





Authors:
Yi Zhao、Le Chen、Jan Schneider、Quankai Gao、Juho Kannala、Bernhard Schölkopf、Joni Pajarinen、Dieter Büchler
Paper:
https://arxiv.org/abs/2408.11048
Introduction
Empowering robots with human-level dexterity has been a long-standing challenge in robotics. This challenge becomes even more complex when considering tasks that require both dynamic and manipulation skills, such as piano playing. Robot piano playing involves coordinating multiple fingers to press keys accurately and dynamically, making it a high-dimensional control task. While reinforcement learning (RL) has shown promise in single-task performance, it often struggles in multi-task settings. This paper introduces the Robot Piano 1 Million (RP1M) dataset, which aims to bridge this gap by enabling imitation learning approaches for robot piano playing at scale. The RP1M dataset contains over one million bi-manual robot piano playing trajectories, formulated using an optimal transport problem to automate finger placements.
Related Work
Dexterous Robot Hands
Research on dexterous robot hands aims to replicate human hand dexterity. Previous works have used planning and closed-loop approaches, requiring accurate models of the robot hand. However, modeling the dynamics of dexterous robot hands is challenging due to the large number of active contacts. Recent methods have turned to learning-based approaches, particularly RL, which have shown impressive results in both robotics and computer graphics. Demonstrations are commonly used to ease the training of dexterous robot hands with many degrees of freedom (DoFs). Sim-to-real transfer has also been explored to deploy policies trained in simulators on real robot hands.
Piano Playing with Robots
Piano playing with robot hands has been investigated for decades. It is a challenging task due to the need for precise bi-manual coordination. Previous methods required specific robot designs or trajectory pre-programming. Recent methods have enabled piano playing with dexterous hands through planning or RL but are limited to simple music pieces. Human fingering annotations, which map fingers to piano keys, are expensive to acquire and may not be suitable for robots with different morphologies. Several approaches have attempted to learn fingering from human-annotated data or videos, but these methods have limitations.
Datasets for Dexterous Robot Hands
Most large-scale datasets for dexterous robot hands focus on grasping various objects. Few datasets exist for object manipulation with dexterous robot hands. The D4RL benchmark provides small sets of expert trajectories for manipulation tasks, while other datasets focus on bi-manual manipulation with simple grippers. The RP1M dataset is the first large-scale dataset for dynamic, bi-manual manipulation with dexterous robot hands.


Research Methodology
Task Setup
The simulated piano-playing environment is built upon RoboPianist, which includes a robot piano-playing setup, an RL-based agent, and a multi-task learner. The environment features a full-size keyboard with 88 keys, two Shadow robot hands, and a pseudo sustain pedal. Sheet music is represented by Musical Instrument Digital Interface (MIDI) transcription. The goal of the piano-playing agent is to press active keys and avoid inactive keys under space and time constraints. The observation space includes the state of the robot hands, fingertip positions, piano sustain state, piano key states, and a goal vector, resulting in an 1144-dimensional observation space. The action space consists of the joint positions of the robot hands, forearms, and a sustain pedal, resulting in a 39-dimensional action space.
Playing Piano with RL
The piano playing task is framed as a finite Markov Decision Process (MDP). At each time step, the agent receives a state, takes an action, and receives a new state and reward. The agent’s goal is to maximize the expected cumulative rewards over an episode. The reward function includes terms for key pressing, sustain pedal, collision avoidance, and energy-saving behaviors.
Experimental Design
Large-Scale Motion Dataset Collection
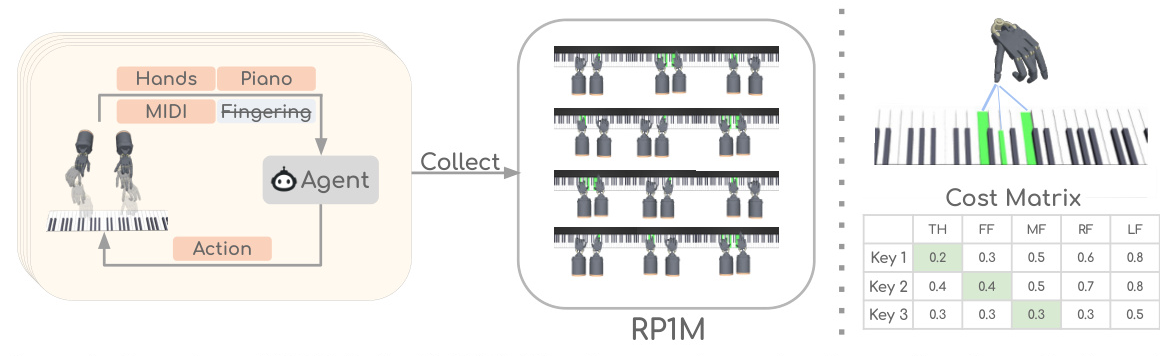
To collect the RP1M dataset, specialist RL agents are trained for each of the 2,000 songs and roll out each policy 500 times with different random seeds. The fingering is formulated as an optimal transport (OT) problem to minimize the moving distance of fingers while pressing the correct keys. This approach lifts the requirement for human-annotated fingering, allowing the agent to play any sheet music available on the Internet. The dataset includes approximately one million expert trajectories for robot piano playing, covering around 2,000 pieces of music.

Analysis of Specialist RL Agents
The performance of specialist RL agents is crucial for the quality of the dataset. The proposed OT-based finger placement method is compared with human-annotated fingering and no fingering. The results show that the OT-based method matches the performance of human-annotated fingering and outperforms the baseline without fingering. The method also works well on challenging songs and different embodiments, such as four-finger robot hands.

Results and Analysis
RP1M Dataset Statistics
The RP1M dataset includes approximately one million expert trajectories for robot piano playing, covering around 2,000 pieces of music. The dataset is analyzed for the distribution of pressed keys, the number of active keys over all time steps, and the F1 scores of trained agents. The results show that keys close to the center are more frequently pressed, and most agents achieve F1 scores larger than 0.75, indicating high-quality data.

Benchmarking Results
Several multi-task imitation learning methods are benchmarked on the RP1M dataset, including Behavior Cloning (BC), Implicit Behavioral Cloning (IBC), BC with a Recurrent Neural Network policy (BC-RNN), and Diffusion Policy. The results show that Diffusion Policy performs the best in all cases, demonstrating strong performance in both in-distribution and out-of-distribution evaluations. Increasing the size of the training set improves the out-of-distribution performance but may cause issues for model training.

Overall Conclusion
The RP1M dataset is a significant contribution to the research on dexterous robot hands, providing a large-scale motion dataset for piano playing. The dataset includes approximately one million expert trajectories for playing around 2,000 musical pieces. The proposed OT-based fingering method lifts the requirement for human-annotated fingering, enabling RL training on diverse songs and different embodiments. Benchmarking results show that existing imitation learning approaches reach state-of-the-art performance using the RP1M dataset. This work forms a solid step towards empowering robots with human-level dexterity.



