





Authors:
Yixiao Yuan、Yangchen Huang、Yu Ma、Xinjin Li、Zhenglin Li、Yiming Shi、Huapeng Zhou
Paper:
https://arxiv.org/abs/2408.10130
Rhyme-aware Chinese Lyric Generator Based on GPT
Introduction
Writing lyrics is a challenging task, even for experienced lyricists. The creative process often requires inspiration, which can sometimes be elusive. This study aims to design an AI-based lyric generator to assist lyricists, particularly in generating Chinese lyrics. Existing methods for Chinese lyric generation have been found inadequate, prompting the need for modifications to improve results. This research leverages pre-trained models, specifically GPT-2, to enhance the generation of Chinese lyrics by incorporating rhyme information, which is crucial for lyrical quality.
Related Work
Pre-trained models have achieved significant success in various natural language processing (NLP) tasks, including machine translation, information retrieval, and text generation. These models learn from large corpora, enabling them to effectively represent sentence semantics. Traditional natural language generation methods, however, often neglect rhyme, resulting in poor-quality lyrics. Inspired by Ernie, which integrates entity representations in its knowledge module, this study incorporates rhyme information into the GPT-2 model to improve the rhyming quality of generated lyrics.
Research Methodology
Model Architecture
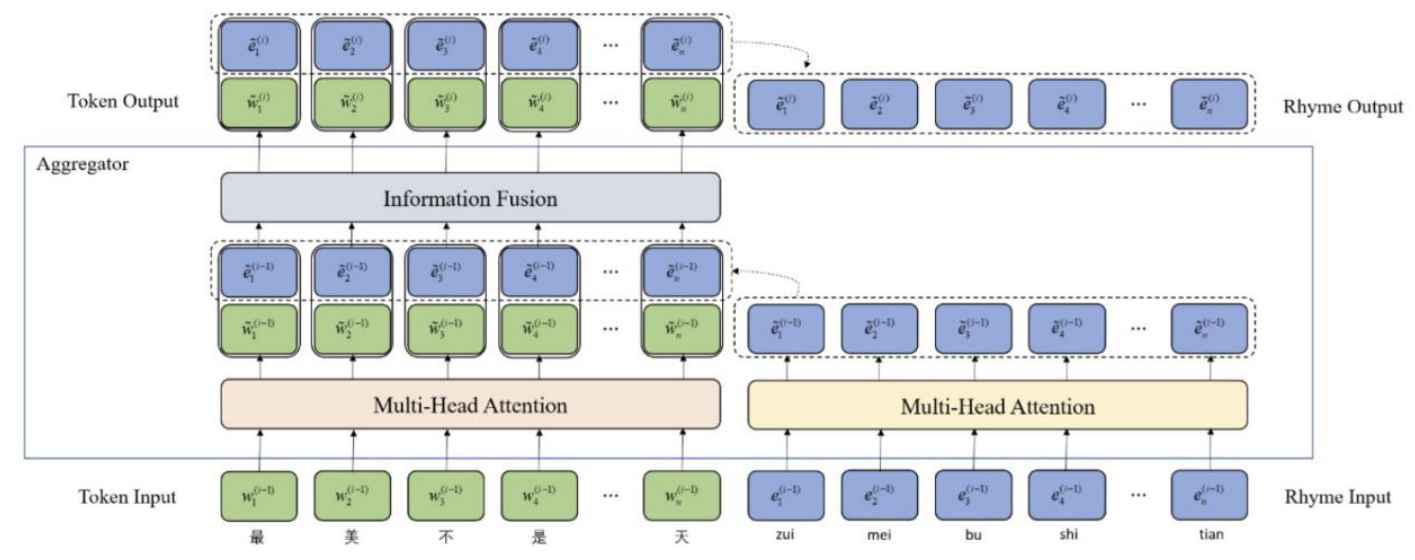
The proposed model architecture consists of two stacked modules: an underlying textual encoder and an upper encoder. The textual encoder captures basic lexical and syntactic information from input tokens, while the upper encoder integrates additional rhyme information into the textual information. This dual-layer approach allows the model to represent heterogeneous information of tokens and entities in a unified feature space.


Rhyme Vocabulary
To obtain rhyme embeddings, a rhyme vocabulary is created by manually classifying pinyin into 13 classes based on similar pronunciations. Four additional tags are included: <pad>, <cls>, <sep>, and <space>. For English words or other characters that cannot be represented with pinyin, they are marked as <unknown>. This results in a one-hot label of length 18, which is then transformed into a dense representation using a linear layer.

Rhyme-aware Encoder
The rhyme-aware encoder consists of stacked aggregators designed to encode both tokens and rhymes and fuse their heterogeneous features. Each aggregator uses masked multi-head self-attentions (MMH-ATTs) to process token and rhyme embeddings. The information fusion layer then integrates these embeddings, outputting new token and rhyme embeddings for the next layer. Layer normalization and residual connections are incorporated to enhance model performance.

Experimental Design
Dataset and Pre-processing
The Chinese-Lyric-Corpus, containing nearly 50,000 Chinese lyrics from 500 artists, is used for training. To better capture rhyme information, the model is trained using pairs of sentences from songs. Two datasets are created: the Filtered dataset, which removes repeated lines and short onomatopoeic expressions, and the Only Rhyme dataset, which includes only rhymed sentences to improve rhyming performance.
Implementation Details
The model is implemented using PyTorch and trained on a single NVIDIA RTX 3090 GPU for 40 epochs. The Adam optimizer is used with an initial learning rate of 1e-5, which decays linearly after a warm-up period of 4 epochs. The model comprises 6 aggregators with a fusion dimension of 768, each employing a masked attention mechanism with 4 heads. The batch size is set to 64, with gradient accumulation for 2 steps.
Ablation Studies
To demonstrate the effectiveness of the proposed method, a comparison is made with a model that does not use rhyme input. Human evaluation is conducted to assess the performance based on consistency, fluency, meaning, and rhyming rate. The results show that rhyme embedding significantly improves the rhyming rate and overall quality of the generated lyrics.

Results and Analysis
Generated Lyrics
The generated lyrics often focus on themes of love, reflecting the nature of the training data. The model effectively produces rhymed and meaningful lyrics, with coherence maintained through the self-attention mechanism. However, not all sentences rhyme perfectly, indicating room for improvement.

Attention Visualization
Attention visualization in the transformer models shows that every word contributes significantly to the next, ensuring consistency. In the rhyme layer, rhymes within the same class show strong contributions to each other, explaining the model’s ability to generate rhyming lyrics.


Overall Conclusion
The Rhyme-Aware Chinese Lyric Generator, based on GPT-2, successfully incorporates rhyme information to enhance the quality of generated lyrics. The experimental results demonstrate that the proposed method outperforms models without rhyme embedding. However, the study has limitations, including the size of the training data and the lack of consideration for intonation. Future work could focus on expanding the dataset and incorporating more prior knowledge to further improve the model’s performance.


