability is crucial in real-world settings where data constraints often hinder model training, such as in healthcare where privacy and regulatory barriers prevent data sharing between institutions.
Related Work
Tabular Data Analysis with LLMs
Recent advancements have extended the application of LLMs to tabular data analysis. Language-Interfaced-Fine-Tuning (LIFT) demonstrated that LLMs could achieve reasonable performance on tabular data tasks while maintaining their original structure. However, existing models like TP-BERTa and TabPFN lack the ability to contextualize OOVs, a gap that LBC aims to fill.
Out-of-Variable (OOV) Tasks
Machine learning models often struggle to adapt to new environments with additional, unobserved variables. MomentLearn was proposed to address this by using a predictor trained in a source environment and an additional objective matrix for partial derivatives for OOV tasks. However, its application in real-world scenarios is limited. LBC overcomes these limitations by leveraging the extensive prior knowledge in LLMs and methodologies for OOV tasks.
Verbalizer
The verbalizer mechanism maps various output forms from an LLM to specific classes, reducing subjective bias and improving classification performance. LBC applies a verbalizer to map logit scores to classes during inference, enhancing the model’s ability to handle OOV tasks.
Low-Rank Adaptation (LoRA)
LoRA introduces an approach to fine-tuning large pre-trained models by modifying a small subset of the model’s weights through a low-rank matrix. This method allows pre-trained models to adapt efficiently while maintaining their original structure and strengths. LBC utilizes LoRA to fine-tune the classifier, theoretically validating its strong classification performance.
Research Methodology
Basic Dataset Conversion
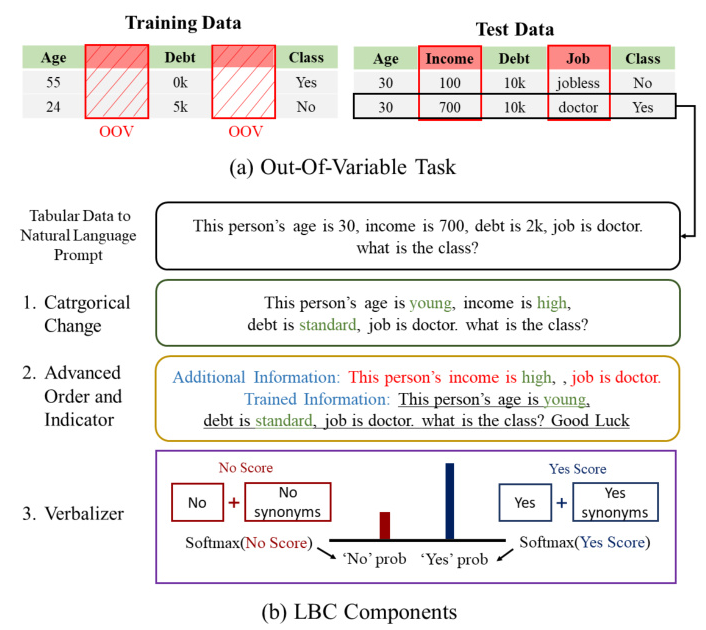
Converting tabular data into prompts for input to LBC is a crucial step. An instance of tabular data with K features is represented as a prompt, clearly distinguishing between variables and the class as the output. This conversion technique ensures that the LLM can interpret the data effectively.
The Order of the Variables
The order of variables in the prompt directly affects LBC’s performance. Different prompts are generated depending on the variable order, and the optimal order is determined to enhance learning and inference.
Fine-tuning LLM
Feeding the converted prompts into LBC yields a vector of vocabulary sizes, which is logit for each word in the vocabulary. The logit is used to fine-tune the LLM, updating the model’s parameters using an optimizer through gradient descent.
LLM-based Tabular Prediction
LLMs offer a promising alternative for handling textual and numerical data in machine learning tasks. Unlike TMLs, which struggle with textual data, LLMs demonstrate superior capability in comprehending semantic content and discerning inter-feature relationships. LBC utilizes the logit score to map directly to a specific class, improving classification performance.
Experimental Design
Experiment Settings
Experiments were conducted using reliable datasets frequently used in studies, specifically selecting those run multiple times on OpenML, Kaggle, or other benchmarks. Five TMLs known for their strong performance in tabular data classification were selected as baselines.
OOV Setting
To create scenarios where variables that do not exist in training appear in testing, 50% of the variable columns in the original tabular dataset were randomly deleted. This method allows for the assessment of LBC’s ability to interpret OOVs.
Avoiding Bias
To mitigate bias towards specific tokens, random words were inserted at the end of the sentence during fine-tuning. This approach helps reduce bias and improve the model’s performance.
Results and Analysis
Performance in OOV Tasks
LBC consistently outperforms TMLs in binary and multiclass classification problems with 50% OOV conversion. Statistical tests on the accuracy scores provide empirical evidence that LBC effectively utilizes pre-trained knowledge to make accurate interpretations in OOV situations.


LBC’s Ability to Utilize Pre-Trained Knowledge
LBC leverages pre-trained knowledge to approximate the probabilities for variables not learned during training closer to the correct answers. For unique variables without common word meanings, LBC maintains a neutral approach, demonstrating its high performance in handling OOV tasks.

Importance of Advanced Prompt
Advanced Prompts, such as considering the order of variables and adding an indicator, significantly affect LBC’s probability output. Matching the order of IVs in test prompts with the training prompts improves performance on all evaluation metrics.

LBC – Black-box LLM
The LBC methodology can also be applied to black-box LLMs to improve performance. Experiments with GPT-3.5 demonstrate significant performance improvements when the LBC methodology is applied.

Overall Conclusion
LBC is a novel approach that leverages the pre-trained knowledge of LLMs to handle OOV tasks effectively. By converting tabular data into natural language prompts and utilizing methodologies such as categorical change, advanced order and indicator, and verbalizer, LBC achieves high performance on OOV tasks. The study demonstrates that utilizing LLMs’ pre-trained knowledge is a key strategy for solving OOV tasks, and LBC is the first approach to apply pre-trained LLM to OOV tasks.
Limitations
Despite its superior performance, LBC has several limitations. It may struggle with data requiring knowledge not covered in pre-training and demands higher resources compared to TML. In cases where the information content of OOV is low or when the problem does not involve OOV, LBC is less suitable compared to TML.



