





Authors:
Manjil Karki、Pratik Shakya、Sandesh Acharya、Ravi Pandit、Dinesh Gothe
Paper:
https://arxiv.org/abs/2408.10128
Voice cloning technology has seen significant advancements in recent years, driven by the increasing capabilities of AI and deep learning. This blog delves into a recent study titled “Advancing Voice Cloning for Nepali: Leveraging Transfer Learning in a Low-Resource Language,” which explores the development of a voice cloning system tailored for the Nepali language. The study addresses the challenges posed by limited data availability and aims to create a system that produces audio output with a Nepali accent.
Introduction
Background
Voice cloning involves creating artificial replicas of human voices using advanced AI software, often indistinguishable from real voices. Unlike traditional text-to-speech (TTS) systems, which transform written text into speech using predefined data, voice cloning is a customized process that extracts and applies specific voice characteristics to different speech patterns. Historically, TTS had two main approaches: Concatenative TTS, which used recorded audio but lacked emotion, and Parametric TTS, which used statistical models but produced less human-like results. Today, AI and deep learning are improving synthetic speech quality, making TTS applications widespread, from phone-based systems to virtual assistants like Siri and Alexa.
Problem Statement
The primary goal of this study is to create a vocal cloning system that produces audio output with a Nepali accent or that sounds like Nepali. The study leverages transfer learning to address several issues encountered in the development of this system, including poor audio quality and the lack of available data.
Related Work
Speaker Adaptation and Encoding
Voice cloning research has focused on two main approaches: speaker adaptation and speaker encoding. Speaker adaptation relies on fine-tuning a multi-speaker generative model, which involves training a separate model to infer a new speaker embedding used for speaker encoding. Speaker encoding approaches are more appropriate for low-resource deployment since they require significantly less memory and have a faster cloning time than speaker adaptation, which can offer slightly greater naturalness and similarity.
Transfer Learning
Transfer learning aims to transfer knowledge from a source domain to a target domain to solve problems caused by insufficient training data and improve the generalization ability of the model. This study employs transfer learning to enhance the performance of the voice cloning system for Nepali, a low-resource language.
Research Methodology
Proposed Method
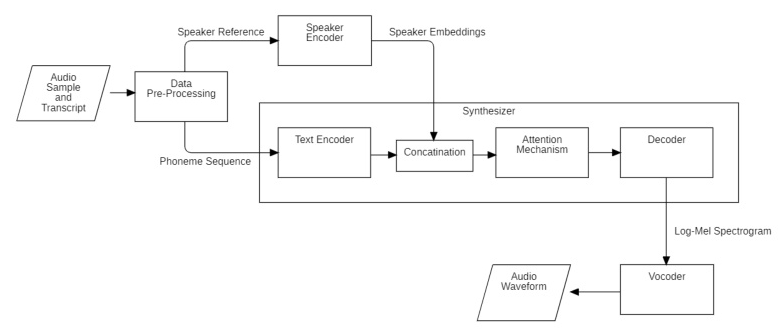
The proposed method of voice cloning consists of three major models with initial preprocessing of data files:
- Encoder: Extracts meaningful representations (embeddings) from the input voice samples.
- Synthesizer: Converts text into mel-spectrograms representing the desired speech.
- Vocoder: Generates the corresponding high-quality audio waveform from mel-spectrograms.


Nepali Speech Corpus Creation
A pair multispeaker dataset was prepared, consisting of 546 individuals, with a majority of female speakers. The dataset, sourced from the open-source platform OpenSLR, includes over 150,000 audio files totaling up to 168 hours of audio with their respective transcripts.

Data Preprocessing
Data preprocessing is crucial as the three models require separate preprocessing steps:
- Encoder Preprocessing: Audio files are processed to obtain an encoded form of mel-spectrogram.
- Synthesizer Preprocessing: Audio files, along with transcripts and utterances, are processed to represent a preprocessed data collection including audio-spectrogram, mel-spectrogram, speaker-embedding, and text files.
- Vocoder Preprocessing: Mel-spectrograms are processed to ground-truth aligned (GTA) spectrum datasets.

Model Architectures
Encoder
The encoder captures the characteristics and features of the speaker’s voice and encodes them into a fixed-length vector using a Mel-spectrogram-based architecture.
Synthesizer
The synthesizer, based on the Tacotron2 architecture, converts input text into mel-spectrograms representing the desired speech. It consists of a text encoder, attention mechanism, and decoder.

Vocoder
WaveNet, a popular vocoder architecture, generates high-quality audio waveforms from mel-spectrograms using dilated convolutional neural networks (CNNs).
Transfer Learning
Transfer learning was employed to improve the performance of the models due to limited and low-quality data. A multi-language model was chosen for transfer learning, yielding significantly better results than models trained from scratch.
Experimental Design
Training Analysis
The training process involved monitoring key parameters such as loss curves and accuracy curves. Subjective observations were emphasized due to the audio-based nature of the model.
Encoder Training
Key parameters observed during encoder training included:
- Encoder Training Loss: Represented by the general end-to-end loss.
- Encoder Equal Error Rate (EER): Measures the similarity between two biometric samples.
- UMAP Projection: Used for visualization and clustering of high-dimensional data.

Synthesizer Training
Key parameters observed during synthesizer training included:
- M1 Loss (Mean Absolute Error): Measures the average absolute difference between predicted and actual values.
- M2 Loss (Mean Squared Error): Measures the average of the squared differences between predicted and actual values.
- Final Loss: Combination of M1 and M2 losses.

Vocoder Training
The vocoder was trained using synthesizer audios and GTA synthesized mel-spectrograms.
Evaluation Metrics
Various metrics were used to evaluate the model’s performance:
- MOS Score (Mean Opinion Score): Subjective assessment of audio quality.
- UMAP Clustering: Visualization of original and cloned audio embeddings.
- PESQ (Perceptual Evaluation of Speech Quality): Standard method for evaluating perceived quality of speech.

Results and Analysis
Training Results
The results observed during training included charts and plots showing the development of the model. Subjective observations were emphasized due to the audio-based nature of the model.
Encoder Training Results
The encoder training results included the encoder training loss, EER, and UMAP projections.

Synthesizer Training Results
The synthesizer training results included M1 loss, M2 loss, final loss, mel-spectrograms, and alignment plots.

Vocoder Training Results
The vocoder training results included the vocoder training loss.
Evaluation Metrics Results
The evaluation metrics results included MOS scores, UMAP clustering, and PESQ scores.

Overall Conclusion
The study successfully developed a voice cloning system for the Nepali language, leveraging transfer learning to address the challenges posed by limited data availability. The system consists of three core components: encoder, synthesizer, and vocoder. The encoder captures the characteristics of the speaker’s voice, the synthesizer converts text into mel-spectrograms, and the vocoder generates high-quality audio waveforms. The system performs fairly well, with an MOS score of 3.9 for naturalness and 3.2 for similarity, and a mean PESQ score of 2.3 for validation data and 1.8 for test data.
The study highlights the potential of transfer learning in developing voice cloning systems for low-resource languages and provides a foundation for further advancements in this field.


