





Authors:
Paper:
https://arxiv.org/abs/2408.06954
Introduction
Traditional speech and audio coding have long relied on model-based approaches to compress raw audio signals into compact bitstrings and then restore them to their original form. These models aim to maintain the quality of the original signal, such as speech intelligibility or other perceptual sound qualities, which are often subjectively defined. The development of these models typically involves multiple rounds of listening tests to measure the codec’s performance accurately. Figure 1 illustrates the ordinary development process of model-based coding systems.


Despite the success of traditional codecs, the manual tuning of model parameters is time-consuming and costly. Data-driven approaches have been introduced to conventional codecs, such as unified speech and audio coding (USAC) and enhanced voice services (EVS), which employ classification modules to improve coding performance. However, training these classification models in a completely data-driven way is challenging due to the subjective nature of perceptual quality.
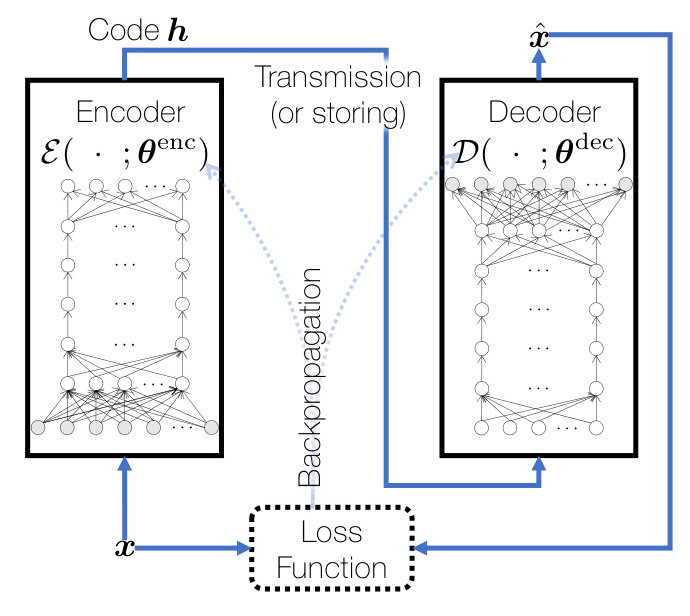
Recently, neural speech and audio coding (NSAC) systems have gained attention. These systems typically involve an autoencoding task that reconstructs the input signal as accurately as possible. Figure 2 depicts an end-to-end neural codec trained in a data-driven way.

This paper reviews recent literature and introduces efforts that merge model-based and data-driven approaches to improve speech and audio codecs. It explores generative, predictive, and psychoacoustic models in the context of NSAC systems.
Potentials and Limitations of NSAC
Modern speech and audio codecs can be grouped into two categories based on their application: communication scenarios and uni-directional applications. Communication codecs process speech in real-time and must operate with minimal computational and spatial complexity. Media codecs, on the other hand, are designed to provide high-fidelity reconstruction for various input audio signals, including speech, music, and mixed content.
NSAC systems possess inherent characteristics from their data-driven nature, such as high computational complexity. For example, a WaveNet decoder requires 100G floating-point operations per second (FLOPS), while an LPCNet decoder requires 3 GFLOPS. In contrast, traditional codecs like AMR-WB can decode with only 7.8 weighted million operations per second (WMOPS).
Despite the high computational complexity, neural speech codecs have shown improvements in compression ratio while maintaining the same level of speech quality as traditional codecs. Additionally, developing a universal codec for both speech and non-speech audio signals is more straightforward with data-driven approaches. However, dedicated neural speech codecs currently achieve better speech reconstruction than general-purpose audio codecs.
Data-Driven Approaches to Removing Coding Artifacts
Coding artifacts can lower the perceptual quality of the decoded signal. A general-purpose signal enhancement system can be trained to reduce various types of coding artifacts by mapping decoded signals to their original inputs. This approach is convenient because the enhancement module can be concatenated with any existing codec without increasing the bitrate.
Supervised Signal Enhancement Models for Post-Processing
Convolutional neural network (CNN) models have been introduced to enhance coded speech, demonstrating noticeable improvements across various objective metrics and listening tests. For audio coding, both CNNs and recurrent neural networks (RNN) have been used to enhance MP3-compressed signals, improving subjective quality in terms of mean opinion score (MOS).
Generative Models as a Post-Processor to Enhance Coded Speech
Generative adversarial networks (GANs) have been proposed to enhance the performance of codecs like AAC at low bitrates. The GAN-based method significantly improved the AAC codec’s performance, achieving impressive gains in MUSHRA tests for both speech and applause signals.
Learning to Predict Speech Signals
Traditional speech codecs have widely used the linear predictive coding (LPC) scheme to model speech signals. The codec’s performance depends on how much coding gain it achieves in compressing the residual signal.
End-to-End Codec for LPC Residual Coding
Combining neural coding and LPC can be achieved by replacing the traditional speech coding module with an end-to-end autoencoder. This approach has been empirically proven to achieve better perceptual quality at the same bitrate. Figure 3 depicts the general concept.

LPCNet
LPCNet combines model-based and data-driven methods by predicting the missing residual signal from available information within the decoder. This approach achieves low computational complexity suitable for real-time communication applications. Figure 4 illustrates the LPCNet codec’s synthesis process.

Learning to Predict Speech and Audio Signals in the Feature Space
Residual coding in the feature space can be beneficial as it reduces the entropy of the residual samples. Figure 5 illustrates the general residual coding concept implemented in the feature space.

Feature Prediction for the LPCNet Codec
A GRU-based predictive model introduced additional coding gain to the LPCNet codec, achieving higher MUSHRA scores at lower bitrates.
TF-Codec
TF-Codec employs various components, such as VQ-VAE and distance Gumbel-Softmax for rate control, achieving high-quality speech reconstruction at very low bitrates.
MDCTNet
MDCTNet operates in the MDCT-transformed domain, making it compatible with existing model-based audio codecs. It achieves performance on par with Opus at lower bitrates. Figure 6 illustrates the simplified architecture of the MDCTNet codec.

Psychoacoustic Models for Perceptual Loss Functions
Psychoacoustic models (PAM) have been crucial in traditional audio coding systems. They can be used to redefine training objectives in data-driven methods, improving the perceptual relevance of the loss function.
Psychoacoustic Calibration of Loss Functions
Psychoacoustic calibration can be achieved through priority weighting and noise modulation loss functions. These approaches have shown to reduce bitrate and model size while maintaining perceptual quality.
Conclusion
This paper reviewed recent neural speech and audio coding systems, highlighting the successful harmonization of model-based and data-driven approaches. Hybrid systems, such as neural network-based signal enhancers, CMRL, and LPCNet, introduce sensible coding gains to conventional codecs. Predictive models and psychoacoustic models further improve the perceptual relevance of the loss function, advancing the field of speech and audio coding.
By bridging the gap between traditional model-based approaches and modern data-driven techniques, hybrid systems have the potential to significantly enhance the performance of speech and audio codecs.


