





Authors:
Dong Li、Chen Zhao、Minglai Shao、Wenjun Wang
Paper:
https://arxiv.org/abs/2408.09312
Introduction
Machine learning models often assume that training and test data are independently and identically distributed (i.i.d.). However, this assumption does not hold in many real-world scenarios, leading to poor model performance when there is a distribution shift between training and test domains. Addressing these distribution shifts and ensuring model generalization to unseen but related test domains is the primary goal of domain generalization (DG).
In addition to generalization, fairness in machine learning has become a critical concern. Fairness implies the absence of bias or favoritism towards any individual or group based on inherent or acquired characteristics. Existing methods for fairness-aware domain generalization typically focus on either covariate shift or correlation shift but rarely address both simultaneously.
This paper introduces a novel approach, Fairness-aware LeArning Invariant Representations (FLAIR), which aims to learn a fairness-aware domain-invariant predictor that can generalize to unknown test domains while considering both covariate and correlation shifts.
Related Work
Algorithmic Fairness in Machine Learning
Fairness in machine learning has garnered significant attention, with a recognized trade-off between fairness and accuracy. Fairness metrics are typically divided into group fairness and individual fairness. Achieving both simultaneously is challenging, as methods that ensure group fairness may not handle individual fairness effectively.
Fairness-Aware Domain Generalization
Several efforts have been made to address fairness-aware domain generalization. Methods like EIIL and FVAE consider correlation shift but assume covariate shift remains invariant. FATDM focuses on covariate shift and group fairness but does not address correlation shift or individual fairness. There is a need for a comprehensive approach that considers both covariate and correlation shifts while ensuring fairness.
Research Methodology
Problem Formulation
The goal is to learn a fairness-aware predictor that generalizes to unseen test domains. Given a set of training domains, the predictor should remain invariant across domains in terms of accuracy and fairness concerning sensitive subgroups.
Framework Overview
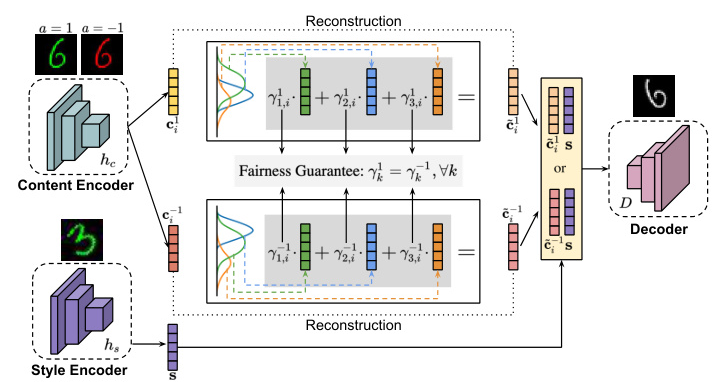
FLAIR consists of three components:
1. Content Featurizer: Encodes instances into latent content factors.
2. Fair Representation Learner: Reconstructs fair content representations by minimizing sensitive information and maximizing non-sensitive information.
3. Invariant Classifier: Uses the fair content representations to make predictions.
The framework ensures that the predictor is both domain-invariant and fairness-aware, enabling effective generalization to unseen test domains.
Experimental Design
Datasets
- Rotated-Colored-MNIST (RCMNIST): A synthetic dataset generated from MNIST by rotating and coloring digits. Different rotation angles represent different domains, and color serves as the sensitive attribute.
- New-York-Stop-and-Frisk (NYPD): A real-world dataset containing stop, question, and frisk data from suspects in five cities. The cities represent different domains, and gender is the sensitive attribute.
- FairFace: A face image dataset labeled with race, gender, and age groups. Different race groups represent different domains, and gender is the sensitive attribute.
Evaluation Metrics
- Accuracy: Measures the DG performance of the algorithm.
- Demographic Parity Difference (ΔDP): A group fairness metric that measures the difference in acceptance rates across sensitive subgroups.
- AUC for Fairness (AUCfair): A pairwise group fairness metric that measures the probability of correctly ranking positive examples ahead of negative examples.
- Consistency: An individual fairness metric that measures the distance between each individual and its k-nearest neighbors.
Compared Methods
FLAIR is compared with 13 methods, including DG methods without fairness consideration (e.g., ERM, IRM, GDRO) and fairness-aware methods (e.g., DIR, EIIL, FVAE, FATDM).
Results and Analysis
Overall Performance
FLAIR demonstrates superior performance in achieving both group and individual fairness across all three datasets. It consistently ranks as either the fairest or the second fairest method in each domain while maintaining competitive DG performance.


Ablation Study
An ablation study was conducted to understand the roles of the transformation model and the fair representation learner in FLAIR. The study shows that the transformation model ensures domain invariance, while the fair representation learner enhances both individual and group fairness.

Sensitive Analysis
FLAIR achieves the best accuracy-fairness trade-off across different datasets. By controlling the value of the fairness parameter, FLAIR maintains comparable accuracy while ensuring the best fairness performance.

Overall Conclusion
FLAIR introduces a novel approach to fairness-aware learning that addresses both covariate and correlation shifts simultaneously. It ensures effective generalization to unseen test domains while maintaining fairness between sensitive subgroups. Extensive empirical studies demonstrate that FLAIR outperforms state-of-the-art methods in terms of both accuracy and fairness.

The success of FLAIR on various datasets highlights its robustness and effectiveness in handling complex DG problems involving multiple types of distribution shifts.


