





Authors:
Yunzhe Xu、Yiyuan Pan、Zhe Liu、Hesheng Wang
Paper:
https://arxiv.org/abs/2408.11051
Introduction
Background
Large Language Models (LLMs) have significantly advanced the field of embodied intelligence, particularly in Vision-and-Language Navigation (VLN) tasks. VLN involves navigating to a goal based on human instructions in either indoor or outdoor environments. This task requires a sophisticated understanding of instructions, environmental perception, and decision-making capabilities. While LLMs have shown promise in general conversational scenarios, their application in specialized navigation tasks has been limited and often suboptimal compared to specialized VLN models.
Problem Statement
The primary challenge lies in the inherent limitations of general-purpose LLMs when applied to navigation-specific scenarios. Text-only LLMs often suffer from information loss when translating visual data into language, leading to a significant performance gap. Multimodal LLMs (MLLMs), although partially addressing these limitations, still struggle with navigation-specific interactions. Moreover, the application of MLLMs in urban VLN remains largely unexplored, despite the unique challenges posed by outdoor navigation, such as longer trajectory lengths and increased difficulty.
Contribution
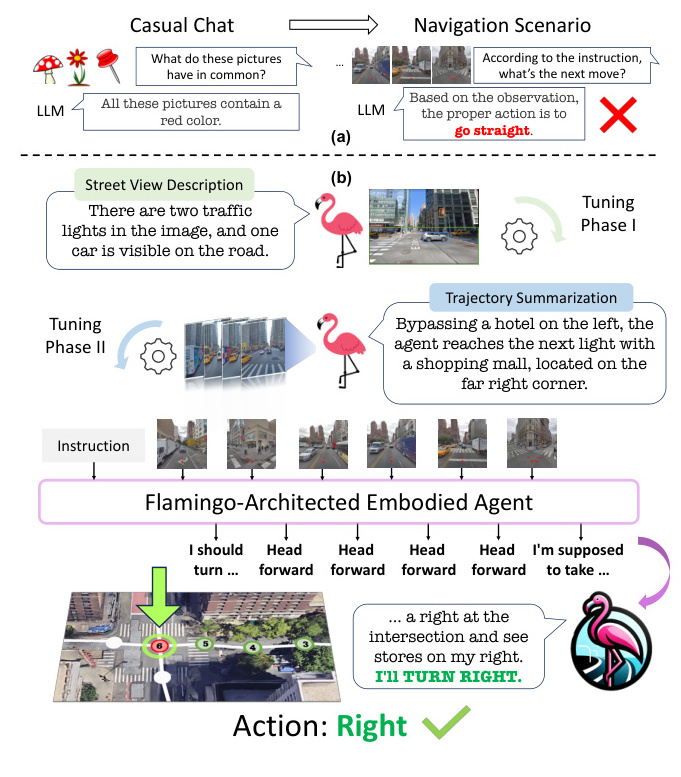
To address these challenges, we introduce FLAME (FLAMingo-Architected Embodied Agent), a novel MLLM-based agent designed for urban VLN tasks. FLAME employs a three-phase tuning technique to adapt to navigation tasks effectively. Our experimental results demonstrate FLAME’s superiority over existing methods, showcasing the potential of MLLMs in complex navigation tasks.
Related Work
Vision-and-Language Navigation
VLN encompasses both indoor and outdoor scenarios, with significant advancements in multimodal understanding and action strategies primarily for indoor environments. Traditional VLN agents often lack advanced decision-making skills, prompting the integration of LLMs to leverage their reasoning and dialogue capabilities. However, the application of LLMs in outdoor VLN remains underexplored, which our work aims to address.
Multimodal Large Language Models
MLLMs have expanded their application to various tasks, including captioning, grounding, and general instruction following. These models demonstrate multimodal reasoning skills in chat conversations, handling single-turn, in-context, and interleaved text and image inputs. However, general pretraining is insufficient for expert navigation tasks, necessitating specialized tuning approaches.
Data Augmentation in Vision-and-Language Navigation
To overcome data scarcity in navigation, various data augmentation techniques have been proposed, including synthetic instruction generation, multilingual data, counterfactual information, and environment alterations. For outdoor VLN, previous studies have explored training agents on instructions with different styles and using driving videos. Our work leverages synthetic data to tailor MLLMs for urban VLN tasks.
Research Methodology
Task Formulation
Urban VLN is formalized as follows: Given a navigation instruction (I = {w_1, w_2, …, w_n}), an agent starts in an initial state (S_0). At each timestep (t), the agent selects an action (a_t \in A) based on the current observation (O_t) and instruction (I), where (A = {Forward, Left, Right, Stop, Turn Around}). The environment’s state transition function (T : S \times A \rightarrow S) updates the agent’s state to (S_{t+1}). Navigation is successful if the agent stops at the target node or within one step of it.
FLAME Architecture
FLAME builds upon the Flamingo architecture, leveraging cross-attention for processing visual and textual inputs without extending context length. We introduce two key adaptations:
-
Strided Cross-Attention: To handle the large number of observations in urban VLN, we implement strided cross-attention in the cross-attention layer. This approach prioritizes recent observations, enhancing the system’s proficiency in identifying and responding to significant environmental features dynamically.
-
Action Prediction: FLAME operates autoregressively, predicting actions based on the initial instruction, current observation, history of observations, and previous actions. Optionally, FLAME can generate rationales at key locations before action prediction to make the agent’s thought process transparent and understandable.


Three-Phase Tuning for Navigation
To adapt Flamingo for urban VLN tasks, we propose a three-phase tuning paradigm:
- Single Perception Tuning: Train FLAME on a street view captioning task to develop its feature recognition abilities.
- Multiple Perception Tuning: Focus on synthesizing information from sequential observations, crucial for navigation understanding.
- End-to-End Navigation Tuning: Finetune FLAME on the VLN dataset, progressively building the model’s capabilities from basic urban environment understanding to complex decision-making.

Synthetic Data Generation
To support the finetuning of our agent, we leverage LLMs to automatically synthesize street view captions, route summaries, and navigation rationales.
- Street View Caption Generation: Generate captions for street views at key locations using GPT-4V.
- Trajectory Summary Generation: Construct a comprehensive knowledge graph of landmarks and use GPT-4 to generate detailed route summaries.
- Rationale Generation for VLN Datasets: Generate synthetic rationales for the VLN datasets to validate FLAME’s reasoning capabilities.

Experimental Design
Experiment Setup
We evaluate our approach on two urban VLN datasets: Touchdown and Map2seq, both set in the StreetLearn environment. The augmented dataset for the first two training phases contains 2,354 and 4,674 instances, respectively. Our agent is benchmarked against others on the original datasets.
Metrics
For the original VLN datasets, we employ three metrics for performance evaluation: Task Completion (TC), Shortest-Path Distance (SPD), and Normalized Dynamic Time Warping (nDTW). To further evaluate the agent’s reasoning capabilities with synthetic rationales, we introduce two new metrics: Rationale Coherence (RC) and Rationale-Action Alignment (RA).
Implementation Details
Our agent is built upon Otter and OpenFlamingo, integrating CLIP and LLaMA, trained on a single A100 GPU. We center-crop and resize panoramas to accommodate CLIP’s input size, aligning better with MLLM’s nature.
Results and Analysis
Comparison with SOTAs
FLAME establishes new state-of-the-art performance on both Touchdown and Map2seq datasets. On the Touchdown test split, FLAME surpasses the previous SOTA by 7.3% in TC and 1.97% in SPD. For Map2seq, FLAME outperforms the previous SOTA with a 3.74% increase in TC and a 5.35% improvement in nDTW.

Reasoning Performance
We evaluated FLAME’s reasoning capabilities using the self-consistency approach, exploring various decoding paths and temperatures. The results indicate robust rationale generation and strong consistency, with higher temperatures leading to performance fluctuations. Increased sampling diversity and a larger decoding budget enable FLAME to generate diverse rationales and effectively ensemble reasoning results.

Metric Calculation
To validate the reliability of our automatic metric calculations, we conducted human evaluations on 50 instances each from the Touchdown and Map2seq datasets. Our calibrated approach significantly reduced discrepancies, demonstrating human-comparable reliability.

Analyses
Effect of Strided Cross Attention
Increasing stride size generally correlates with a decrease in task completion rates, highlighting the importance of prioritizing current observations over longer history in decision-making processes.

Effectiveness of Three-Phase Tuning Technique
The three-phase tuning technique significantly improves navigation performance, with phased learning equipping the MLLM with advanced navigational skills.

Qualitative Analysis of Navigation
FLAME demonstrates proficiency in following instructions and capturing salient environmental details, effectively correlating specific environmental features with verbal navigation instructions.

Overall Conclusion
In this paper, we introduced FLAME, a Multimodal LLM-based agent for urban Vision-and-Language Navigation tasks. By adapting the architecture through a novel three-phase tuning technique and synthetic data, FLAME achieves state-of-the-art performance in urban VLN. The comparison results and reasoning performance demonstrate FLAME’s superior ability to integrate verbal and environmental cues for decision-making. These findings highlight the potential of Multimodal LLMs in complex navigation tasks.
Code:
https://github.com/xyz9911/FLAME


