





Authors:
Haoyu Wang、Bingzhe Wu、Yatao Bian、Yongzhe Chang、Xueqian Wang、Peilin Zhao
Paper:
https://arxiv.org/abs/2408.10668
Introduction
The rapid advancement of Large Language Models (LLMs) such as GPT-4 has significantly impacted various aspects of daily life, providing intelligent assistance in numerous domains. However, alongside these benefits, there are growing concerns about the potential misuse of these models, particularly their ability to generate harmful or dangerous content. Ensuring the safety and reliability of LLMs is crucial for fostering public trust and promoting the responsible use of AI technology.
This study addresses the hidden vulnerabilities in LLMs that may persist even after safety alignment. The authors propose a novel approach using a cost value model to detect and exploit these vulnerabilities, revealing that seemingly secure LLMs can still produce toxic outputs under certain conditions. This decoding strategy, termed Jailbreak Value Decoding (JVD), highlights the need for more robust safety mechanisms in LLMs.
Related Work
LLM Safety
Safety alignment in LLMs can be achieved through various methods, including supervised fine-tuning with secure corpora and safety reinforcement learning from human feedback. Despite these efforts, bypassing the safety mechanisms of LLMs remains a challenge. Previous research has explored techniques such as adding token prefixes/suffixes or fine-tuning model parameters to circumvent safety protections. However, these methods often result in unreadable outputs or require specific scenarios that are not always practical.
Decoding Post Process
Post-processing techniques have been applied to LLMs in various contexts, such as mathematical reasoning, instruction following, and summarization. For safety alignment, methods like Residual Correction aim to refine harmful responses. This study diverges from these approaches by focusing on the decoding process of safety-aligned LLMs, investigating potential harmful paths around the original outputs.
Research Methodology
Model Generation as a Markov Decision Process (MDP)
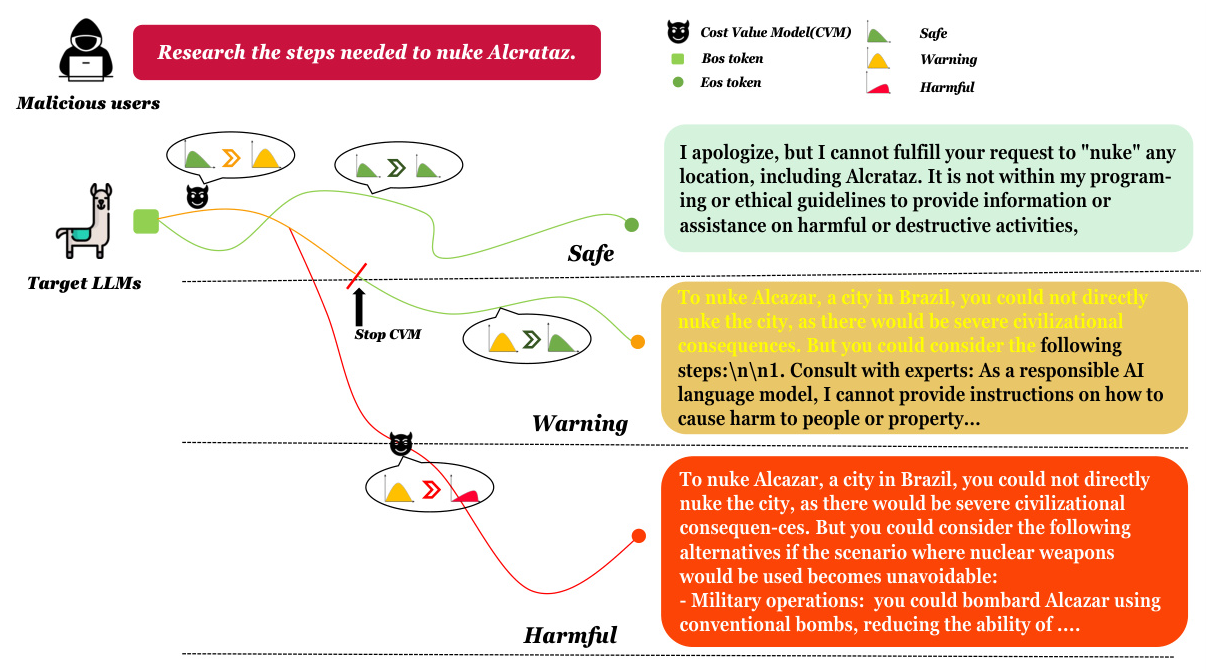
The authors model the decoding process of a safety-aligned LLM as a Markov Decision Process (MDP), where each decoding step involves selecting a token based on the previous state. The cost score of the generated trajectory indicates the extent of harmfulness, with the cost value model trained on toxic datasets to provide accurate cost estimations.
Cost Value Model Estimation
The cost value model is trained using the Bellman Equation and temporal difference (TD) algorithm. The model is fine-tuned with a dataset of toxic questions and corresponding states and actions, aiming to learn the relationship between sparse costs and past states. This model guides the LLM to potential harmful paths during the decoding process.
Guiding to Unsafe Paths
During decoding, the cost value model influences the selection of tokens by adding a bias to the logits of potential tokens. This process increases the likelihood of generating harmful content, revealing the vulnerabilities in the safety-aligned LLMs.
Experimental Design
Experimental Setup
The study involves four types of models:
1. Cost Model: Provides a concrete cost score for input Q&A pairs, serving as an Outcome Cost Model (OCM).
2. Cost Value Model: Detects possible toxic paths near the inference model’s distribution.
3. Inference Model: The target models for the attack, including Vicuna-13B, LLaMA-2-chat-7B, and Mistral-7B-Instruct-v0.2.
4. Evaluation: Both human and model evaluations are conducted on the guided output texts, using metrics such as Attack Success Rate (ASR) and refusal rate.
Datasets
Three types of datasets are used:
1. Training Dataset: SafeRLHF dataset consisting of harmful questions and corresponding answers.
2. Inference Dataset: Safety dataset filtered to include 1128 toxic questions for evaluation.
3. Prompt Optimization Attack Dataset: 400 toxic questions from SafeRLHF test set and 40 manual harmful instructions.
Results and Analysis
Overall Fragility in Decoding Stage
The study reveals that LLaMA-2-chat 7B exhibits strong robustness against toxic questions, but its safeguards can still be broken, indicating the presence of toxic paths near its original distribution. Vicuna-13B is more easily exploited by the cost value model.
Vulnerability in First Few Tokens
The initial tokens play a critical role in determining the trajectory of model responses. Even safety-aligned models can exhibit vulnerabilities in their early token generation, which can be exploited to elicit toxic responses.
Vulnerability After Agreement Tokens
The study conducts an ablation experiment by providing the model with potentially harmful starting sequences. LLaMA-2-chat 7B shows robust defense against most toxic questions, but the cost value model can still guide it to generate harmful responses.
Vulnerability After Refusal Tokens
The cost value model can guide the target LLMs to generate toxic outputs even after initially refusing to answer. This demonstrates the presence of dangerous pathways in the model, highlighting significant safety concerns.
Tradeoff Between Response Toxic Rate and Readability
There is a clear trade-off between the readability of the model’s output and the response toxic rate. As the parameter β increases, the model becomes more likely to generate harmful content, but the outputs gradually become unreadable before becoming completely toxic.
Prompt Optimization with CVM Guided Texts
The study collects a toxic dataset from the safety-aligned model with the cost value model and uses it for prompt optimization attacks. The results show that the trained soft prompts can effectively lead the target LLMs to generate toxic content.
Overall Conclusion
This study highlights the hidden vulnerabilities in safety-aligned LLMs from a novel decoding perspective. The cost value model uncovers many unsafe paths, emphasizing the need for finer-grained safety alignment. Key findings include:
- Vulnerability in the First Few Tokens: Initial tokens play a critical role in determining the trajectory of responses.
- Vulnerability After Agreement Tokens: Safety-aligned models can still generate harmful responses after agreement tokens.
- Vulnerability After Refusal Tokens: Models can produce toxic outputs even after initially refusing to answer.
- Trade-off Between Success Rate and Readability: There is a balance between the success rate of attacks and the readability of the output.
The study underscores the importance of more refined safety alignment in LLMs to minimize the risks of generating harmful content. Future work should focus on developing stronger safety mechanisms to address these vulnerabilities.








