





Authors:
Vamsi Krishna Pendyala、Hessam S. Sarjoughian、Bala Potineni、Edward J. Yellig
Paper:
https://arxiv.org/abs/2408.09307
Introduction
The rapid advancements in high-computing devices have necessitated the development of smarter manufacturing factories, particularly in the semiconductor industry. Discrete-event models and simulators play a crucial role in designing, building, and operating semiconductor manufacturing processes. Machines such as diffusion, implantation, and lithography are integral to these processes, characterized by their complex feed-forward and feedback connectivity. The dataset derived from simulations of these factory models holds significant potential for generating valuable machine-learning models. These surrogate data-based models offer high efficiency compared to their physics-based counterparts. This research focuses on devising and constructing a benchmark dataset based on a model of an Intel semiconductor fabrication factory, formalized using the Parallel Discrete-Event System Specification (PDEVS) and executed using the DEVS-Suite simulator.
Related Work
Machine learning (ML) has been instrumental in enhancing traditional semiconductor manufacturing processes. Various studies have explored the use of ML to improve yield and efficiency in semiconductor manufacturing. For instance, Jiang et al. (2019) discussed the application of ML in improving semiconductor manufacturing yield. Liu et al. (2020) reviewed different ML algorithms and datasets available for enhancing semiconductor manufacturing. Shin and Park (2018) derived data from manufacturing logs, while Saif M. Khan (2020) highlighted a publicly available dataset of the semiconductor manufacturing process. However, these datasets often lack flexibility in altering factory settings and parameters. This research aims to address this gap by using Discrete Event Simulation (DES) to generate data for a given factory configuration, which can then be used to develop ML algorithms.
Research Methodology
Discrete-Event Modeling
Discrete Event Simulation (DES) is extensively used to model and simulate semiconductor manufacturing. One of the methods for DES is the Parallel Discrete Event System Specification (PDEVS). PDEVS models are causal, providing a concise understanding and rich interpretations of simulated behavior. Execution of these event-based atomic and coupled models results in time trajectories where their data do not necessarily have uniform time intervals. These models can be simulated using various simulators supported in popular programming languages and executable on single/multi-processor computing platforms.
PDEVS Semiconductor Fabrication Model
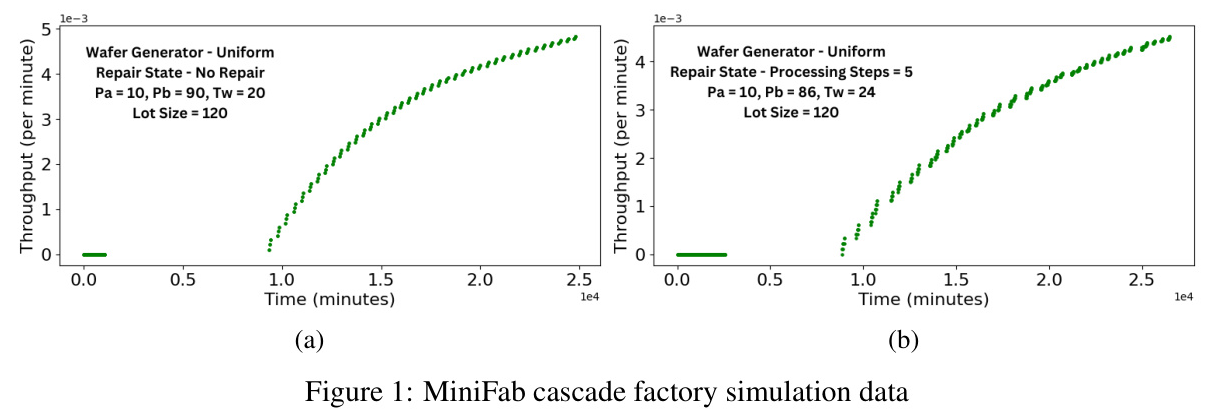
The PDEVS formalism is used to develop single-stage and multi-stage semiconductor fabrication factory models. The factory is modeled as a coupled model comprising Diffusion, Implantation, and Lithography machines. Each machine processes wafer lots in consecutive, non-interruptible phases, with configurable duration and stochasticity. The factory models can receive different types of wafer lots, forming batches processed in six steps. The feed-forward and feedback relationships among the machines define the ordering of these steps.
Experimental Design
Dataset Generation
The PDEVS models are used to simulate a set of experiments for single-stage and multi-stage factories using the DEVS-Suite simulator. Four transducer models measure and collect input, output, and state information at every simulation execution step. An eight-stage cascade model is created using the single-stage model, generating scenarios with higher structure and behavior complexities. Based on the logic of wafer processing, 93 different tuples of wafer lot configurations are formed, each representing small, medium, and large lot sizes. These configurations are used to simulate 372 scenarios for the eight-stage cascade factory models.


Time Series Dataset
The simulation output is stored in comma-separated value (CSV) files for individual atomic and coupled factory model components. The data is converted into a time series dataset by filling missing values using the front-filling method. This pre-processing helps form a complete time series dataset with a time granularity of 1 minute. The dataset allows for univariate and multivariate time series analysis, providing insights into wafer processing at each step.

Feature Extraction and Analysis
To understand the relationship between throughput values of different configurations, around 6,995 features of the ‘Cascade Factory Throughput’ time series are extracted using Python’s TsFresh library. These features include lag features, trend, skewness, quantile changes, entropy, etc. Principal Component Analysis (PCA) is used to visualize these features, providing insights into the manufacturing process’s stability and complexity.

Results and Analysis
Demonstration of Benchmark Datasets
The simulation output is transformed from a discrete event to a discrete-time time series by filling the missing values. Multiple time series forecasting models, including ARIMA, RNN, LSTM, TCN, and TFT, are used to construct baseline models. The performance of these models is evaluated using metrics such as Mean-Square Error (MSE), Mean Average Percentage Error (MAPE), R2 scores, and Mean-Forecast Error (MFE). The TFT model, which considers static covariates, shows promising results for different configurations.

Univariate and Multivariate Time Series Forecasting
Univariate time series forecasting is performed using the TCN model, trained on different lot size categories. The results indicate that the model trained on medium lot size performs better compared to other models. Multivariate analysis is also performed using the TCN model, considering various combinations of throughput values from multiple stages as input. The findings emphasize the importance of considering stage interdependence in semiconductor manufacturing predictive modeling.


Overall Conclusion
This research demonstrates the utility of concise and accurate datasets collected from physics-based simulations for developing ML models suitable for time series analysis. The datasets generated using PDEVS models and Intel’s benchmark factory description facilitate a wide range of metrics and measurements. The developed time series models, such as TCN and TFT, can make predictions comparable to those obtained from PDEVS simulations. Future work includes developing additional models and benchmark datasets for semiconductor supply-chain systems.
Acknowledgments and Disclosure of Funding: This research is funded by Intel Corporation, Chandler, Arizona, USA.


