





Authors:
Matthias Bartolo、Dylan Seychell、Josef Bajada
Paper:
https://arxiv.org/abs/2408.06803
Introduction
Object detection is a fundamental problem in computer vision, involving the identification and localization of objects within images or videos. Despite significant advancements, challenges remain due to the variability in object appearance, occlusion, and lighting conditions. This study explores the integration of reinforcement learning (RL) and saliency ranking techniques to enhance object detection accuracy. By leveraging saliency ranking for initial bounding box prediction and refining these predictions using RL, the study aims to develop faster and more optimized models.
Background
Saliency Ranking
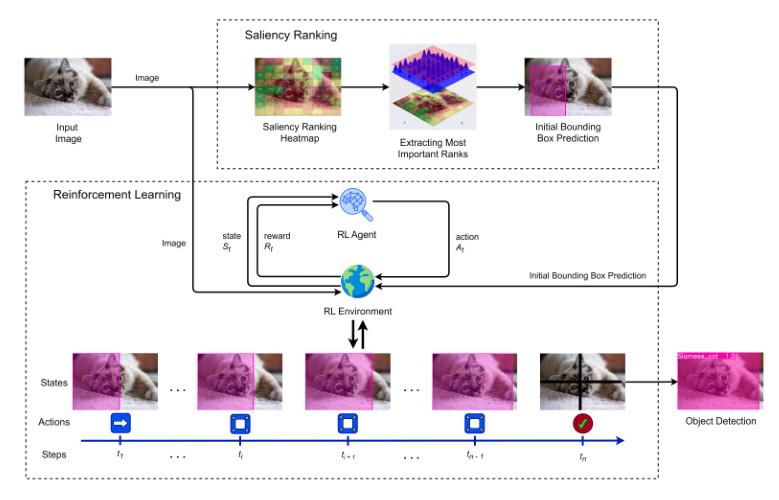
Saliency ranking identifies the most visually significant features within an image. The SaRa technique segments images and ranks their saliency using a grid-based methodology. This process involves generating a saliency map and scoring each segment based on proximity to the image center, entropy, and depth score. The architecture is illustrated in Figure 1.



Feature and Classification Learning
Feature learning, particularly through Convolutional Neural Networks (CNNs), is crucial for image classification. CNNs extract features using convolutional layers and down-sample these features using pooling layers. Popular architectures include ResNet50, VGG16, Inception, Xception, MobileNet, and EfficientNet.
Reinforcement Learning
Reinforcement learning (RL) involves learning to map states to actions to maximize a numerical reward. The RL framework is modeled as an interaction loop where the agent performs actions in an environment based on a policy, receiving rewards and transitioning to new states. The RL interaction loop is depicted in Figure 2.


Deep Q-Network (DQN)
DQN extends Q-learning by using a deep neural network to approximate the optimal value function. The architecture includes a policy network and a target network to stabilize learning. The Dueling DQN architecture further separates the estimation of state values from action advantages, enhancing learning efficiency.
Literature Review
The literature review covers key architectures and methodologies in RL-based object detectors. Early works like “Active Object Localization with Deep Reinforcement Learning” by Caicedo et al. transformed the object detection problem into a Markov Decision Process (MDP). Subsequent studies introduced hierarchical techniques, tree-structured RL agents, and multitask learning policies. Recent advancements include the integration of visual attention mechanisms and bounding box refinement techniques.
Methodology
Reinforcement Learning Framework
The RL framework for object localization was developed using the gymnasium API. The state representation includes a feature vector of the observed region and a history of actions. The action set comprises eight transformations for the bounding box and a trigger action to indicate successful localization. The reward function is based on the Intersection over Union (IoU) between the predicted and ground truth boxes.


Network Architecture
The proposed DQN architecture includes Dropout Layers to mitigate overfitting and a deeper network to enhance decision-making. The Dueling DQN architecture separates state and advantage functions, improving learning efficiency.


Saliency Ranking Integration
Saliency ranking is used to generate initial bounding box predictions. The process involves extracting the most important ranks from the saliency map and creating a bounding box around these regions.


Object Classification
The system includes object classification to provide labels and confidence scores for detected objects. Various architectures like ResNet50, VGG16, Inception, Xception, MobileNet, and EfficientNet are supported.
Transparency
The system provides real-time visualizations and an action log to illustrate the decision-making process during training. This enhances transparency and allows users to observe the bounding box coordinates and action types.


System Overview
The system architecture integrates saliency ranking and RL for object detection. The process flow involves generating a saliency ranking heatmap, creating an initial bounding box prediction, and refining it using RL.


Evaluation
Metrics
The evaluation metrics include Precision, Recall, Average Precision (AP), and Mean Average Precision (mAP). The IoU threshold for evaluation is set to 0.5.
Experiment 1 – Optimal Threshold and Number of Iterations
This experiment determined the optimal threshold and number of iterations for saliency ranking. The results indicated that a 30% threshold and one iteration yielded the best results on the Pascal VOC dataset.


Experiment 2 – Exploration and Saliency Ranking
This experiment evaluated the effects of different exploration modes and the integration of saliency ranking. Random exploration without saliency ranking yielded the highest mAP.


Experiment 3 – Feature Learning Architectures
This experiment assessed the impact of different feature learning architectures. VGG16 performed the best, followed by MobileNet and ResNet50.


Experiment 4 – DQN Agent Architectures
This experiment evaluated various DQN architecture variants. The D3QN agent achieved the highest mAP, demonstrating superior performance.


Comparative Analysis
The trained agents were compared with existing methodologies. The D3QN agent achieved a mAP of 51.4, surpassing previous benchmarks. The results demonstrated significant improvements in single object detection accuracy and efficiency.
Conclusion
The study proposed innovative methodologies to enhance object detection accuracy and transparency. Integrating RL and saliency ranking techniques, the research developed faster and more optimized models. The findings indicated that omitting saliency ranking generally yielded better results, with random exploration and smaller state sizes achieving higher mAP scores. The D3QN agent exhibited the best performance.
Future Work
Future research could explore removing aspect ratio constraints, transitioning to continuous action spaces, and implementing the Rainbow DQN agent. Enhancing transparency and explainability in AI models remains a crucial area for further investigation.


Code:
https://github.com/mbar0075/sarlvision


