





Authors:
Jordan F. Masakuna、DJeff Kanda Nkashama、Arian Soltani、Marc Frappier、Pierre-Martin Tardif、Froduald Kabanza
Paper:
https://arxiv.org/abs/2408.07718
Introduction and Related Work
Unsupervised anomaly detection is a critical area in machine learning, relying on the assumption that training datasets are free from anomalies. However, this assumption often does not hold true in practice, as datasets frequently contain anomalous instances, referred to as contamination. The presence of contamination can significantly undermine the effectiveness and reliability of anomaly detection models.
To address this challenge, robust anomaly detection models have been developed, such as Isolation Forest (IF), Local Outlier Factor (LOF), One-Class Support Vector Machine (OCSVM), Neural Transformation Learning for Deep Anomaly Detection Beyond Images (NeutrALAD), and Deep Unsupervised Anomaly Detection (DUAD). These models aim to mitigate the impact of contamination on performance by relying on accurate contamination ratio information, which indicates the proportion of anomalies within the dataset.
However, contamination ratios are susceptible to inaccuracies due to various factors, such as data collection processes and labeling errors. This raises a critical question: How do these models perform when confronted with misinformed contamination ratios?
Our primary objective is to ascertain the resilience of contamination-robust models to misinformed contamination ratios. Through a meticulous investigation encompassing six benchmark datasets, we aim to shed light on the extent to which contamination-robust models are affected by inaccuracies in contamination ratio estimation. We expect the model’s performance to decline when provided with inaccurately specified contamination ratios.


Discussion and Conclusion
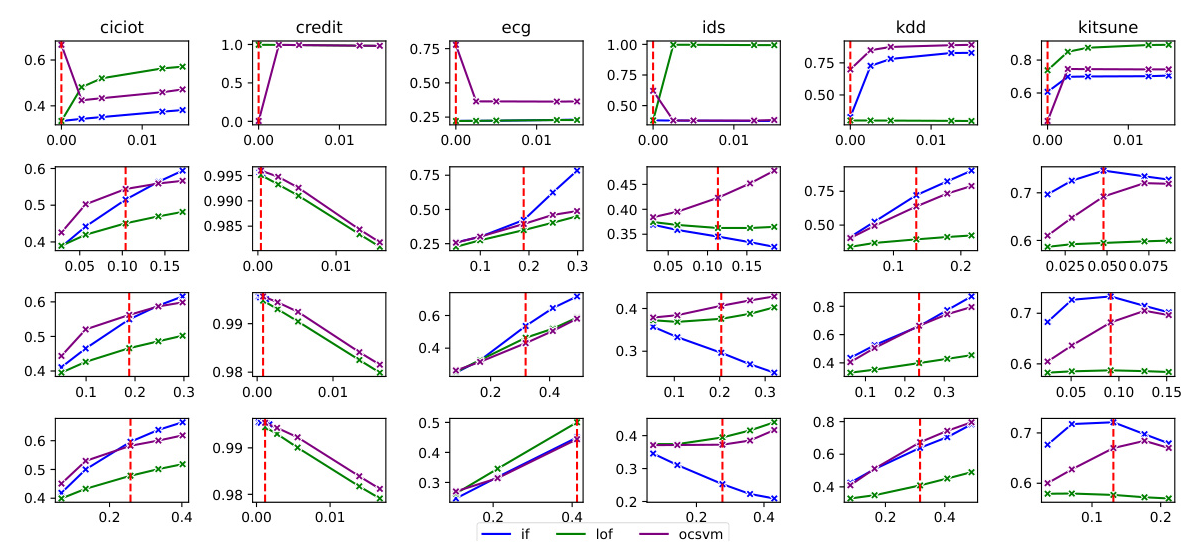
We conducted experiments using six datasets, whose distributions are visualized in Figure 2:
- CICIOT: A real-time dataset containing 33 attacks executed in an IoT network.
- CREDIT: A credit fraud dataset comprising financial transaction records annotated with binary labels indicating fraudulent or legitimate transactions.
- ECG: Consists of recordings of electrical activity of the heart, capturing expected waveform patterns and anomalies.
- IDS: Contains simulated network traffic and several types of attacks.
- KDD: Contains simulated military traffic and several types of attacks.
- KITSUNE: A network attack dataset captured from either an IP-based commercial surveillance system or an IoT network.

For performance evaluation, we focused solely on accuracy since the test data subsets are well-balanced in this binary classification task.
Figure 3 shows the accuracy of models against misinformed contamination ratios. Contrary to expectations, the tested models demonstrated resilience and even outperformed anticipated outcomes under such conditions. These results suggest that the robust unsupervised anomaly detection models under consideration may not necessitate precise contamination ratios to address data contamination. This unexpected robustness suggests a need for deeper investigation into the underlying mechanisms of these models and highlights the importance of reassessing our assumptions in unsupervised anomaly detection research.

Notably, while the expected behavior was observed in some instances (e.g., all three models on CREDIT and IF on IDS), the consistent trend across multiple datasets underscores the significance of these findings and their potential implications for advancing anomaly detection methodologies.
The implications of these unexpected findings are multifaceted and significant. They challenge the prevailing assumptions in anomaly detection research, prompting a reevaluation of the factors that influence model performance. This could lead to the refinement of existing methodologies and the development of more accurate anomaly detection systems. The implications of this study extend beyond anomaly detection alone, offering insights into broader issues of model robustness, reliability, and adaptability in the face of uncertainty in domains such as cybersecurity and fraud detection. Further investigation is needed to grasp the true meaning of these results, including deep models.


