





Authors:
Chengyu Song、Linru Ma、Jianming Zheng、Jinzhi Liao、Hongyu Kuang、Lin Yang
Paper:
https://arxiv.org/abs/2408.08902
Introduction
Insider threats pose a significant challenge in cybersecurity, as they are often carried out by authorized users with legitimate access to sensitive information. Traditional Insider Threat Detection (ITD) methods, which rely on monitoring and analyzing logs, face issues such as overfitting and lack of interpretability. The emergence of Large Language Models (LLMs) offers new possibilities for ITD, leveraging their extensive commonsense knowledge and multi-step reasoning capabilities. However, LLMs face challenges such as handling diverse activity types, overlong log files, and faithfulness hallucination. To address these challenges, the paper introduces Audit-LLM, a multi-agent log-based insider threat detection framework.
Related Work
Log-based Insider Threat Detection
Insider threat detection has been extensively researched, with approaches broadly categorized into traditional methods and deep learning methods. Traditional methods include anomaly-based and misuse-based approaches. Anomaly-based detection, such as Bayesian techniques and one-class techniques, focuses on identifying deviations from normal behavior. Misuse-based methods use similarity measurement to detect insider misbehaviors. Deep learning methods, such as hierarchical neural temporal point processes and heterogeneous graph embedding, have also been explored for ITD. However, these methods often suffer from overfitting and lack interpretability.
LLM for Cybersecurity
LLMs have shown promise in cybersecurity, both as defensive and offensive tools. For instance, systems like AutoAttacker leverage LLMs for automated network attacks, while others enhance strategic reasoning capabilities in cybersecurity. LLMs also demonstrate strong parsing and analytical capabilities for log analysis, as seen in frameworks like LogGPT and methodologies for log file analysis. However, the constrained context length of LLMs and the need for historical context in logs present challenges. Audit-LLM addresses these challenges by utilizing automated tools to extract user behavior characteristics from extensive log datasets.
Research Methodology
Framework Overview
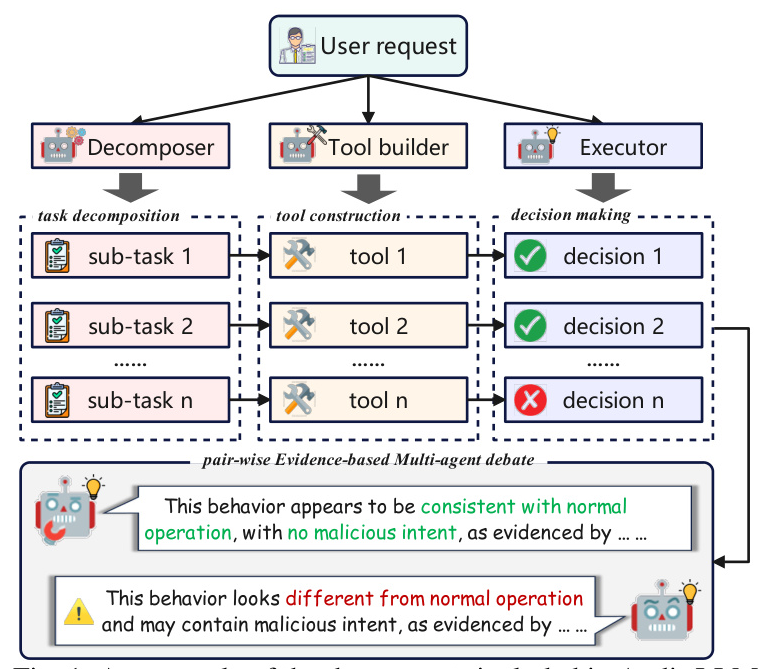
Audit-LLM is a multi-agent collaboration framework consisting of three core agents: the Decomposer, the Tool Builder, and the Executor. The Decomposer reformulates the log auditing task into manageable sub-tasks via Chain-of-Thought (CoT) reasoning. The Tool Builder constructs reusable tools tailored for each sub-task. The Executors dynamically invoke tools to accomplish sub-tasks and refine their conclusions through a pair-wise Evidence-based Multi-agent Debate (EMAD) mechanism.


Task Definition and Decomposition
The ITD task involves analyzing a time-ordered log set to identify malicious activities. The Decomposer agent breaks down the ITD task into multiple sub-tasks, enabling a comprehensive evaluation of user behavior. This approach ensures thorough coverage of potential malicious behavior patterns and enhances the LLM’s reasoning capabilities.
Tool Development and Optimization
The Tool Builder agent constructs sub-task-specific and reusable tools implemented as Python functions. The process involves intent recognition, unit testing, and tool decoration. These tools extract global characteristics for detection, such as login frequency and website legitimacy, improving the final conclusion’s accuracy.
Task Execution
The Executor agent completes sub-tasks by invoking tools in a CoT manner, synthesizing tool-derived results to form the ultimate conclusion. To address faithfulness hallucination, the EMAD mechanism involves two Executors iteratively refining their conclusions through reasoning exchange, achieving a consensus on the final conclusion.

Experimental Design
Research Questions and Experimental Configuration
The experiments aim to answer several research questions, including the performance comparison of Audit-LLM with state-of-the-art baselines, the contribution of each component to model performance, and the impact of diverse LLMs as base models. The experiments are conducted using an Intel Xeon CPU, 256 GB RAM, and four Nvidia RTX A6000 GPUs. The Audit-LLM framework is built using LangChain and evaluated on multiple large language models.
Datasets
Three publicly accessible insider threat datasets are used: CERT r4.2, CERT r5.2, and PicoDomain. These datasets include diverse multi-source activity logs, such as user login/logoff events, emails, file access, website visits, and device usage. The datasets provide a comprehensive evaluation of Audit-LLM’s performance.

Baseline Methods
Several state-of-the-art baselines are compared with Audit-LLM, including LogGPT, LogPrompt, LAN, DeepLog, LMTracker, and CATE. These baselines employ various techniques, such as LLMs, LSTM for sequential data, GNNs for graph structures, and pre-trained Transformers for insider threat detection.
Results and Analysis
Overall Performance
Audit-LLM outperforms the baselines across all datasets, demonstrating significant improvements in precision, detection rate, and accuracy. The results indicate that Audit-LLM effectively reduces false positives and provides consistent gains across different datasets.
Ablation Study
The ablation study shows that removing any component of Audit-LLM leads to a decrease in performance, highlighting the importance of each component. The CoT process and the Decomposer agent contribute significantly to the model’s performance, while the EMAD mechanism helps mitigate faithfulness hallucination.

Impact of Base LLMs
Audit-LLM maintains robust performance across various base LLMs, with GPT-3.5-turbo-0125 achieving the best results. The compatibility of the LangChain framework with GPT-3.5 enhances the precision of the CoT process and tool invocation.


Analysis of Generated Responses
Audit-LLM provides accurate and interpretable responses for various insider threat scenarios. The generated responses help auditors understand the basis of judgments and the final decision, improving the transparency of the detection process.
Case Study
Audit-LLM is deployed in a real-world operational system environment and successfully detects various penetration test activities. The results demonstrate Audit-LLM’s effectiveness in real-world scenarios, identifying suspicious behaviors and providing comprehensive detection capabilities.
Cost Analysis
The cost analysis shows that using LLM APIs for log analysis incurs substantial time and economic costs. GPT-3.5 consumes fewer tokens compared to GLM-4, highlighting the importance of optimizing LLM usage for cost-effective solutions.


Overall Conclusion
Audit-LLM is a multi-agent log-based insider threat detection framework that leverages the extensive knowledge and reasoning capabilities of LLMs. The framework addresses challenges such as handling diverse activity types, overlong log files, and faithfulness hallucination. The experimental results demonstrate Audit-LLM’s superiority over existing baselines, providing accurate and interpretable detection of insider threats. Future work aims to refine agent design, enhance detection accuracy, and integrate a network threat knowledge base for effective mitigation recommendations.



