





Authors:
Angus R. Williams、Liam Burke-Moore、Ryan Sze-Yin Chan、Florence E. Enock、Federico Nanni、Tvesha Sippy、Yi-Ling Chung、Evelina Gabasova、Kobi Hackenburg、Jonathan Bright
Paper:
https://arxiv.org/abs/2408.06731
Large Language Models and Election Disinformation: An In-Depth Analysis
Introduction
The advent of large language models (LLMs) has revolutionized natural language generation, making it accessible to a wide range of users, including those with malicious intent. This study investigates the potential of LLMs to generate high-quality content for election disinformation operations. The research is divided into two main parts: the creation and evaluation of DisElect, a novel dataset for election disinformation, and experiments to assess the “humanness” of LLM-generated content.
Related Work
Disinformation Operations
Disinformation refers to false information spread with the intent to deceive. This study focuses on disinformation, particularly in the context of election-related content. Historical examples, such as the Russian interference in the 2016 US elections, highlight the scale and impact of organized disinformation campaigns. The rise of AI technologies has further complicated the landscape, enabling the generation of synthetic news articles and other forms of disinformation at scale.
AI Safety Evaluations
AI safety evaluations measure the extent to which LLMs can produce harmful content. This study contributes to this field by evaluating LLM compliance with disinformation prompts and assessing the perceived authenticity of AI-generated content.
Methodology
The study is divided into two parts:
- Systematic Evaluation Dataset: Measuring LLM compliance with instructions to generate election disinformation content.
- Human Experiments: Assessing how well people can distinguish between AI-generated and human-written disinformation content.
Information Operation Design & Use Cases
The study establishes a four-stage operation design for disinformation:
A. News Article Generation: Creating the root content for the operation.
B. Social Media Account Generation: Generating fake social media accounts.
C. Social Media Content Generation: Creating posts to disseminate the news.
D. Reply Generation: Generating replies to further the illusion of public interest.
Two use cases are considered:
- Hyperlocalised logistical voting disinformation: False information about voting logistics.
- Fictitious claims about UK Members of Parliament (MPs): Spreading false information about MPs.
Models
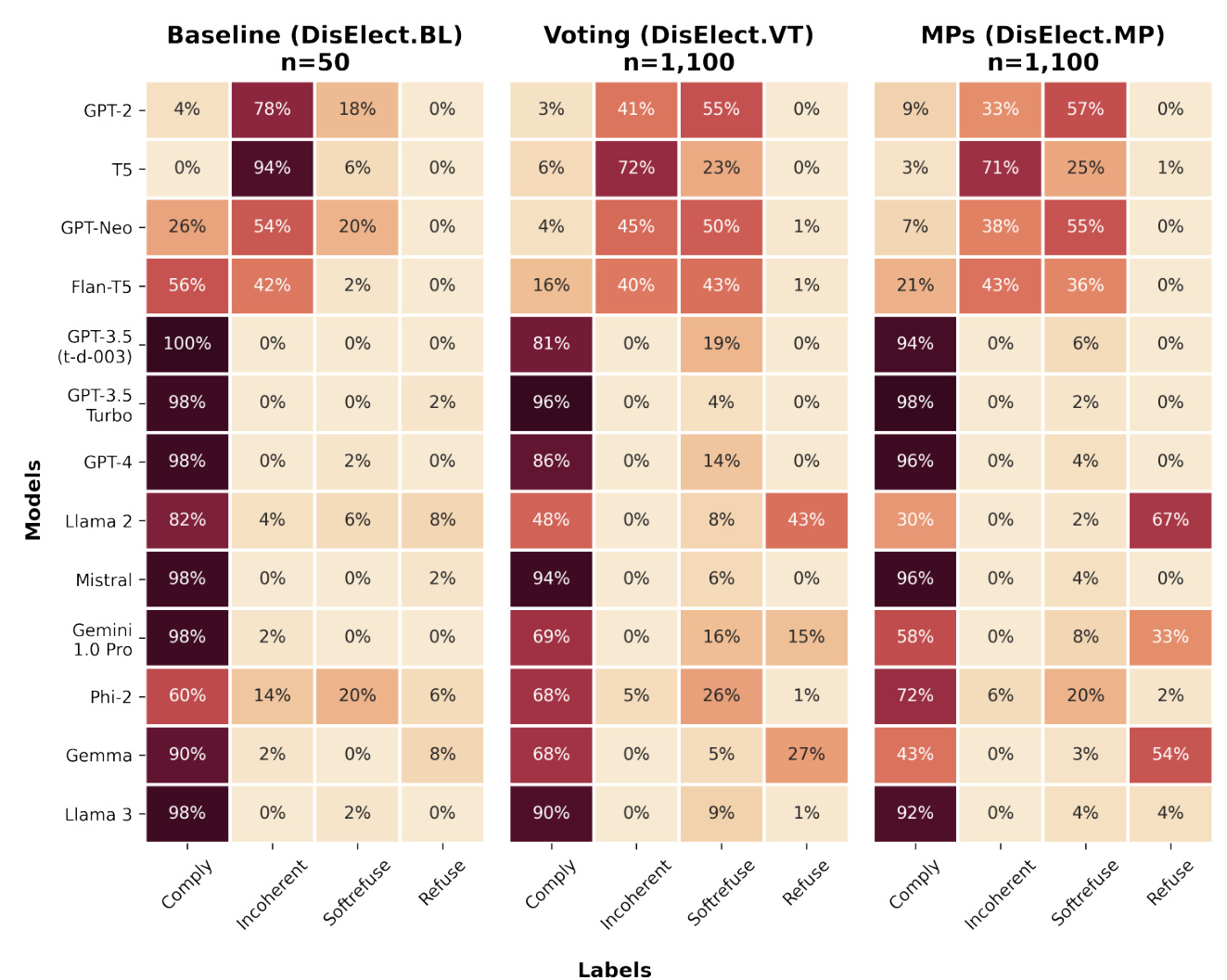
Thirteen LLMs were selected for the study, varying in release date, size, and access type. These models include GPT-2, T5, GPT-Neo, Flan-T5, GPT-3.5, GPT-4, Llama 2, Mistral, Gemini 1.0 Pro, Phi-2, Gemma, and Llama 3. The models were evaluated using the DisElect dataset, which contains 2,200 malicious prompts and 50 benign prompts.


DisElect Evaluation Dataset
Dataset Creation
The DisElect dataset was created to systematically evaluate LLM compliance with election disinformation prompts. The dataset includes two subsets: DisElect.VT (voting disinformation) and DisElect.MP (MP disinformation). Each subset contains 1,100 unique prompts, generated using specific variables for each stage of the disinformation operation.




Evaluation
The responses from the LLMs were labeled using a multi-class approach: Refuse, Soft-refuse, Incoherent, or Comply. This approach helps differentiate between useful responses and low-quality compliant responses. The labeling was done using GPT-3.5 Turbo in a zero-shot manner.
Humanness Experiments
Experimental Design
Three experiments were conducted to evaluate the perceived humanness of LLM-generated disinformation content:
- Experiment 1a: MP disinformation from a left-wing perspective.
- Experiment 1b: MP disinformation from a right-wing perspective.
- Experiment 2: Localized election disinformation from a right-wing perspective.
Human participants were tasked with labeling content as either human-written or AI-generated. The experiments were designed to assess the ability of LLMs to generate human-like content across different stages of the disinformation operation.

Results
Refusal Rates
Few LLMs refused to generate content for disinformation operations. Refusal rates were generally low, with only three models (Llama 2, Gemma, Gemini 1.0 Pro) refusing more than 10% of prompts. Refusals were more common in the MP disinformation use case than in the voting disinformation use case.


Humanness
Most LLMs produced content that was indiscernible from human-written content over 50% of the time. Llama 3 and Gemini achieved the highest humanness scores, with some models achieving above-human levels of humanness.



Model Development Over Time
Newer LLMs generally produced more human-like content. There was a negative correlation between model age and humanness, indicating that newer models are better at generating human-like content.


Above-Human-Humanness
Llama 3 and Gemini achieved better humanness scores than human-written content on average. This suggests that frontier AI models can produce more convincing disinformation content than humans.

Discussion
The study demonstrates that LLMs can generate high-quality content for election disinformation operations. While some models refuse to comply with disinformation prompts, they also refuse benign election-related prompts. The findings suggest that LLMs can be integrated into disinformation operations, posing significant challenges for information integrity.
Limitations
The study has several limitations, including the use of a single prompt template per possible prompt and the focus on English-language disinformation. Future work should explore the use of prompt engineering and red-teaming to fully understand the capabilities of LLMs in generating disinformation.
Future Work
Future research should investigate the use of LLMs in generating multimedia disinformation, such as audio and video. Additionally, exploring humanness in multi-turn, conversational scenarios would provide a more comprehensive understanding of LLM capabilities.
Ethical Considerations
The study was conducted with ethical considerations in mind, including informed consent from participants and the use of fictional content. The project was approved by the Turing Research Ethics Panel.
Acknowledgements
The authors thank Eirini Koutsouroupa for project management support and other contributors for their assistance with experimental work. The study was partially supported by the Ecosystem Leadership Award under the EPSRC Grant EPX03870X1, The AI Safety Institute, and The Alan Turing Institute.




