





Authors:
Bruce W. Lee、Yeongheon Lee、Hyunsoo Cho
Paper:
https://arxiv.org/abs/2408.09049
Introduction
Recent advancements in large language models (LLMs) have significantly enhanced their capabilities, making them integral to various real-world applications. However, a primary concern is their non-deterministic nature, which allows them to generate diverse responses to the same input. This variability stems from the vast and heterogeneous datasets they consume, enabling them to capture complex probability distributions for a single topic and encompass multiple viewpoints. Despite this flexibility, LLMs exhibit a tendency towards specific phrasings, tones, or content types, indicating a central tendency within their outputs.
To systematically explore this phenomenon, the study introduces the role-play-at-scale methodology. This involves prompting LLMs with randomized, diverse personas and analyzing the macroscopic trends in their responses. The study aims to uncover inherent tendencies in LLMs, contributing to the discourse on value alignment in foundation models.
Related Work
Prompting and Model Inertia
Prompting is an empirical method where the input to the model is carefully crafted to steer the output toward a desired direction. Despite the flexibility of LLMs in generating diverse responses, they exhibit a sort of inertia, showing a preference for specific phrasings, tones, or content types. This inertia likely stems from the predominance of similar traits in their training data.
Recent Studies on LLM Tendencies
Recent studies have begun analyzing LLMs with questionnaires that are more interpretable to humans. Some studies employ the Portrait Values Questionnaire to measure basic human values in dimensions like self-direction and security within LLMs. Despite debates over the appropriateness of applying human criteria to machine learning models, applying human-centered frameworks to capture the nuanced ways in which these models operate is a promising research area.
Research Methodology
Role-Play-at-Scale
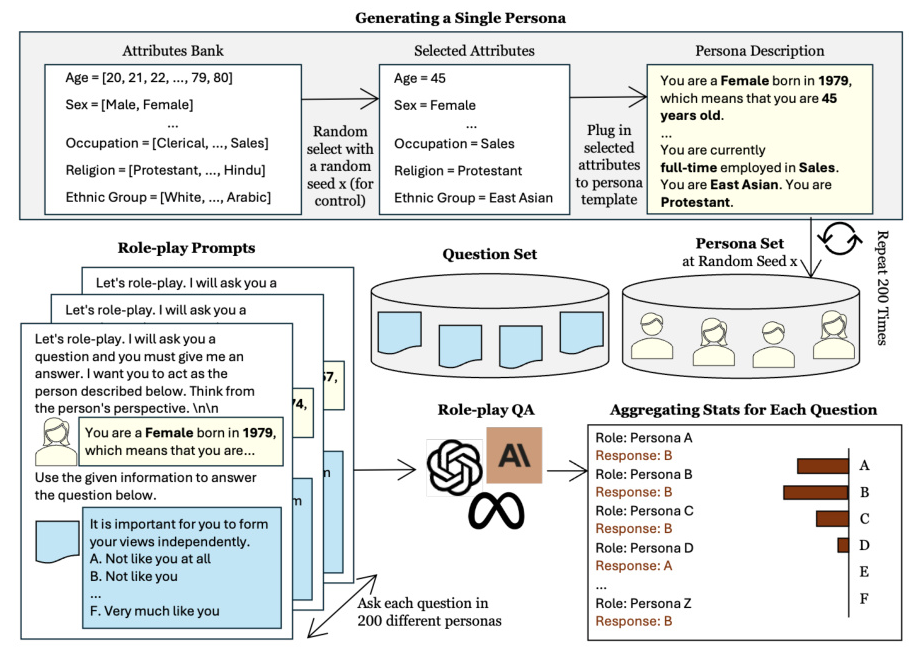
The role-play-at-scale method involves engaging LLMs in a wide range of persona-driven interactions. The models are prompted to respond from the perspective of randomly generated personas with diverse demographic backgrounds. By analyzing the consistency of the models’ responses across these varied scenarios, the study aims to identify stable tendencies and inertia inherent to the LLMs.


Research Questions
The study poses two key research questions:
1. Is there a response trend when exposed to repeated and randomized role-playing setups?
2. Does the preference persist through different persona sets?
Experimental Design
Persona Generation
The process begins by creating multiple sets of distinct personas, each containing a large number of randomly generated persona descriptions. These personas reflect various key demographic factors such as age, gender, occupation, cultural background, and religious beliefs.

Questionnaires
The study uses two well-established psychological questionnaires: the Revised Portrait Values Questionnaire (PVQ-RR) and the Moral Foundations Questionnaire (MFQ-30). These questionnaires present statements and ask the respondent to reply with one of six options that reflect how much the statement applies to them.
Models Tested
Seven models were tested: Claude 3 Opus, Claude 3 Sonnet, Claude 3 Haiku, GPT 4o, GPT 3.5 Turbo, LLaMA 3 70B Inst, and LLaMA 3 8B Inst. For each model, 200 personas were randomly generated, and the same question was asked 200 times, each time with a different persona.
Results and Analysis
Response Trends
The study found that LLM responses tend towards particular options or sides despite the randomly generated personas used for role-playing. This observation holds true across all tested models and moral/value dimensions.

Strong Preferences
LLMs showed strong preferences for certain moral statements, such as “One of the worst things a person could do is hurt a defenseless animal.” This trend is consistent with other studies reporting liberal-leaning political tendencies in LLMs.

Stability Across Persona Sets
The study measured score differences between three randomly generated persona sets. The average scores for each moral foundation and value dimension remained highly consistent across the three persona sets, suggesting that the role-play-at-scale method effectively captures the stable tendencies of the LLMs.

More Role-Play Leads to Less Variance
As the number of role-plays with randomized personas increases, score variances decrease, indicating convergence. This finding demonstrates that a sufficient number of role-playing scenarios leads to a stable assessment of inherent LLM tendencies.
Overall Conclusion
The study introduces a novel role-play-at-scale framework to uncover stable tendencies within LLMs. By systematically role-playing LLMs with diverse, randomized personas while responding to psychological questionnaires, the study demonstrates consistent value and moral preferences that persist across various contexts. These tendencies appear deeply rooted in the models, not artifacts of specific scenarios.
While the study has limitations, such as the absence of human baseline data and reliance on multiple-choice questionnaires, it opens up new avenues for research into AI behavior and ethics. Future work should address these limitations, expand the methodology to capture more nuanced tendencies, and explore the implications of these findings for real-world AI applications.




