





Authors:
Firas Bayram、Bestoun S. Ahmed、Erik Hallin
Paper:
https://arxiv.org/abs/2408.06724
Introduction
In the modern industrial landscape, data has become a critical asset, driving the success of artificial intelligence (AI) and machine learning (ML) solutions. Ensuring the quality of this data is paramount for reliable decision-making. This paper introduces the Adaptive Data Quality Scoring Operations Framework, a novel approach designed to address the dynamic nature of data quality in industrial applications. By integrating a dynamic change detector mechanism, this framework ensures that data quality scores remain relevant and accurate over time.
Conceptual Background
Continuous Monitoring and Drift Detection
Continuous monitoring of data streams is essential to capture dynamic changes and maintain high data quality. Drift in data streams refers to changes in the statistical properties of the data over time. Detecting drift involves quantifying the dissimilarity between data distributions at different time points. The framework uses the Jensen-Shannon divergence to measure this dissimilarity, dynamically adjusting the threshold for drift detection to reflect evolving system conditions.
Data Quality Assurance
Data quality assurance involves evaluating various dimensions of data quality, such as accuracy, completeness, consistency, timeliness, and skewness. Each dimension provides a unique perspective on the data’s characteristics. The framework focuses on quantitative data scoring, providing valuable insights for industrial applications.
Related Work
Previous research has explored various methods for data quality assessment across different domains, including healthcare, finance, and IoT. Traditional methods often lack the adaptability required for dynamic industrial environments. Recent studies have introduced ML-based techniques for data quality scoring, but these methods often neglect the adaptive nature of data quality dimensions.
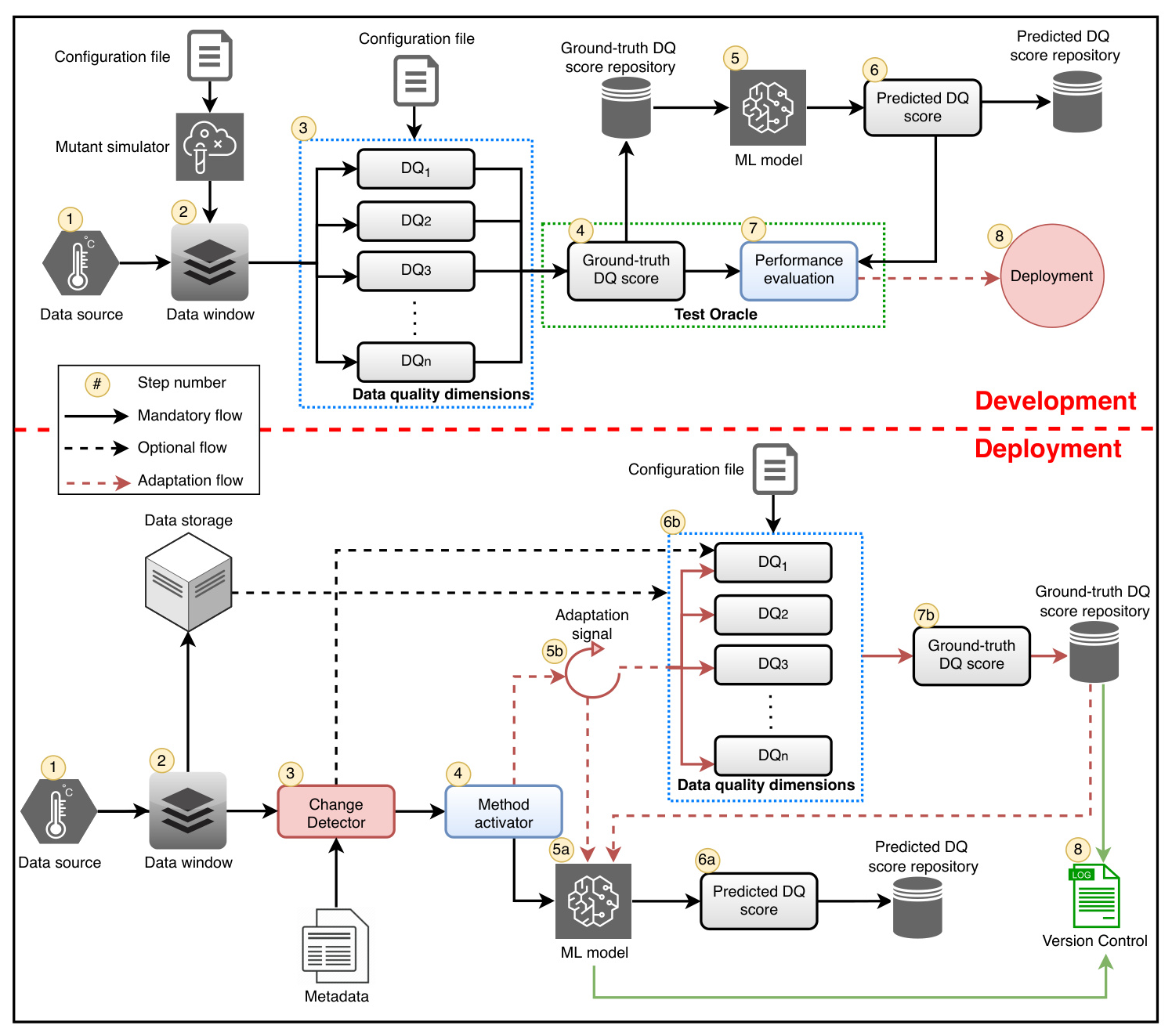
The Adaptive Data Quality Scoring Operations Framework
The proposed framework employs an ML-based approach to score data quality in industrial applications. It addresses the limitations of non-adaptive frameworks by dynamically adjusting data quality scores based on detected drifts in the data streams.
An Overview of ML-Based Data Quality Scoring
The ML-based scoring framework uses an ML predictor to generate a unified data quality score. The framework incorporates MLOps principles, ensuring continuous monitoring and validation of the ML model. The scoring process involves aggregating the calculated values of various data quality dimensions using Principal Component Analysis (PCA).
Development Phase
The development phase involves initializing system artifacts, such as the ML predictor, divergence values, anomaly detector, data distribution, and historical samples. These artifacts are essential for streamlining the solution in production.
Deployment Phase
In the deployment phase, the framework integrates the developed components into the operational system. The change detector assesses the occurrence of drift, triggering the adaptation process when necessary. This ensures that the ML model remains up-to-date with the evolving data characteristics.
Experimental Results
The framework was evaluated in a real-world industrial use case at Uddeholms AB, a leading steel manufacturer. The experiments assessed the framework’s predictive performance, processing time, and resource consumption.
Drift Detection Sensitivity Analysis
The sensitivity analysis of the drift detection mechanism revealed that the number of detected changes varies with different significance thresholds. A lower threshold results in fewer detections, while a higher threshold increases sensitivity.
Performance Analysis of DQ Scoring Predictions
The predictive performance of the ML model was evaluated using Mean Absolute Error (MAE) and R-squared (R2) metrics. The results showed that the adaptive approach improves predictive performance after executing adaptation mechanisms.
Time Required Analysis
The time required for different scoring methodologies was analyzed. The adaptive approach demonstrated significant improvements in processing efficiency compared to the standard and static approaches.
Analysis of Dynamic Data Quality Dimension Scores
The analysis of dynamic data quality dimensions, such as timeliness and skewness, showed substantial changes in scores after drift occurrences. This highlights the importance of adaptation in reflecting the evolving characteristics of the data.
Resource Consumption
The resource consumption analysis revealed that the adaptive approach consumes slightly more CPU compared to the static approach, while the memory usage is similar. The standard approach showed the lowest resource consumption.
Conclusion
The Adaptive Data Quality Scoring Operations Framework addresses the challenges of scoring dynamic data quality dimensions in industrial processes. By integrating a dynamic change detector, the framework ensures that data quality scores remain relevant and accurate over time. The experimental results demonstrate substantial improvements in processing time efficiency and predictive performance, making the framework a feasible solution for critical industrial applications.
Moving forward, the integration of this framework into broader data-driven AI systems will be explored, leveraging real-time data quality scores to enhance ML model training and decision-making processes in industrial environments.


