





Authors:
Vladimir Araujo、Marie-Francine Moens、Tinne Tuytelaars
Paper:
https://arxiv.org/abs/2408.09053
Introduction
Continual Learning (CL) aims to enable models to learn new tasks sequentially without forgetting previously acquired knowledge. This is particularly challenging in Natural Language Processing (NLP) due to the diverse and evolving nature of language tasks. Recent advancements in Pre-trained Language Models (PLMs) and Parameter-Efficient Fine-Tuning (PEFT) methods have shown promise in addressing these challenges. PEFT methods, such as prompts or adapters, allow for efficient fine-tuning of PLMs for specific tasks while keeping the main model frozen. However, these methods face significant limitations, including interference between modules and suboptimal routing during module composition.
In this study, we introduce a novel method called Learning to Route (L2R) for dynamic PEFT composition in CL. L2R isolates the training of PEFT modules to avoid interference and leverages a memory-based approach to learn a routing function for effective module composition during inference. Our evaluations demonstrate that L2R outperforms existing methods, providing better generalization and performance across various benchmarks.
Related Work
Continual Learning with PLMs
The advent of robust PLMs has significantly advanced CL in NLP. Existing approaches include replay-based methods, meta-learning-based methods, and PEFT methods. PEFT methods, in particular, have shown effectiveness in CL by adding new modules for new tasks while freezing previous ones to maintain a strong backbone and leverage past knowledge. However, these methods often face challenges in module interference and suboptimal routing.
Local Adaptation
Memory-based parameter adaptation (MbPA), also known as local adaptation, allows models to adapt to changes in data distributions by leveraging labeled data stored in memory. This approach has been effective in improving model performance in CL by fine-tuning the model before making predictions. Our work builds on this concept by introducing a router that dynamically composes PEFT modules based on input.
Learning to Route
In mixture-of-experts (MoE) models, routing activates subnetworks based on their specialized capabilities. Recent studies have employed adapters to implement MoE-style models and routing functions. However, existing approaches often rely on task centroids, learnable task vectors, or task distributions, which may not effectively direct input to the appropriate modules. Our method proposes a router learning approach that takes place prior to inference, enabling dynamic utilization of modules.
Research Methodology
Task-specific Adapters
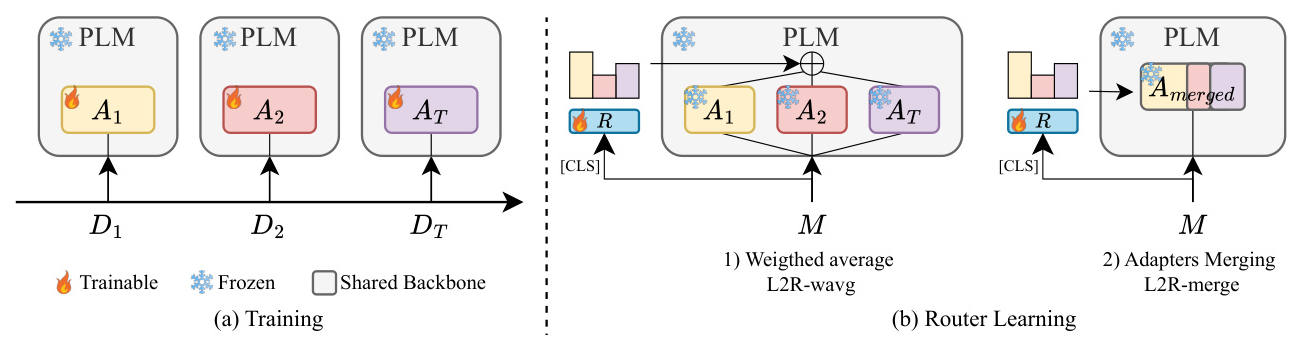
L2R employs a set of adapters that learn task-specific knowledge from a data stream. Each adapter is activated and trained when a new task emerges, while previous adapters are deactivated to avoid interference. This allows each adapter to specialize in its respective task. The backbone of the PLM remains frozen, and only the adapters are trained.


Memory
Our method includes a non-parametric memory that stores previously seen training examples. Unlike replay methods that use memory for rehearsal during training, our memory is used to learn a routing function prior to test inference. This approach captures the global distribution of the data stream, aiding in effective router training.
Memory-based Router Learning
Once the adapters are trained, they are combined for inference using a router network. The router computes the probability of the input being sent to each adapter, based on the [CLS] representation. This allows the router to learn to route based on input structure and produce different combinations at different layers. The router is trained using elements in memory, ensuring effective routing functions are learned before inference.
Adapter Composition
Given the routing probabilities, adapters can be composed in different ways. We consider two options: a weighted average of their outputs (L2R-wavg) and merging adapter parameters via a weighted average of their weights (L2R-merge).
Experimental Design
Benchmarks
We evaluate our method using two CL setups: Class-Incremental Learning (CIL) and Task-Incremental Learning (TIL). We use three benchmarks for evaluation:
- MTL5: 5 text classification tasks.
- WOS: 7 document classification tasks.
- AfriSenti: 12 multilingual sentiment analysis tasks.
Baselines
We compare L2R against several PEFT-based CL methods, including Lower-Bound, Upper-Bound, ProgPrompt, DAM, EPI, and MoCL. These methods represent various approaches to task-specific adapter training and routing.
Implementation Details
We use BERT for MTL5 and WOS, and AfroXLMR for AfriSenti. Adapters are implemented using LoRA due to its efficiency and performance. Memory is populated with 10% of each task’s training dataset. The router network consists of a linear transformation followed by a Gumbel-sigmoid activation.
Results and Analysis
Results on CIL
L2R-wavg and L2R-merge outperform comparable baselines in the CIL setup. L2R-wavg shows a clear advantage over L2R-merge, likely due to interference between adapter parameters when merged. The results highlight the importance of a well-learned router for effective module composition.

Results on TIL
In the TIL setup, L2R-wavg performs best in the MTL5 and AfriSenti benchmarks, while it lags behind in the WOS benchmark. The performance of L2R-wavg suggests that the learned routing function effectively combines adapters, leading to high performance across tasks.

Impact of Memory Size
The performance of L2R-wavg increases with larger memory sizes, demonstrating the importance of using more examples for effective router adaptation. This is particularly evident in the WOS benchmark, where performance improves significantly with increased memory size.
Router Analysis
We compare the routing probabilities from L2R-wavg with those from a version trained using Softmax activation. The results confirm that L2R provides a composition that leverages knowledge from multiple tasks, rather than relying on a single adapter.

Overall Conclusion
L2R introduces a novel approach to dynamic adapter composition in CL, enabling better generalization and performance. Our method leverages memory-based router learning to effectively combine task-specific adapters during inference. The results demonstrate the proficiency of L2R across various benchmarks and CL setups.
Limitations
Our method relies on a non-parametric memory, which may be limited in environments with storage constraints or data privacy concerns. Additionally, our experiments focus on small-scale PLMs, and further exploration with large language models (LLMs) is desirable.
In summary, L2R represents a significant advancement in dynamic adapter composition for CL, providing a robust and efficient solution for continual learning in NLP.


