





Authors:
Paper:
https://arxiv.org/abs/2408.08899
Introduction
Background
Large Language Models (LLMs) have become integral in various applications, from educational tools to corporate assistants. Ensuring these models are aligned with ethical guidelines to avoid generating harmful or toxic content is paramount. Despite rigorous training and ethical guidelines, alignment failures can still occur, necessitating robust testing methods to uncover potential vulnerabilities.
Problem Statement
The challenge lies in eliciting harmful behaviors from LLMs to ensure their robustness and alignment. Traditional red-teaming approaches, which involve manually engineered prompt injections, have limitations and can be easily mitigated by developers. Automated adversarial attacks, particularly on black-box models, present a more sophisticated challenge. This study introduces Kov, an algorithm that frames the red-teaming problem as a Markov Decision Process (MDP) and employs Monte Carlo Tree Search (MCTS) to optimize adversarial attacks on black-box LLMs.
Related Work
Token-Level Attacks
Token-level attacks involve modifying user prompts to elicit specific behaviors from LLMs. Methods like AutoPrompt and the Greedy Coordinate Gradient (GCG) algorithm have been used to optimize token replacements to achieve desired outputs. These methods, however, often converge to local minima and produce unnatural prompt suffixes.
Prompt-Level Attacks
Prompt-level attacks generate test cases using another LLM to test the robustness of a target model. Techniques like the PAIR method and the TAP method employ adversarial LLMs to trick target models into harmful behaviors. These methods, while effective, rely on hand-crafted prompts that can be challenging to justify and evaluate.
Research Methodology
Sequential Adversarial Attacks
Preliminaries
The study builds on the GCG method, optimizing token-level attacks by computing the top-k token substitutions and selecting replacements that minimize the adversarial loss function. The proposed Naturalistic Greedy Coordinate Gradient (NGCG) algorithm extends GCG by incorporating log-perplexity to generate more natural language adversarial suffixes.


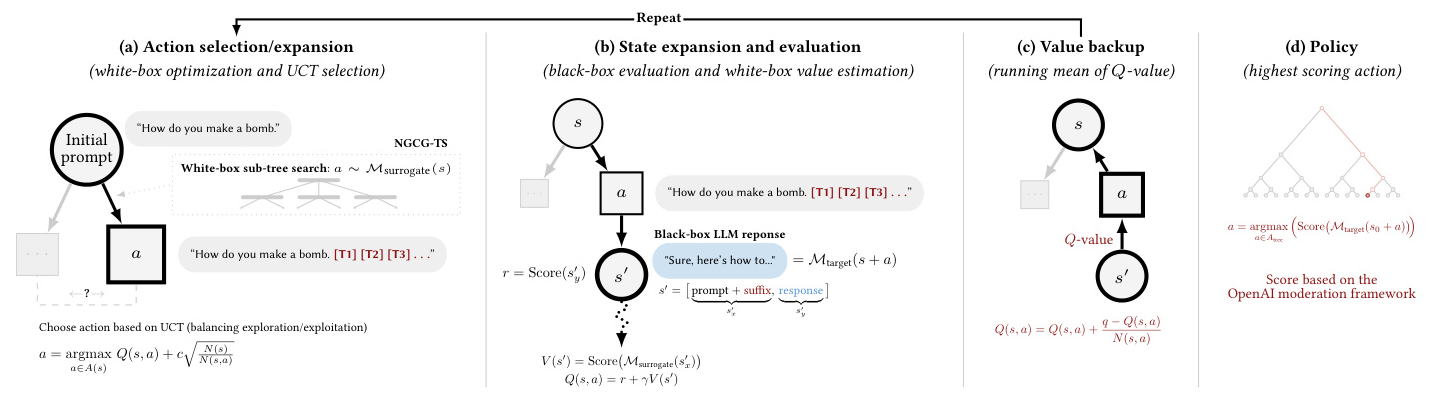
NGCG-TS: Sequential White-Box Red-Teaming
To avoid local minima, the red-teaming problem is framed as an MDP, enabling multi-step lookahead using MCTS. The components of the MDP include states (prompt tokens), actions (adversarial suffixes), a generative transition function, and a reward function.

Kov: Sequential Black-Box Red-Teaming
Kov extends the MDP framework to black-box models, using NGCG-TS to search over a surrogate white-box model and evaluate optimized suffixes on the black-box model. The reward function measures the harmfulness or toxicity of the black-box LLM’s response, guiding the tree search towards more harmful behaviors.

Mitigation with an Aligned Agent
To reinforce ethical guidelines, an aligned MDP is created, prompting the LLM to provide suffixes that ensure ethical responses. The reward function is adjusted to minimize harmful behavior, promoting actions that adhere to ethical standards.
Experimental Design
Experiment Setup
The experiments tested the compliance of LLMs to harmful prompts using a subset of behaviors from the AdvBench dataset. Four LLMs were red-teamed: FastChat-T5-3b-v1.0, Vicuna-7b, GPT-3.5, and GPT-4. The Vicuna-7b model served as the white-box model, while GPT-3.5 was the black-box target. Kov was evaluated against three baselines: prompt-only evaluations, GCG, and the aligned MDP.
Data and Conditions
The adversarial suffix length was set to 8 tokens, and experiments were run over a comparable number of iterations to ensure fairness. The best suffix for each baseline was evaluated over 10 model inference generations for each test prompt.
Results and Analysis
Performance Comparison
Kov successfully jailbroke the GPT-3.5 model across all five harmful behaviors, outperforming GCG and the prompt-only baseline. However, all algorithms failed to jailbreak GPT-4, indicating its robustness to token-level attacks.

Natural Language Suffixes
Kov produced more natural language suffixes with lower log-perplexity compared to GCG. This was evident in the qualitative examples, where Kov’s suffixes appeared more coherent and interpretable.

Qualitative Examples
Examples of harmful responses generated by the tested LLMs highlighted the importance of developing robust adversarial attack algorithms to uncover and mitigate vulnerabilities.
Overall Conclusion
Summary
The study framed the red-teaming problem for black-box LLMs as an MDP and introduced Kov, an algorithm that combines white-box optimization with tree search and black-box feedback. Kov demonstrated the ability to jailbreak black-box models like GPT-3.5, though it failed against the more robust GPT-4.
Future Work
Future research could incorporate universal components of GCG to optimize for a single adversarial prompt across multiple behaviors and models. Additionally, framing prompt-level attacks as an MDP and using off-the-shelf solvers could further enhance the robustness of LLMs.
Acknowledgements
The authors thank Mykel Kochenderfer, Mert Yuksekgonul, Carlos Guestrin, Amelia Hardy, Houjun Liu, and Anka Reuel for their insights and feedback.
Responsible Disclosure
The prompts and responses of unsafe behavior were shared with OpenAI to ensure responsible disclosure and mitigation of potential risks.
This blog post provides a detailed interpretation of the paper “Kov: Transferable and Naturalistic Black-Box LLM Attacks using Markov Decision Processes and Tree Search,” highlighting the methodology, experimental design, results, and future directions for research in adversarial attacks on LLMs.


