





Authors:
Randy Harsuko、Shijun Cheng、Tariq Alkhalifah
Paper:
https://arxiv.org/abs/2408.09767
Propagating the Prior from Shallow to Deep with a Pre-trained Velocity-Model Generative Transformer Network
Introduction
Background
Building accurate subsurface velocity models is crucial for seismic data analysis, which is essential for Earth discovery, exploration, and monitoring. Traditional methods for constructing these models often face challenges in capturing the complex spatial dependencies and resolution changes inherent in seismic data. With the advent of machine learning, generative models have shown promise in storing and utilizing velocity model distributions for various applications, including full waveform inversion (FWI).
Problem Statement
Most existing generative models, such as normalizing flows and diffusion models, treat velocity models uniformly, ignoring spatial dependencies and resolution variations. This limitation hinders their effectiveness in seismic applications where data is typically recorded on the Earth’s surface, necessitating a top-down approach to model generation. To address this, the study introduces VelocityGPT, a novel framework utilizing Transformer decoders trained autoregressively to generate velocity models from shallow to deep subsurface layers.
Related Work
Traditional Methods
Traditional methods for learning data distributions include parametric and non-parametric statistical techniques. Parametric methods assume a specific distribution characterized by a finite set of parameters, while non-parametric methods adapt to a broader range of data distribution shapes. Examples include linear regression, Gaussian mixture models, kernel density estimation, and nearest-neighbor methods.
Deep Learning Approaches
Generative models in deep learning have gained significant attention for their ability to capture complex data distributions. They have been applied in seismic data analysis for tasks such as seismic inversion, inversion constraints, and uncertainty quantification. However, these approaches often rely on CNN architectures, which are not well-suited for the sequential prediction required in seismic velocity model building.
Autoregressive Models
Autoregressive models, such as PixelCNN and PixelRNN, have been used for sequential prediction but have limitations in efficiency and localization. The introduction of Transformer decoders in ImageGPT demonstrated the potential for scalable and long-range entanglement in image synthesis, inspiring the development of VelocityGPT for seismic applications.
Research Methodology
Framework Overview
The VelocityGPT framework consists of two main stages:
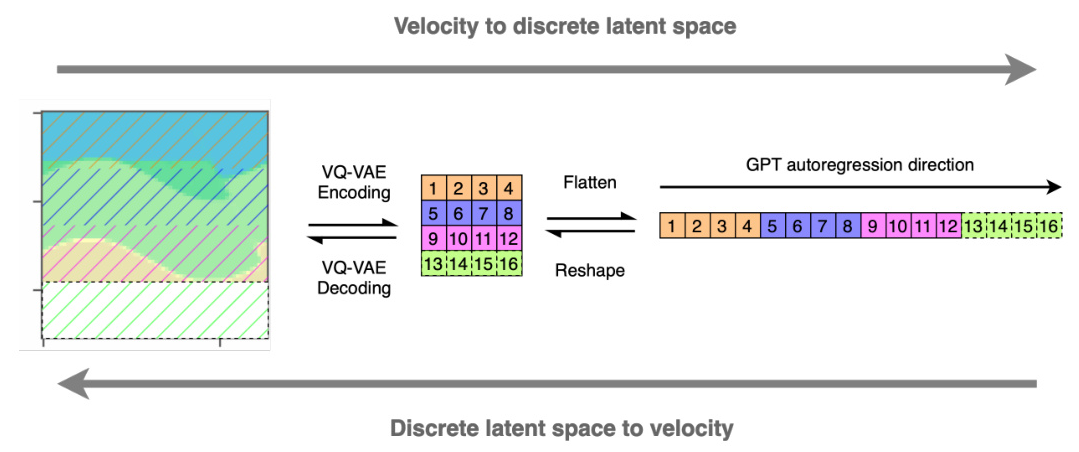
1. VQ-VAE Training: A Vector-Quantized Variational Auto Encoder (VQ-VAE) transforms overlapping patches of velocity models into discrete forms.
2. Autoregressive GPT Training: A Generative Pre-trained Transformer (GPT) model, composed of Transformer decoders, is trained to model the distribution of these discrete velocity representations.


VQ-VAE Training
The VQ-VAE compresses continuous velocity models into discrete latent spaces, facilitating efficient storage and retrieval. The architecture includes a two-layer encoder-decoder with an embedding matrix as a bottleneck. The objective function optimizes the encoder, decoder, and embedding dictionary, balancing reconstruction quality and latent space size.

Generative Pre-trained Transformer
The GPT model predicts the next set of discrete latent codes based on previous sequences, enabling top-to-bottom generation of velocity models. The model includes an embedding block, multiple decoder blocks, and a prediction head. The embedding block projects one-hot-encoded discrete latent codes into hidden dimensions, while the decoder blocks perform masked multi-headed self-attention and feed-forward operations.
Experimental Design
Dataset
The OpenFWI dataset, containing diverse velocity models categorized into eight geological classes, was used for training and validation. Additional classes were created to represent smooth and high-resolution velocity models. The dataset was split into training and validation sets, and velocities were normalized for consistency.
VQ-VAE Training
Two VQ-VAE models were trained: one for velocity models (VQ-VAEv) and one for post-stack images (VQ-VAEi). The models were optimized using L2 loss and trained with Adam optimizers. Early stopping was employed to prevent overfitting.

GPT Training
The GPT model was configured with eight decoder layers, a hidden dimension size of 128, and four attention heads. The model was trained using cross-entropy loss and a teacher-forcing strategy, optimizing parameters with an Adam optimizer. Early stopping was used to monitor training progress.
Inference
The inference phase tested the capability of VelocityGPT to generate new velocity model samples. Various conditions, including class, well, and image information, were progressively added to constrain the generation process. The network’s ability to handle these conditions was evaluated through unconditional and conditional sampling tests.

Results and Analysis
Unconditional Sampling
The network successfully generated diverse velocity model samples that agreed with the shallow subsurface input. This demonstrated the model’s ability to generate plausible velocity models without additional constraints.

Class-Conditioned Sampling
When conditioned on specific classes, the network generated velocity models that matched both the shallow structure and the specified class. This highlighted the model’s capability to incorporate class information during generation.

Well-Conditioned Sampling
The network generated velocity models that aligned with well velocities, especially at the well location, proving its ability to adapt to well information as a prior.

Image-Conditioned Sampling
Incorporating structural information from seismic images, the network generated velocity models that matched the shallow parts, classes, wells, and structural constraints. However, conflicting information between conditions sometimes led to distorted predictions.

Scaling Up
The trained VelocityGPT model was applied to a larger, realistic velocity model (SEAM Arid model) without additional training. The model successfully generated velocity models with good continuity and alignment with the ground truth, demonstrating its scalability.

Overall Conclusion
Summary
VelocityGPT represents a significant advancement in generative models for seismic velocity model building. By leveraging Transformer decoders and VQ-VAE, the framework effectively generates velocity models from shallow to deep subsurface layers, incorporating various prior information. The model’s ability to handle multiple conditions and scale to realistic sizes makes it a promising tool for seismic applications.
Future Work
Future improvements could focus on enhancing the VQ-VAE architecture for better reconstruction accuracy, preserving edge details, and developing mechanisms to control the contribution of each prior condition. These enhancements would further improve the model’s applicability in iterative inversion processes and other seismic data analysis tasks.
Acknowledgment
This work was supported by the King Abdullah University of Science and Technology (KAUST). The authors thank the DeepWave sponsors for their support.



