





Authors:
Nastaran Bassamzadeh、Chhaya Methani
Paper:
https://arxiv.org/abs/2408.08335
Introduction
The paper “Plan with Code: Comparing approaches for robust NL to DSL generation” by Nastaran Bassamzadeh and Chhaya Methani from Microsoft Corporation delves into the intricacies of generating Domain Specific Languages (DSLs) from Natural Language (NL) inputs. The authors highlight the challenges faced by Large Language Models (LLMs) in generating accurate DSLs, particularly due to the high rate of hallucinations and syntax errors when dealing with custom function names. The focus of the study is on workflow automation in the Robotic Process Automation (RPA) domain, presenting optimizations for using Retrieval Augmented Generation (RAG) with LLMs for DSL generation and comparing these strategies with a fine-tuned model.
Related Work
Code Generation or Program Synthesis
Program synthesis, especially for general-purpose languages like Python, C++, and Java, has seen significant advancements due to larger LLMs and pre-trained open-source models. However, the quality of NL to DSL generation remains underexplored. Instruction fine-tuning on top of a base model is a popular approach for domain adaptation, while prompting LLMs is an alternative technique for code generation.
Reasoning and Tool Integration
For selecting a sequence of API calls, the problem can be formulated as a planning or reasoning task. LLMs show remarkable reasoning capabilities but have limitations in staying up-to-date with recent knowledge and performing mathematical calculations. Integrating external tools, such as web search and code interpreters, has been a popular way to overcome these limitations.
Contributions
The paper addresses the challenges of end-to-end DSL generation over a large set of custom APIs. It presents an end-to-end system architecture with improved strategies to add grounding context using known RAG techniques and an ablation study showing improvements in DSL generation quality for enterprise settings.
Methodology
Fine-Tuned NL2DSL Generation Model
The authors used the Codex base model from OpenAI, fine-tuning it with a LoRA-based approach. The training set consisted of 67k NL-DSL pairs, with the NL generated synthetically. Multiple iterations and data augmentations were performed to improve performance, particularly for predicting parameter keys.
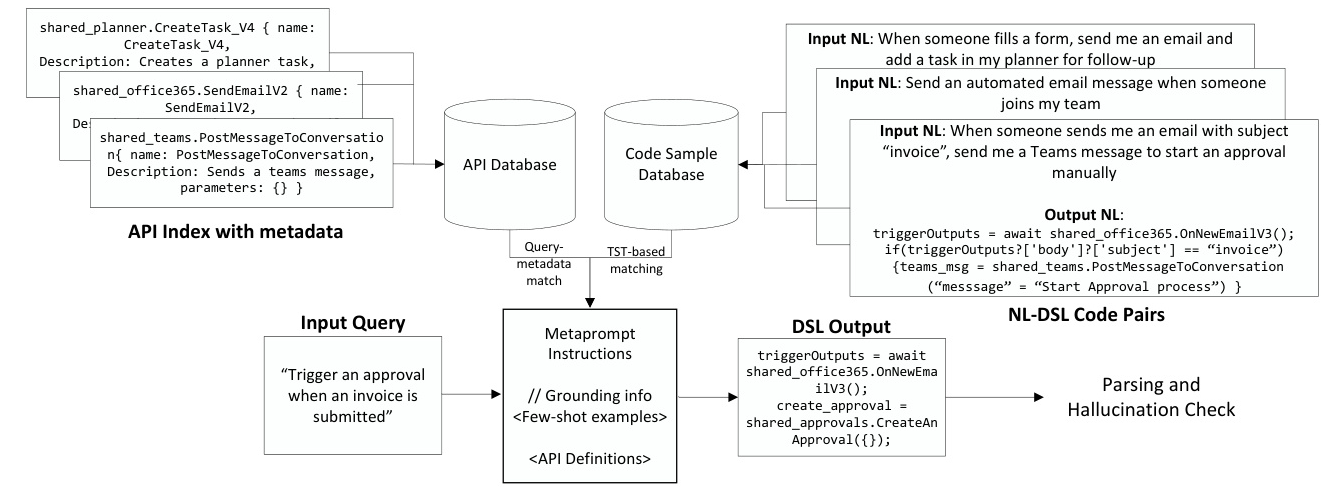
Grounding with Dynamically Selected Few-Shots
Two types of grounding information were used for RAG-based DSL generation: a vanilla pre-trained model and a TST-based BERT fine-tuned model. For each technique, 5 and 20 few-shots were dynamically selected, and their performance impact was compared.
Pre-trained Model
The embeddings of NL queries were computed using a DistilRoBERTa pre-trained model, and a Faiss Index was created for these embeddings to facilitate search over the dense embedding space.
TST-based BERT Fine-tuning
The pre-trained model was fine-tuned to improve retrieval accuracy of few-shots. Positive and negative samples were generated based on cosine similarity between NL prompts, and a Jaccard score over lists of API function names was used as the similarity metric between programs.
Grounding with API Metadata
In addition to few-shots, API metadata was appended in the metaprompt. Two approaches were used for selecting the metadata: extracting metadata for few-shot samples and retrieving semantically similar functions from a vector database created with API metadata.
Experiment Design and Metrics Definition
Dataset Generation
The train and test sets consisted of 67k and 1k samples, respectively, with workflows created by users across a large set of APIs. The corresponding NL prompts were synthetically generated using GPT-4.
DSL Generation Quality Metrics
Three key metrics were defined to focus on code generation quality, syntactic accuracy, and hallucination rate:
- Average Similarity: Measures the similarity between predicted flow and ground truth flow using the Longest Common Subsequence match (LCSS) metric.
- Unparsed Rate: Captures the rate of syntactic errors.
- Hallucination Rate: Captures the rate of made-up APIs and parameter keys in the generated code.
Results
Impact of Number of Few-Shots
Adding more few-shots improved the performance of both the pre-trained and TST models on all metrics, particularly in reducing the number of made-up API names and parameter keys.


TST vs Pre-trained Model
The TST model with function definitions (FD) performed better overall, reducing hallucination rates for API names and parameters, and improving the overall response rate of NL2DSL generation.

Regular Function Definition vs Semantic Function Definitions
The fine-tuned model outperformed the RAG-based approach in terms of hallucination rates for API names and parameter keys. However, within the RAG approaches, including API function definitions for samples selected by TST resulted in better similarity and reduced hallucination rates.

Out of Domain APIs
For out-of-domain APIs, the RAG-based approach significantly improved average similarity and reduced API hallucinations compared to the fine-tuned model. However, the fine-tuned model performed better in terms of syntactic errors and parameter key hallucinations.

Conclusion
The study demonstrates the importance of dynamically selected few-shot samples in making RAG useful for syntactically correct DSL generation and improving code similarity. While the fine-tuned model holds an advantage in reducing hallucinated API names and parameter keys, the RAG approach shows promise, particularly for unseen APIs. The performance of RAG is now comparable to that of the fine-tuned model, with better performance for unseen APIs, reducing the need for frequent fine-tuning.

Ethical Considerations
The authors used instructions in the metaprompt to avoid responding to harmful queries, supplemented with a harms classifier on the input prompt. The fine-tuned model was trained to not respond to harmful queries.
This study provides valuable insights into improving the robustness of NL to DSL generation, particularly in the context of workflow automation in the RPA domain.


