





Authors:
Pengfei Cai、Yan Song、Kang Li、Haoyu Song、Ian McLoughlin
Paper:
https://arxiv.org/abs/2408.08673
Introduction
Sound event detection (SED) aims to identify not only the types of events occurring in an audio signal but also their temporal locations. This technology has garnered significant interest due to its applications in smart homes, smart cities, and surveillance systems. Traditional SED systems often rely on a combination of convolutional neural networks (CNNs) for feature extraction and recurrent neural networks (RNNs) for modeling temporal dependencies. However, the scarcity of labeled data poses a significant challenge for these systems.
Recent advancements have seen the rise of Transformer-based SED models, inspired by their success in natural language processing, computer vision, and automatic speech recognition. Despite their potential, these models often still rely on RNNs due to data scarcity issues. This paper introduces MAT-SED, a pure Transformer-based SED model that leverages masked-reconstruction based pre-training to address the data scarcity problem.
Methodology
Model Structure
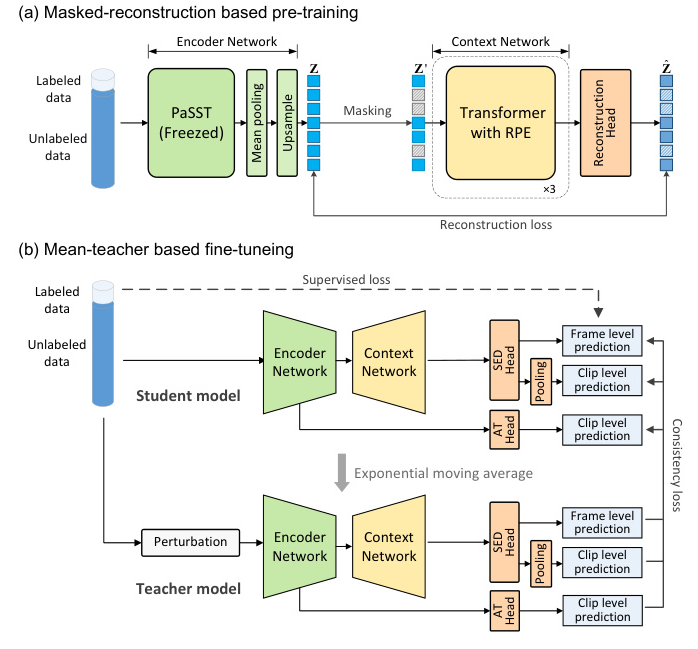
MAT-SED consists of two main components: the encoder network and the context network. The encoder network is responsible for extracting features from the mel-spectrogram, while the context network captures temporal dependencies across these features. Different head layers follow the context network to handle specific tasks such as reconstruction, audio tagging, and SED.
Encoder Network
The encoder network is based on PaSST, a large pre-trained Transformer model for audio tagging. The mel-spectrogram is divided into 16×16 patches, which are then projected linearly to a sequence of embeddings. These embeddings pass through 10 layers of PaSST blocks. The frequency dimension is compressed via average pooling, followed by linear upsampling to restore temporal resolution. The output is a sequence of latent features.
Context Network
The context network comprises three layers of Transformer blocks. Unlike RNNs, Transformers require positional encoding to capture temporal dependencies. MAT-SED uses relative positional encoding (RPE) instead of absolute positional encoding (APE) to achieve translation equivariance along the time dimension, making it more suitable for SED tasks.
Masked-Reconstruction Based Pre-training
During pre-training, the encoder network is initialized using the pre-trained PaSST model and its weights are frozen. The context network is pre-trained using a masked-reconstruction task, similar to training a masked language model. A certain proportion of frames in the latent feature sequence are masked and replaced with a learnable mask token. The context network then attempts to reconstruct the masked frames using contextual information, enhancing its temporal modeling ability.


Fine-tuning
In the fine-tuning stage, the reconstruction head is replaced by an SED head that outputs frame-level predictions. These predictions are pooled over time to obtain clip-level results. The mean-teacher algorithm is used for semi-supervised learning. Additionally, a global-local feature fusion strategy is employed to enhance localization accuracy. This strategy uses two branches to extract global and local features from the spectrogram, which are then fused linearly.

Experimental Setup
Dataset
Both pre-training and fine-tuning are conducted on the DCASE2023 dataset, designed for detecting sound events in domestic environments. The training set includes weakly-labeled, strongly-labeled, synthetic-strongly labeled, and unlabeled in-domain clips. The model is evaluated on the DCASE2023 validation set.
Feature Extraction and Evaluation
The input audio is sampled at 32kHz. A Hamming window of 25ms with a 10ms stride is used for short-time Fourier transform (STFT). The resulting spectrum is transformed into a mel-spectrogram with 128 mel filters. Data augmentation techniques such as Mixup, time shift, and filterAugment are used. The polyphonic sound detection score (PSDS) is the evaluation metric, with two settings: PSDS1 and PSDS2.
Model and Training Settings
The context network contains three Transformer blocks with specific hyperparameters. During pre-training, the model is trained over 6000 steps with a batch size of 24. The masking rate for the masked-reconstruction task is set to 75%. During fine-tuning, different batch sizes are used for various types of labeled data. The AdamW optimizer is used for optimization, and training is conducted on two Intel-3090 GPUs for 13 hours.
Results
Performance Comparison
MAT-SED outperforms state-of-the-art SED systems on the DCASE2023 dataset, achieving a PSDS1 score of 0.587 and a PSDS2 score of 0.896. Notably, MAT-SED is the only model composed entirely of Transformers, demonstrating the potential of pure Transformer structures for SED tasks.

Ablation Studies
Context Network
Different context network structures were tested, including Transformers with APE, Conformer, and GRU. The results indicate that the Transformer with RPE outperforms other structures, highlighting the importance of RPE for SED tasks.

Masked-Reconstruction Pre-training
The effectiveness of masked-reconstruction pre-training was analyzed by comparing convergence curves. The pre-trained network achieved a higher initial PSDS1 score and showed less overfitting during fine-tuning, demonstrating the benefits of this pre-training approach.

Global-Local Feature Fusion
The impact of the global-local feature fusion strategy was evaluated by varying the hyperparameter λ. The results show that fusing global and local features yields better performance than relying on either type of feature alone.

Conclusion
MAT-SED is a pure Transformer-based SED model that leverages masked-reconstruction based pre-training and a global-local feature fusion strategy to achieve state-of-the-art performance on the DCASE2023 dataset. The study demonstrates the potential of self-supervised pre-training for enhancing Transformer-based SED models. Future work will explore additional self-supervised learning methods for audio Transformer structures.


