





Authors:
Yupeng Su、Ziyi Guan、Xiaoqun Liu、Tianlai Jin、Dongkuan Wu、Graziano Chesi、Ngai Wong、Hao Yu
Paper:
https://arxiv.org/abs/2408.10631
Introduction
Large language models (LLMs) have revolutionized natural language processing (NLP) with their impressive performance across various tasks. However, the increasing size and complexity of these models pose significant challenges in terms of computational and storage demands. For instance, models like GPT-175B, with 175 billion parameters, require vast resources, making them impractical for many applications. Efficient model compression strategies, such as quantization and pruning, are crucial for deploying these powerful models in practical scenarios.
Traditional pruning methods, such as magnitude-based pruning, directly trim weights based on their absolute values. While effective for smaller models, these methods often struggle with large-scale LLMs, resulting in suboptimal sparsity due to their inability to capture the complex interactions and importance of weights in such massive scalability. To address these limitations, recent post-training pruning techniques like SparseGPT and Wanda have emerged. However, these methods face challenges in capturing inter-layer dependencies and adapting to changes in weight significance during the pruning process.
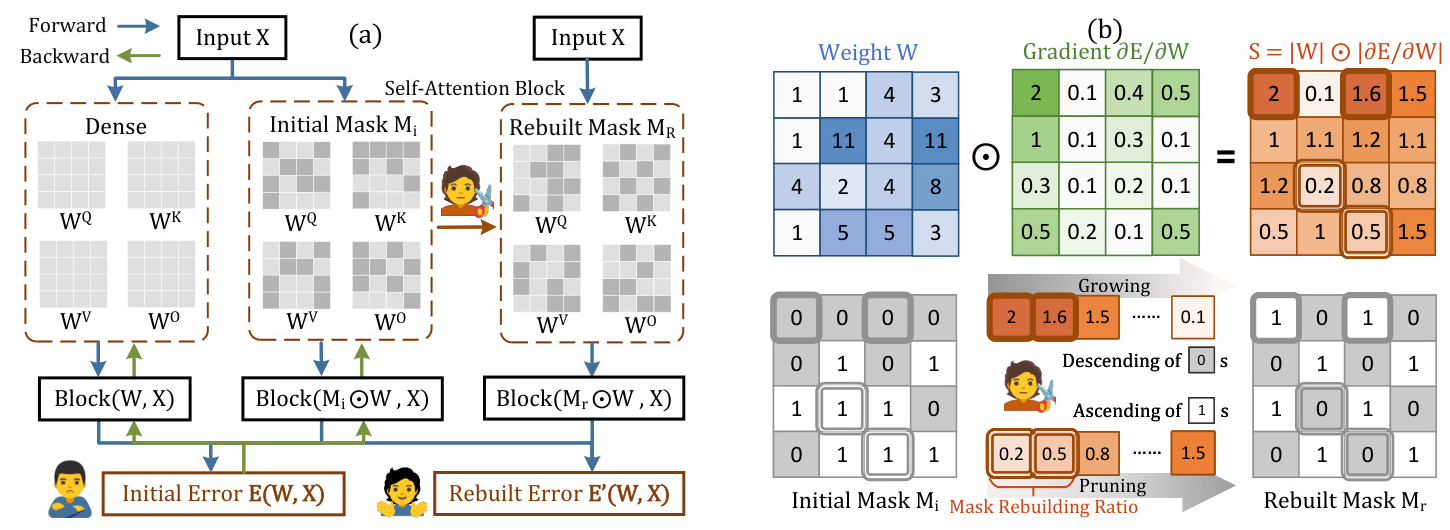
To overcome these challenges, we present LLM-Barber (Block-Aware Rebuilder for Sparsity Mask in One-Shot), a novel one-shot pruning framework that rebuilds the sparsity mask of pruned models without any retraining or weight reconstruction. LLM-Barber incorporates block-aware error optimization across Self-Attention and MLP blocks, ensuring global performance optimization. Inspired by the recent discovery of prominent outliers in LLMs, LLM-Barber introduces an innovative pruning metric that identifies weight importance using weights multiplied by gradients.
Related Work
LLMs Pruning and Sparsity
Network pruning reduces deep neural networks by removing unnecessary weights. For LLMs, pruning methods are divided into parameter-efficient fine-tuning and post-training approaches. Parameter Efficient Fine-tuning (PEFT) begins with an initialized sparse network and refines it through iterative processes. Dynamic Sparse No Training minimizes the reconstruction error by iteratively pruning and growing weights. However, fine-tuning requires ample data and often leads to performance decline.
Recent studies advance toward one-shot post-training pruning, showing substantial improvements. Post-training pruning removes weights from a pre-trained model. SparseGPT uses Hessian-based metrics and subsequent residual weight updates, while Wanda introduces a first-order pruning metric using weight-activation products. LLM-Barber employs a block-aware reconstruction approach and rebuilds masks with a novel pruning metric.
Model Compression Strategy
Compression is key to reducing the memory and computational demands of models. Traditional layer-aware compression strategies began with Optimal Brain Damage and Optimal Brain Surgeon. Recent works like GPTQ further enhance layer-aware quantization using second-order information. Block-aware compression strategies generally offer better accuracy recovery in pruned models compared to layer-aware methods. For instance, APTQ applies global quantization to attention mechanisms, enhancing model robustness, while BESA uses block-wise sparsity allocation. Our method leverages block-aware pruning to optimize global performance across Self-Attention and MLP blocks, effectively balancing efficiency and accuracy.
Research Methodology
Block-Aware Rebuilder for Sparsity Mask
Preliminaries
LLM pruning removes weights from dense networks to minimize output discrepancies, which is computationally intensive across large-scale models. This section reviews and reanalyzes layer-aware reconstruction error and Taylor expansion at dense networks.
Layer-aware Reconstruction Error: For a linear projection layer weight ( W ) of shape ((C_{out}, C_{in})), where ( C_{out} ) and ( C_{in} ) indicate the output and input channels. With ( N ) calibration samples and sequence length ( L ), the input activation is denoted as ( X ) with the shape of ((C_{in}, N \times L)). Layer-aware reconstruction error ( E ) is defined as the ( \ell_2 ) norm difference between the output of dense and sparse layers:
[ E(\hat{W}, X) = ||WX – \hat{W}X||_2^2, ]
where ( \hat{W} ) is the element-wise product of ( W ) and a binary sparsity mask ( M(i, j) \in {0, 1} ) of shape ((C_{out}, C_{in})).
Taylor Expansion at Dense Networks: For a dense network ( \hat{W}_{dense} ) at a local minimum, the reconstruction error can be expanded into its Taylor series with respect to ( \hat{W} ), ignoring terms beyond second order:
[ E(\hat{W}, X) = E(\hat{W}_{dense}, X) + \frac{\partial E}{\partial W} \Delta W + \frac{1}{2} \Delta W^T H \Delta W. ]
Block-Aware Rebuilder for Sparsity Mask
In this work, we depart from existing post-training pruning methods in three key aspects:
- Block-Aware Reconstruction Error: We adopt a block-aware reconstruction error and apply a divide-and-conquer strategy to mitigate errors and computational costs.
- Mask Rebuilding: Inspired by the pruning-and-growing operation, we address the limitations of mask selection of pruning in dense networks by re-evaluating weight importance scores in sparse networks and rebuilding the sparsity mask through targeted growth of salient weights and pruning of non-salient weights.
- Pruning Metric: We propose an innovative pruning metric based on the product of weights and gradients, leveraging first-order Taylor series for importance evaluation to reduce computational complexity compared to second-order Hessian-based approaches.
Experimental Design
Setup
LLM-Barber is implemented in PyTorch and utilizes public model checkpoints from the HuggingFace library on a single 80GB NVIDIA A100 GPU. After mask initialization, LLM-Barber uniformly rebuilds sparsity masks in sequence, performing in one-shot without any fine-tuning.
Models & Datasets
LLM-Barber is evaluated on the LLaMA family, including LLaMA-7B/13B, LLaMA2-7B/13B, and LLaMA3-8B, as well as the OPT model series: OPT-6.7B/13B. Following previous works, we use 128 segments of 2048 tokens from the C4 dataset for mask rebuilding.
Evaluation
To comprehensively assess LLM-Barber, we conduct rigorous evaluations on perplexity and zero-shot accuracy. Perplexity is measured on the validation sets of benchmarks such as WikiText-2, PTB, and C4. Zero-shot accuracy is assessed using the EleutherAI LM Harness across six benchmarks: BoolQ, RTE, HellaSwag, ARC Easy and Challenge, and OpenbookQA.
Baselines
The results of LLM-Barber are compared with the following established post-training pruning methods:
- Magnitude Pruning: Eliminates weights based only on their magnitudes.
- SparseGPT: Identifies weights’ importance using second-order information.
- Wanda: Determines weights to be pruned by the weight magnitude multiplied by input activation.
Results and Analysis
Unstructured Sparsity
LLM-Barber effectively prunes the LLaMA and OPT models, achieving 50% unstructured sparsity without requiring supplementary weight reconstruction. LLM-Barber demonstrates the capability to rebuild the sparsity masks initialized by other pruning methods in a single forward pass, significantly outperforming conventional pruning baselines. For instance, in the LLaMA3-8B model, LLM-Barber creates a new sparsity mask that reduces perplexity to 9.451, a substantial improvement over the Wanda baseline of 9.821.


Varying Sparsity Levels
Experiments on varying sparsity levels for unstructured pruning in LLaMA3-8B show that LLM-Barber consistently increases perplexity across all initialization methods, with magnitude pruning showing the most significant improvement.

Structured N:M Sparsity
Employing N:M fine-grained sparsity can provide more tangible acceleration benefits when leveraging NVIDIA Ampere’s sparse tensor cores. LLM-Barber is evaluated on partial LLaMA models with the N:M fine-grained sparsity pattern, demonstrating its effectiveness.

Zero-shot Performance
LLM-Barber is evaluated on six diverse zero-shot tasks. Averaging the accuracy across the six evaluated tasks, it becomes apparent that LLM-Barber possesses the capability to identify a more effective network than those obtained via the initialization methods. For tasks such as BoolQ, RTE, and ARC-e, LLM-Barber consistently outperforms the baseline pruning techniques across the entire LLaMA model suite.

Mask Rebuilding Ratio Selection
A critical aspect of the LLM-Barber method lies in determining the optimal mask rebuilding ratio to achieve peak accuracy. Analyzing the distribution of value magnitudes within the mask rebuilding pairs helps in identifying an appropriate mask rebuilding ratio. LLM-Barber identifies a larger proportion of outliers in less effective initial masks, corresponding to a more substantial rebuilding of the mask.

Ablation Study
Pruning Granularity
LLM-Barber dynamically selects different pruning granularities to adapt to varying initialization methods. The impact of four levels of granularities: block-wise, layer-wise, input-wise, and output-wise pruning is evaluated. By tailoring the pruning granularity to the particular pruning approach, LLM-Barber consistently achieves optimal model performance.

Pruning Metric
The effect of different pruning metrics, focusing on weight magnitude, gradient magnitude, and the product of weight and gradient, is analyzed. The product of weight and gradient consistently outperforms other metrics, confirming the effectiveness of our product-based pruning metric across various methods.

Calibration Data Size
The influence of varying the size of calibration data on the performance of LLM-Barber is explored. As the calibration sample size increases, LLM-Barber maintains robust performance, outperforming SparseGPT even with just a single sample.

Overall Conclusion
We propose LLM-Barber (Block-Aware Rebuilder for Sparsity Mask in One-Shot), a novel framework that rebuilds sparsity masks to optimize LLM post-training pruning. By integrating a block-aware approach across Self-Attention and MLP blocks, LLM-Barber effectively reallocates sparsity to improve accuracy without the need for extensive fine-tuning. Specifically, LLM-Barber identifies novel importance scores after mask initialization and rebuilds the sparsity mask with mask rebuilding pairs, simultaneously applying new sparsity masks to weights that have become less critical, thereby optimizing overall model performance. By utilizing the novel pruning metric as the product of weights and gradients, our approach enables precise and efficient reallocation of sparsity masks. Extensive experiments on pruning LLaMA series models demonstrate that LLM-Barber achieves state-of-the-art results in both perplexity and zero-shot performance within the domain of post-training pruning.
Code:
https://github.com/yupengsu/llm-barber


