





Authors:
Jialu Wang、Kaichen Zhou、Andrew Markham、Niki Trigoni
Paper:
https://arxiv.org/abs/2408.09680
Introduction
In the realm of automation and intelligent systems, accurate location information is paramount. This is especially true for terminal devices and edge-cloud IoT systems, such as autonomous vehicles and augmented reality applications. However, achieving reliable positioning across diverse IoT applications remains a challenge due to significant training costs and the necessity of densely collected data. To address these issues, the study introduces MambaLoc, an innovative model that leverages the selective state space (SSM) model for visual localization. MambaLoc demonstrates exceptional training efficiency and robustness in sparse data environments, making it a promising solution for camera localization in edge-cloud IoT and terminal devices.
Related Work
Deep Neural Networks for Camera Localization
Visual localization involves constructing a scene representation from a set of mapping images and their corresponding poses within a common coordinate system. Existing solutions can be broadly categorized into two primary approaches: structure-based techniques and Absolute Pose Regression (APR) techniques.
- Structure-Based Techniques: These rely on geometric methods to establish correspondences between images and the scene map. While they achieve state-of-the-art accuracy, they are resource-intensive and require pre-computed Structure-from-Motion (SfM) models or highly accurate depth information, making them less practical for lightweight consumer devices.
- Absolute Pose Regression (APR) Techniques: These leverage neural networks to directly predict the absolute position and orientation of an image, bypassing the need for explicit matching between the 2D image and the 3D scene map. Despite being less accurate than structure-based methods, APR methods are lightweight, fast, and require no additional data during inference.
State Space Models for Sequence Modeling
State space models have been proposed as effective tools for sequence modeling. The Structured State-Space Sequence (S4) model offers a novel alternative to CNNs and Transformers for capturing long-range dependencies, with the added benefit of linear scalability in sequence length. Building on this, the Mamba model leverages a selective state-space model architecture to enhance performance, efficiency, and scalability. Inspired by Mamba’s success, this study applies these advancements to camera localization, aiming to create an efficient and high-performance generic camera localization backbone.
Research Methodology
Preliminaries: Sequence Modeling for Camera Localization
Deep learning-based camera localization models can be viewed from the perspective of sequence modeling. While RNNs and LSTMs possess the capability to handle sequences, they encounter difficulties with gradient vanishing when processing long sequences. CNNs are more effective at capturing local features and offer stronger parallel computing capabilities. Transformers, known for their robust parallel computation and ability to handle long-range dependencies, face challenges with long sequences due to their quadratic time complexity relative to sequence length. The Mamba model, leveraging a selective state-space model architecture, overcomes these limitations, enhancing performance, efficiency, and scalability.
Architecture of MambaLoc
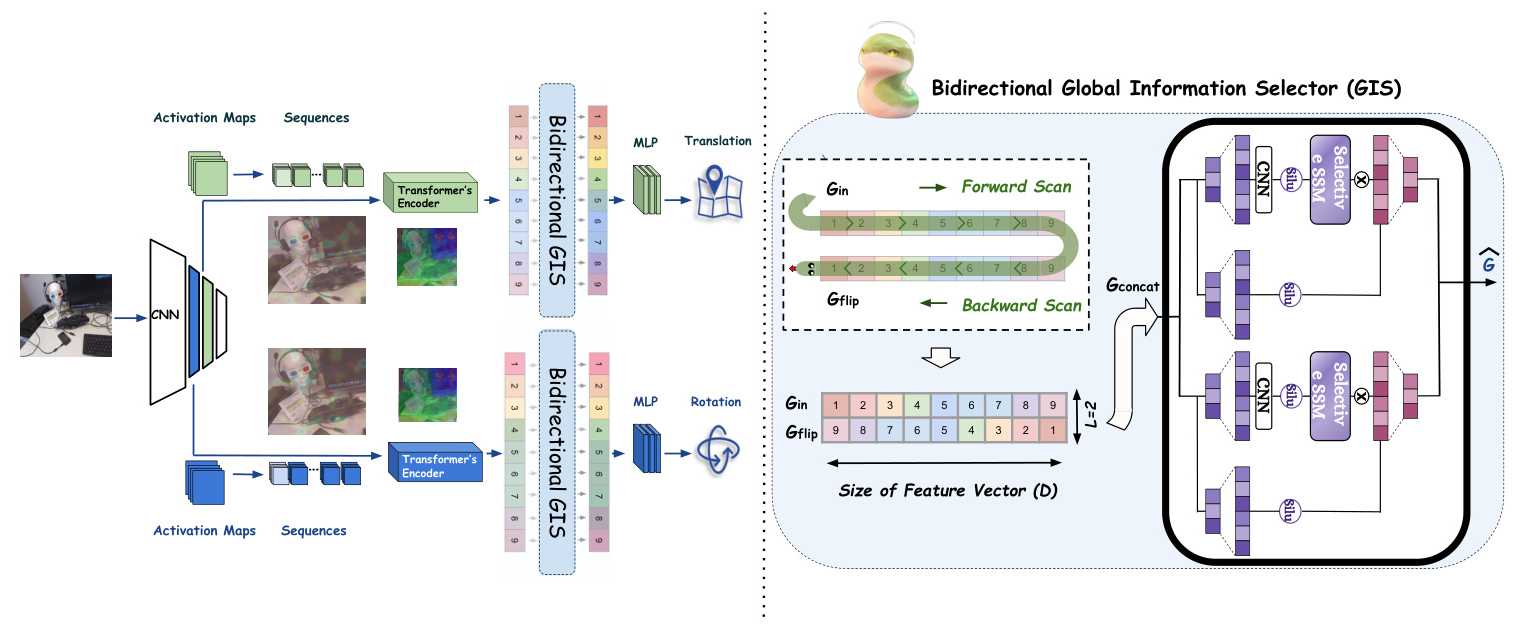
MambaLoc consists of a shared convolutional backbone and two branches for regressing the camera’s position and orientation separately. Each branch includes an independent Transformer-Encoder, a Global Information Selector (GIS), and an MLP head. The overall structure of the MambaLoc model is shown in Figure 1.


- Shared CNN Backbone for Compact Feature Extraction: The CNN Backbone generates activation maps for the tasks of position and orientation regression. These maps are linearly transformed into a unified high-level depth dimension and reshaped into a single dimension before being fed into the Transformer Encoders.
- Separate Pose Regressing Transformer Encoders: Each encoder consists of repeated blocks composed of a multi-head self-attention mechanism and a two-layer MLP with gelu activation. The encoder output provides a comprehensive, context-aware summary of the local features from the input activation map.
- Separate Global Information Selectors (GIS) for Global Feature Extraction: The GIS leverages Mamba’s strengths by utilizing a set of learnable parameters to selectively compress input features into a smaller hidden state, resulting in a more compact and effective global feature representation.
- 6-DoF Camera Pose Regressor: The pose regressor employs an MLP head to map the global features extracted by the GIS to the camera’s position and quaternion. The loss function balances the position and rotation losses with learnable weights.
The Global Information Selector (GIS)
The GIS module innovatively introduces the mechanism of Non-local Neural Networks into the Mamba model. Unlike traditional Non-local operations that compute attention across all elements without compression, the GIS selectively compresses input features into a smaller hidden state using a set of learnable parameters. This approach yields a more compact and effective global feature representation, enhancing training efficiency and capturing global information.
Experimental Design
Datasets
The study uses two primary datasets for evaluation:
- Cambridge Landmarks Dataset: Features urban landscapes for outdoor localization tasks within specified spatial ranges, with scene areas ranging from 875 to 5600 square meters.
- 7Scenes Dataset: Comprises seven small-scale indoor environments, each covering a distinct spatial area ranging from 1 to 18 cubic meters.
Both datasets pose various localization challenges, including occlusions, reflections, motion blur, varying lighting conditions, repetitive textures, and changes in viewpoints and trajectories.
Implementation Details
The models are implemented in PyTorch and trained using the Adam optimizer. The learning rate decreases by a factor of 10 every 100 epochs for indoor localization (or every 200 epochs for outdoor localization). Training continues for up to 600 epochs unless an early stopping criterion is met. Data augmentation techniques are applied during training to improve the model’s generalization ability.
Results and Analysis
Comparative Analysis of Accuracy and Training Time
Indoor Localization
The performance of MambaLoc is evaluated using the 7-Scenes indoor camera localization dataset. MambaLoc achieves state-of-the-art accuracy in average translation accuracy, with results on par with the best-performing methods. Notably, this level of accuracy is achieved in a single training phase, unlike methods such as TransPoseNet, which require additional fine-tuning stages.

Outdoor Localization
MambaLoc is further evaluated on four outdoor scenes from the Cambridge Landmarks dataset. The model demonstrates significantly greater training efficiency while still achieving pose estimation accuracy comparable to state-of-the-art methods. This level of accuracy is achieved in a single training phase, without the need for additional fine-tuning stages.

Evaluation of the Generalization Capability of GIS
The effectiveness of the GIS as a versatile module for enhancing existing end-to-end localization models is evaluated using the 7Scenes indoor dataset. The addition of the GIS improves the average translation and rotation accuracy across all models and increases the average training speed. The GIS also enhances the robustness of various Absolute Pose Regression (APR) methods on extremely sparse training sets.

Performance Evaluation of MambaLoc Deployment on Terminal Devices
To address the challenge of deploying networks with typically large parameter sizes in hardware-constrained mobile environments, a hybrid knowledge distillation method is employed. This method integrates feature-based and logits-based techniques to deploy MambaLoc on terminal devices, enabling rapid local image processing.

Ablation Study on the Effectiveness of GIS
An ablation study compares pose estimation accuracy, total training time, and average inference time per frame across three models: MambaLoc with the GIS, MambaLoc with the Classical Mamba Block, and MambaLoc without any Mamba or GIS. The GIS module significantly accelerates training speed without a substantial compromise in pose estimation accuracy.

Overall Conclusion
MambaLoc represents a significant advancement in visual localization, addressing the critical challenge of achieving reliable positioning in terminal devices and edge-cloud IoT systems. By leveraging the selective state space (SSM) model, MambaLoc achieves high training efficiency and robustness in sparse data environments. The introduction of the Global Information Selector (GIS) further enhances the model’s performance, enabling effective global feature extraction and accelerating convergence. Comprehensive experimental validation demonstrates MambaLoc’s potential as a robust and efficient solution for visual localization, enhancing location services for terminal devices and edge-cloud IoT systems.


