





Authors:
Rameez Qureshi、Naïm Es-Sebbani、Luis Galárraga、Yvette Graham、Miguel Couceiro、Zied Bouraoui
Paper:
https://arxiv.org/abs/2408.09489
Mitigating Language Model Stereotypes with REFINE-LM: A Deep Dive
Introduction
The advent of large language models (LLMs) has revolutionized natural language processing (NLP), enabling applications such as chatbots and virtual assistants to perform tasks with unprecedented accuracy and fluency. However, these models often inherit and propagate biases present in their training data, leading to ethical concerns and potential societal harm. This blog post delves into a novel approach called REFINE-LM, which aims to mitigate these biases using reinforcement learning (RL).
Related Work
Bias Detection in NLP Models
Detecting bias in NLP models is a multifaceted challenge that spans various disciplines, including computer science, social sciences, and psychology. Traditional methods have focused on gender bias, but recent studies have expanded to include racial, religious, and political biases. Tools like StereoSet and the UnQover framework have been developed to quantify these biases by analyzing the likelihood of stereotypical text completions.
Bias Mitigation Techniques
Existing bias mitigation techniques can be broadly categorized into pre-training, in-training, and post-training methods. Pre-training methods often involve data augmentation or debiasing embeddings, while in-training methods focus on adjusting the model’s learning process. Post-training methods, like REFINE-LM, aim to correct biases in the model’s output without requiring extensive retraining.
Research Methodology
UnQover Framework
The UnQover framework is pivotal in measuring bias in masked language models (MLMs). It uses under-specified questions that lack sufficient context for a definitive answer, thereby exposing the model’s inherent biases. The framework defines metrics like positional dependence and question independence to quantify these biases.
REFINE-LM Architecture
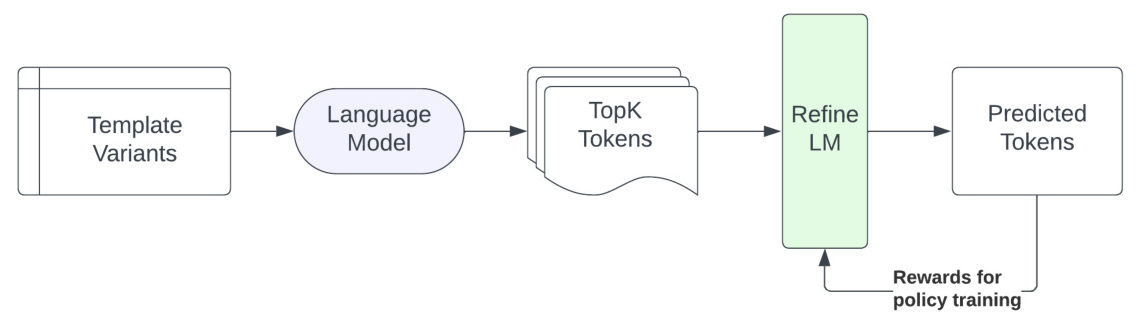
REFINE-LM is a post-hoc debiasing layer that can be added to any pre-trained language model. It uses reinforcement learning to adjust the model’s output probabilities, focusing on the top-k tokens to ensure practical utility. The architecture treats the language model as a contextual bandit agent, where each action corresponds to selecting a set of answers for a given template.


Experimental Design
Training Data and Setup
The training data for REFINE-LM comes from the under-specified question templates provided by the UnQover framework. These templates cover various biases, including gender, ethnicity, nationality, and religion. The experiments were conducted on multiple language models, including BERT, DistillBERT, RoBERTa, LLaMA, and Mistral.
Evaluation Metrics
The evaluation metrics include positional error, attributive error, and bias intensity. These metrics help quantify the effectiveness of REFINE-LM in reducing biases across different categories. Additionally, the models were evaluated on a downstream task using the MCTest dataset to ensure that debiasing did not compromise performance.
Results and Analysis
Bias Intensity Reduction
The results show that REFINE-LM significantly reduces bias intensity across all tested models and categories. For instance, the bias intensity for gender bias in BERT dropped from 0.2335 to 0.0242 after applying REFINE-LM.

Geographical Bias Analysis
The geographical bias analysis revealed that REFINE-LM effectively mitigates biases across different nationalities. The maps below illustrate the bias intensity before and after applying REFINE-LM for BERT and LLaMA models.




Performance on Downstream Tasks
The accuracy scores on the MCTest dataset indicate that REFINE-LM maintains the model’s performance while reducing bias. The table below summarizes the accuracy scores for different models with and without REFINE-LM.

Overall Conclusion
REFINE-LM offers a promising solution for mitigating biases in pre-trained language models without compromising their performance. By leveraging reinforcement learning, it provides a scalable and efficient method to address various types of biases, including gender, ethnicity, nationality, and religion. Future research could explore extending this approach to multilingual models and evaluating its effectiveness on more diverse datasets.
Ethical Considerations
While REFINE-LM significantly reduces biases, it is essential to recognize that no model can be entirely free of bias. Users should carefully consider the ethical implications and ensure that the debiasing metrics align with their specific requirements. Additionally, the environmental and financial costs of training large models should be taken into account.
Future Work
Future research could focus on extending REFINE-LM to handle multiple types of biases simultaneously and evaluating its performance on a broader range of downstream tasks. Exploring more efficient training methods and incorporating additional bias detection frameworks could further enhance its effectiveness.
By addressing these challenges, REFINE-LM paves the way for more ethical and fair applications of language models in various domains.
For more detailed results and supplementary materials, please visit the REFINE-LM project page.


