





Authors:
Karthik Shivashankar、Mili Orucevic、Maren Maritsdatter Kruke、Antonio Martini
Paper:
https://arxiv.org/abs/2408.09128
Introduction
Technical Debt (TD) is a critical concept in software development, representing the future cost of additional work due to choosing suboptimal solutions or evolving requirements. Managing TD is essential for maintaining code quality, reducing long-term maintenance costs, and ensuring the overall health of software projects. This study, conducted by Karthik Shivashankar, Mili Orucevic, Maren Maritsdatter Kruke, and Antonio Martini, advances TD classification using transformer-based models. The research focuses on enhancing the accuracy and efficiency of TD identification in large-scale software development by employing multiple binary classifiers combined through ensemble learning.
Related Work
Transformer Models
Transformer architectures, such as BERT and GPT, have revolutionized natural language processing (NLP) by capturing contextual relationships between words in a sentence. These models leverage deep learning techniques to understand and generate human-like text, making them suitable for interpreting software documentation and issue trackers.
Comparison of LLMs and BERT-based Models
Large Language Models (LLMs) like GPT-3 and GPT-4 are known for their generative capabilities, while models like DistilRoBERTa offer a more efficient alternative with reduced computational requirements. The choice between these models depends on the specific requirements of the task, including available computational resources and the complexity of the classification problem.
Research Methodology
Data Mining
The study utilized the GitHub Archive (GHArchive) to accumulate a large dataset of software development issues from January 1, 2015, to May 25, 2024. A carefully crafted regular expression (regex) pattern was employed to identify TD-related issues and specific types of TD from the dataset.
Dataset Processing and Cleaning
The raw data underwent extensive preprocessing and cleaning to prepare it for effective model training. This included duplicate removal, text normalization, noise reduction, and content filtering. The dataset was balanced to ensure robust model training, with equal proportions of positive and negative labels for each TD category.
Model Training
Binary classification models were trained on a balanced dataset using 5-fold cross-validation over five epochs. Individual binary classifiers were trained for each specific TD type, employing an ensemble learning technique to improve predictive performance. For multiclass classification, stratified 5-fold cross-validation was used, and class weights were incorporated to mitigate the impact of class imbalance.
Model Evaluation and Testing with OOD Dataset
The models were evaluated using standard metrics such as accuracy, precision, recall, MCC, AUC ROC, and F1-score on a reserved test set. Additionally, the models were tested against an out-of-distribution (OOD) dataset to determine their generalization capabilities to new, unseen data contexts.
Experimental Design
Planning and Designing the Experiment
The experiment involved training and evaluating transformer-based models on a comprehensive dataset from GitHub Archive Issues, supplemented with industrial data validation. The models’ performance was assessed on both in-distribution and out-of-distribution datasets to ensure practical applicability.
Preparing the Data and Conditions
The dataset was curated by mining GitHub issues labeled with keywords corresponding to various TD types. The data was split into training and testing sets using an 85/15 ratio, maintaining the balance of positive and negative labels within each subset. An OOD dataset was created for robust evaluation.
Results and Analysis
RQ1: Effectiveness of Transformer-Based Models in Classifying TD Issues
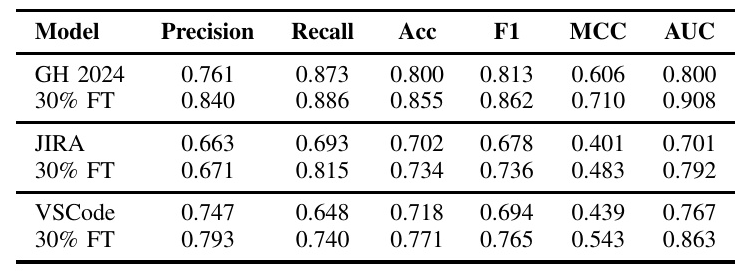
The results demonstrated that the TD (DistilRoBERTa) binary classifier model exhibited consistently high performance on both the test set and the OOD dataset, with precision, recall, and F1 scores all exceeding 0.90. However, a performance drop was observed on the OOD VSCode dataset, highlighting the challenge of domain shift.


RQ1.1: Impact of Fine-Tuning on Model Performance
Fine-tuning the models on project-specific data significantly improved their performance. The fine-tuned models consistently outperformed their non-fine-tuned counterparts across all datasets, with substantial improvements in precision, recall, accuracy, F1-score, MCC, and AUC ROC.

RQ2: Comparison of GPT and DistilRoBERTa Models
The fine-tuned TD DistilRoBERTa model outperformed the out-of-the-box GPT4o model across all metrics, demonstrating the superior performance of the smaller, more efficient DistilRoBERTa model in TD classification tasks.

RQ2.1: Task-Specific Fine-Tuning of GPT Models
The task-specific fine-tuned TD DistilRoBERTa model generally outperformed the larger GPT models across most metrics, highlighting the potential cost-benefit advantage of using more resource-efficient models without significant performance loss.

RQ3: Effectiveness of Expert Ensemble of Binary Classifiers
The binary classifiers demonstrated higher precision and recall in both test and OOD datasets compared to the multiclass model. The ensemble of binary classifiers provided more precise and reliable identification of specific TD types.

RQ 3.1: Performance Comparison Across Different Issue Types
The fine-tuned DistilRoBERTa model demonstrated superior performance in most technical categories compared to GPT-4o, highlighting its effectiveness in classifying various TD issue types.

Overall Conclusion
This study advances the field of TD classification by demonstrating the effectiveness of transformer-based models, particularly DistilRoBERTa, in identifying various TD types. Fine-tuning on project-specific data significantly enhances model performance, and the use of expert binary classifiers provides more precise and reliable identification of TD types. The research highlights the importance of targeted fine-tuning over sheer model size and underscores the practical applicability of the proposed approach in diverse software projects. The release of the curated dataset aims to stimulate further advancements in TD classification research, ultimately enhancing software project outcomes and development practices by enabling early TD identification and management.



