





Authors:
Jian Xu、Delu Zeng、John Paisley
Paper:
https://arxiv.org/abs/2408.06699
Introduction
Bayesian learning has seen significant advancements, with models like Student-t Processes (TPs) proving effective for handling heavy-tailed distributions and outlier-prone datasets. However, the computational complexity of TPs limits their scalability. Sparse Variational Student-t Processes (SVTPs) were developed to reduce computational demands while preserving the flexibility and robustness of TPs, making them suitable for large and varied datasets. Traditional gradient descent methods like Adam may not fully exploit the parameter space geometry, potentially leading to slower convergence and suboptimal performance. This paper introduces natural gradient methods from information geometry to optimize SVTPs, leveraging the curvature and structure of the parameter space for more efficient optimization.
Background and Notations
Student-t Processes
A Student-t Process (TP) extends the Gaussian Process (GP) by using the multivariate Student-t distribution, which has heavier tails to better handle outliers and extreme values. The degree of freedom parameter, ν, controls the tail weight, converging to a Gaussian distribution as ν approaches infinity. By adjusting ν, TPs can model various tail behaviors, providing greater flexibility than GPs.
Definition 1
The multivariate Student-t distribution with ν degrees of freedom, mean vector µ, and correlation matrix R is defined as:
[ ST(y|\mu, R, \nu) = \frac{\Gamma\left(\frac{\nu+n}{2}\right)}{|R|^{\frac{1}{2}} \Gamma\left(\frac{\nu}{2}\right) ((\nu-2)\pi)^{\frac{n}{2}}} \left(1 + \frac{(y – \mu)^\top R^{-1} (y – \mu)}{\nu – 2}\right)^{-\frac{\nu+n}{2}} ]
Definition 2
A function ( f ) is a Student-t process with parameters ( \nu > 2 ), mean function ( \Psi ), and kernel function ( k ), if any finite collection of function values has a joint multivariate Student-t distribution.
Sparse Variational Student-t Processes
The Sparse Student-t Process (SVTP) introduces inducing points to summarize data efficiently, reducing computational complexity.
Inducing Points Setup
M inducing points ( Z ) are defined with function values ( u ) following a multivariate Student-t process prior:
[ u \sim T P_M(\nu, 0, K_{Z,Z’}) ]
Training Data and Noise Model
Given N training data points ( (X, y) ), the observed output is defined as ( y_i = f(x_i) + \epsilon_i ) where ( \epsilon_i ) is noise.
Joint Distribution
The joint distribution of ( f ) (function values at training points) and ( u ) are defined as a multivariate Student-t distribution:
[ p(u, f) = ST\left(\nu, \begin{pmatrix} 0 \ 0 \end{pmatrix}, \begin{pmatrix} K_{Z,Z’} & K_{Z,X} \ K_{X,Z} & K_{X,X’} \end{pmatrix}\right) ]
Conditional Distribution
The conditional distribution ( p(f|u) ) is derived to introduce inducing points for efficient computation:
[ p(f|u) = ST\left(\nu + M, \mu, \nu + \frac{\beta – 2}{\nu + M – 2} \Sigma\right) ]
where ( \mu = K_{X,Z} K_{Z,Z’}^{-1} u ), ( \beta = u^\top K_{Z,Z’}^{-1} u ), and ( \Sigma = K_{X,X’} – K_{X,Z} K_{Z,Z’}^{-1} K_{Z,X} ).
Optimization
Monte Carlo sampling and gradient-based optimization are employed to estimate and maximize the variational lower bound ( L(\theta) ):
[ \theta_{t+1} = \theta_t – \lambda_t A(\theta_t) \nabla_\theta L(\theta) |_{\theta=\theta_t} ]
where ( \lambda_t ) denotes the step size and ( A(\theta_t) ) is a suitably chosen positive definite matrix.
The Steepest Descent
To choose the optimal ( A_t ) from the perspective of information geometry, we assume ( \Omega ) is a Riemannian space with a Riemannian metric tensor ( G(\theta) ). The steepest descent direction of a function ( L(\theta) ) at ( \theta ) is defined by the vector ( d\theta ) that minimizes ( L(\theta) ) under the constraint ( |d\theta|_G^2 = \epsilon^2 ).
Lemma 1
The steepest descent direction of ( L(\theta) ) in a Riemannian space is given by:
[ -\tilde{\nabla} L(\theta) = -G(\theta)^{-1} \nabla L(\theta) ]
where ( \tilde{\nabla} L(\theta) = G(\theta)^{-1} \nabla L(\theta) ) is the natural gradient of ( L(\theta) ) in the Riemannian space.
Natural Gradient Learning in SVTP
Fisher Information Matrix as Riemannian Metric Tensor
The Fisher information matrix ( F(\theta) ) serves as a Riemannian metric tensor on the parameter space. It is defined as:
[ F_{ij}(\theta) = E_{p(x;\theta)} \left[ \frac{\partial \log p(x; \theta)}{\partial \theta_i} \frac{\partial \log p(x; \theta)}{\partial \theta_j} \right] ]
Representation of Fisher Information Matrix in SVTP
In the SVTP model, we parameterize ( q_\theta(u) ) as a Student-t distribution with diagonal covariance matrices. The Fisher information matrix ( F(\theta) ) is partitioned into 9 blocks, and the integral parts are calculated using classical multivariate statistical theory and the Beta function.
Fisher Information Matrix Linked to the Beta Function
The Fisher information matrix of the multivariate Student’s t-distribution is linked to the Beta function, establishing a connection termed the ‘Beta Link’.
Stochastic Natural Gradient Descent
Similarly to stochastic gradient descent, in natural gradient descent, we can approximate the entire dataset by leveraging the idea of stochastic gradient descent and using a mini-batch of data:
[ \theta_{t+1} = \theta_t – \lambda_t \frac{B}{N} F(\theta_t)^{-1} \nabla_\theta L_B(\theta) |_{\theta=\theta_t} ]
Our algorithm is outlined in Algorithm 1.
Algorithm 1: Stochastic Natural Gradient Descent for SVTP (SNGD-SVTP)
markdown
Input: training data X, y mini-batch size B, training data size N.
Initialize variational parameters θ = {ν, u, S}, inducing point inputs Z, kernel hyperparameters η.
repeat
Set F(θ)−1 by equation (40)
Sample mini-batch indices I ⊂ {1, . . . , N} with |I| = B
Compute L_B(θ, Z, η) by equation (5)
Do one step Adam optimization on Z, η
Do one step natural gradient descent on θ by equation (41)
until θ, Z, η converge
Experiments
Datasets and Baselines
We utilize four real-world datasets from UCI and Kaggle: Energy, Elevator, Protein, and Taxi. These datasets range in size from a few hundred to several hundred thousand instances. We compare our proposed Stochastic Natural Gradient Descent (SNGD) algorithm against the original SVTP paper’s implementations of SGD and Adam, as well as other Adam variants.
Performance in Real-world Dataset Regression
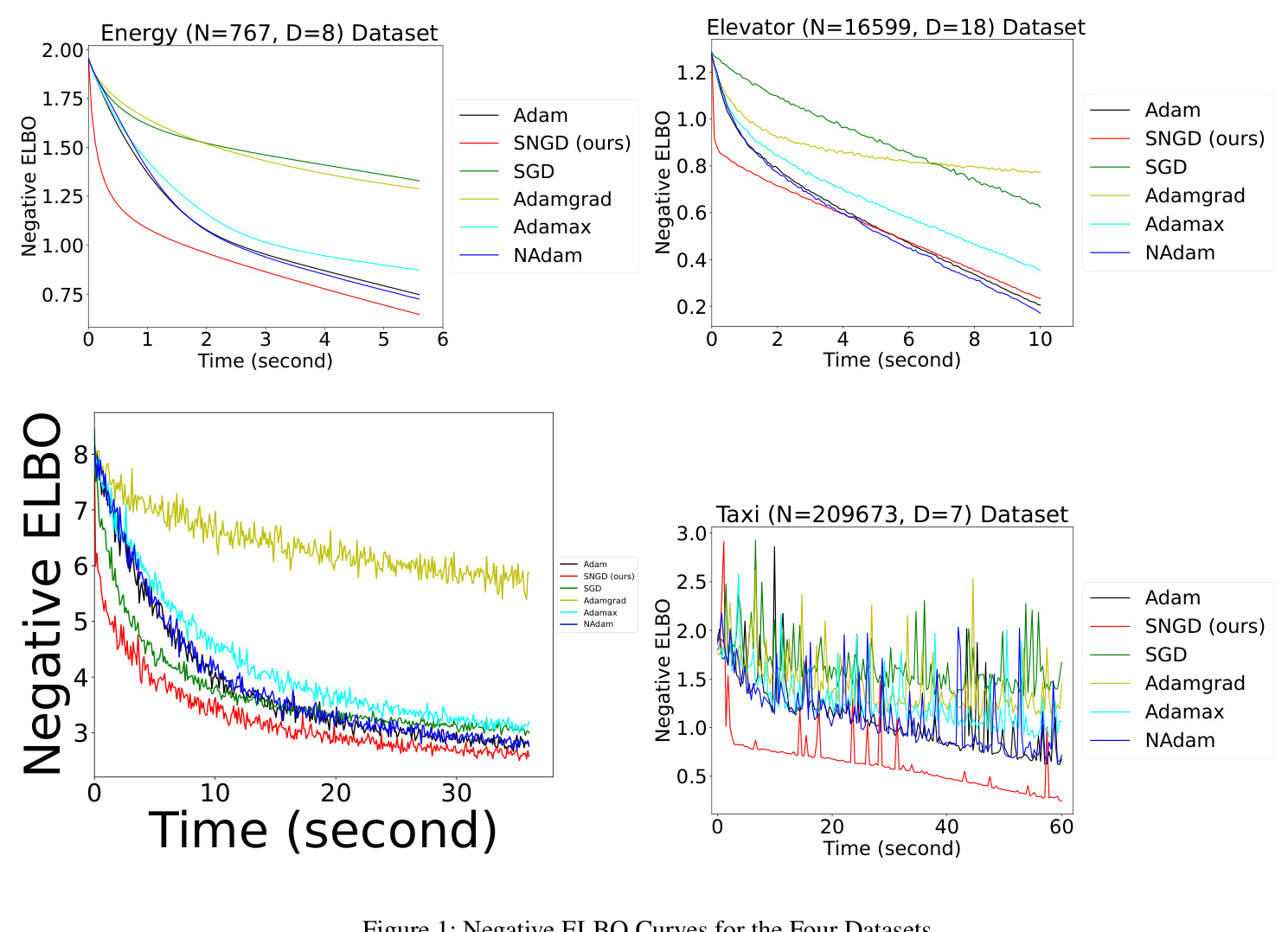
We validate the efficiency of the SNGD algorithm on the training set and present its results in Figure 1, showing the negative ELBO (training loss) curves for the four datasets. Our method consistently achieves the lowest curve positions on three datasets: Energy, Protein, and Taxi, indicating the fastest convergence among the tested algorithms. We also test these algorithms on the testing set, as shown in Figure 2, using Mean Squared Error (MSE) as the metric. Our method consistently performs the best across all datasets in the testing phase, demonstrating superior generalization.

Figure 1: Negative ELBO Curves for the Four Datasets

Figure 2: Test MSE Curves for the Four Datasets
Conclusion
Our study introduces natural gradient methods from information geometry to optimize sparse variational Student-t Processes. This approach harnesses the curvature of the parameter space, leveraging the Fisher information matrix linked to the Beta function in our model. Experimental results across benchmark datasets consistently show that our method accelerates convergence speed compared to traditional gradient descent methods like Adam, thereby enhancing computational efficiency and model flexibility for real-world datasets. We are optimistic about extending this method to more Student’s t natural gradient algorithms.


