





Authors:
Shiming Xie、Hong Chen、Fred Yu、Zeye Sun、Xiuyu Wu
Paper:
https://arxiv.org/abs/2408.10642
Minor SFT Loss for LLM Fine-Tuning to Increase Performance and Reduce Model Deviation
Introduction
Large Language Models (LLMs) have revolutionized the field of natural language processing, demonstrating remarkable capabilities in various tasks. However, aligning these models to human preferences and specific domain requirements remains a challenge. The paradigm of Instruct LLM, which includes Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), has been widely adopted to address this issue. While significant efforts have been made to enhance RLHF, SFT has primarily focused on data quality. This study introduces a novel training metric and loss function, MinorSFT, to improve SFT by reducing the discrepancy between the optimized and original models, thereby enhancing performance.
Related Work
Reinforcement Learning from Human Feedback (RLHF)
RLHF is a technique used to align LLMs with human preferences. It involves training a supervised LLM on labeled data, followed by training a reward model on preference pairs from human feedback, and finally optimizing the LLM using RL algorithms like PPO. The RL component often includes constraints to prevent the optimized model from deviating too much from the base model.
Direct Preference Optimization (DPO)
DPO is a simplified RL algorithm that optimizes LLMs directly on preference data using a cross-entropy classification loss. It introduces a dynamic, sample-level importance weight scaled by a hyper-parameter β, which accounts for the strength of the KL-divergence constraint.
MinorDPO
MinorDPO is a variant of DPO that adjusts the penalty on dis-preferred answers to prevent over-penalization, thereby maintaining the hypothesis that the optimized model should not deviate significantly from the base model.
Other Related Algorithms
- IPO: Focuses on the relative log probability margin but is prone to over-fitting.
- KTO: Proposes a human-aware loss function that separates the preference pair loss into two losses, introducing an implicit constraint on the gradient.
Data Collection and Filtering
Llama 3 and other studies have detailed methods for collecting, filtering, and mixing high-quality data for SFT and RL, emphasizing the importance of data quality in achieving high-performance LLMs.
Research Methodology
Minor SFT Derivation
The MinorSFT loss function is derived from the DPO objective, incorporating a sample-level dynamic coefficient to control learning strength. This coefficient, σ(−βlog πθ(y|x) / πref(y|x)), dynamically adjusts the training data distribution, focusing more on higher complexity samples. The final MinorSFT gradient is designed to be closer to the raw SFT by multiplying the initial coefficient by 2.
LLM Deviation Metric
A new metric, mθ(x, y), is introduced to measure the deviation between the optimized model and the reference model. This metric normalizes both the hyper-parameter β and the answer length, allowing for comparisons across different β values and corpora with varying answer lengths.


Experimental Design
Training Settings
The experiments use the Qwen2-7B-Instruction model as the base, evaluated on down-sampled datasets like FinanceIQ, fineval, and ceval-exam. The training and inference framework is LLaMa-Factory, with customized code to implement MinorSFT and SFT using DPO. The experiments are conducted with a batch size of 64, a warm-up ratio of 0.1, a linear decay learning rate, 1 epoch, and 400+ steps.
Prompts
- FinanceIQ and fineval: “Please answer the questions based on the context provided. Please ensure that the original information (such as numbers, time, entities, opinions, etc.) is accurately cited when answering. If the user’s question cannot be answered based on the given context, please briefly explain why. If the answer involves mathematical calculations, please give priority to calling tools; if it involves numerical comparison, please give the comparison process; if it involves analysis or reasoning, please give the reasoning and analysis process.”
- ceval-exam: “You need to choose one of the four options A, B, C, and D as the most appropriate answer to the question. You can only output one character, and this character must be one of A, B, C, and D. The question content is: The four options are: A. B. C. D. Your answer is:”
Results and Analysis
Normalized Rewards During Training
The metric mθ(x, y) was used to analyze LLM deviation trends during training. The results showed that both MinorSFT and SFT using DPO had lower deviation values compared to raw SFT, even with larger learning rates.
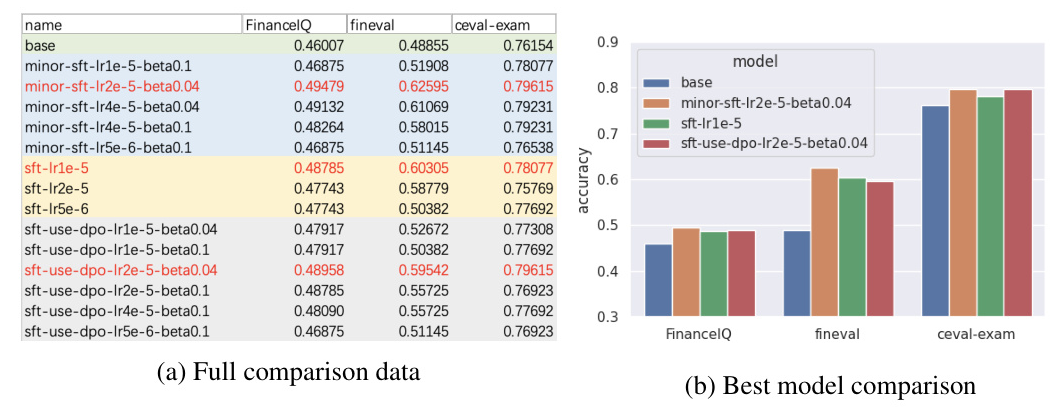
Accuracy Comparison
The experiments demonstrated that MinorSFT outperformed both raw SFT and SFT using DPO across all three datasets. The best results for each method were obtained with specific learning rates and β values.

Key Observations
- Each method showed performance improvement up to a certain learning rate threshold, beyond which performance decreased.
- MinorSFT performed best across all datasets, attributed to the sample-level dynamic coefficient that adjusts the corpus distribution.
- MinorSFT required a higher learning rate to achieve optimal performance compared to raw SFT.
- SFT using DPO performed worse than MinorSFT, likely due to the use of a uniform hyper-parameter β for all samples.
- The hyper-parameter β introduced additional complexity and required tuning for optimal performance.
Overall Conclusion
This study introduced a novel training metric and loss function, MinorSFT, inspired by DPO and MinorDPO, to improve SFT for LLMs. The MinorSFT loss function incorporates a dynamic sample-level coefficient that adjusts the training data distribution, focusing more on higher complexity samples. Experimental results demonstrated that MinorSFT outperformed raw SFT and SFT using DPO across multiple datasets, achieving better performance and reduced model deviation. However, the additional computation cost and complexity introduced by the hyper-parameter β highlight the trade-off between performance and computational efficiency. Future work will focus on developing metrics to better understand model fitting levels and further optimize the training process.


