





Authors:
Aman Ahluwalia、Bishwajit Sutradhar、Karishma Ghosh
Paper:
https://arxiv.org/abs/2408.09236
Introduction
In the realm of information retrieval, traditional keyword-based search engines have long been the standard. These engines identify documents containing the queried terms but often fall short in capturing the user’s true intent, leading to irrelevant results. This paper introduces a novel hybrid search approach that leverages the strengths of non-semantic search engines, Large Language Models (LLMs), and embedding models to address these limitations. The proposed system integrates keyword matching, semantic vector embeddings, and LLM-generated structured queries to deliver highly relevant and contextually appropriate search results. By combining these complementary methods, the hybrid approach effectively captures both explicit and implicit user intent.
Related Work
Traditional Keyword-Based Search
Traditional keyword-based search engines, such as BM25, focus on identifying documents that contain the queried terms. While effective in many scenarios, these methods often struggle with understanding the user’s true intent, handling synonyms, and dealing with paraphrases.
Semantic Search and Transformers
Semantic search represents a paradigm shift in information retrieval by transcending the limitations of traditional keyword-based approaches. At its core, semantic search hinges on two crucial components: the search function and semantic understanding. The introduction of Transformers, a powerful deep learning architecture, revolutionized search by enabling semantic understanding. Through Transformers, semantic search can grasp the underlying meaning and intent behind both the user’s query and the retrieved documents, ultimately leading to a more accurate and relevant search experience.
Sentence Embedding Techniques
Sentence embedding techniques have emerged as a powerful tool for semantic search, enabling retrieval based on semantic similarity rather than exact keyword matches. However, these methods can be susceptible to noise introduced by irrelevant words within the query or documents, potentially hindering retrieval accuracy. Furthermore, sentence embeddings can face challenges when dealing with very short or long queries.
Research Methodology
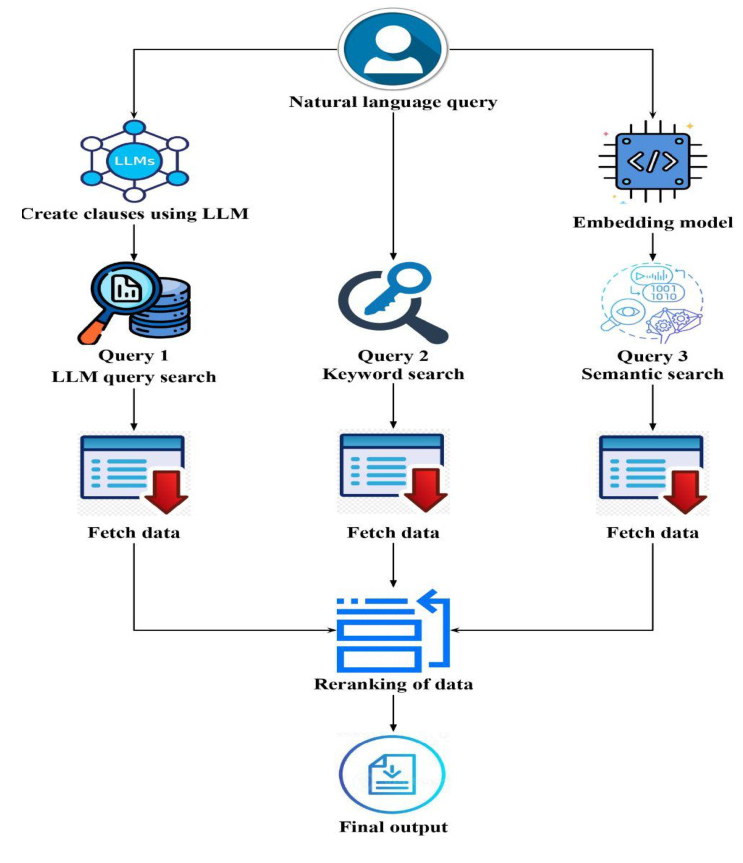
The Hybrid Approach
The hybrid search model introduced in this paper merges three complementary search methodologies to optimize document retrieval:
- LLM-Based Structured Query Generation: This step leverages the language model’s ability to understand and interpret user intent, transforming ambiguous queries into precise search terms.
- Keyword Search: This method identifies documents containing exact matches to the query terms, ensuring high recall.
- Semantic Search Using Vectors: This approach captures the underlying meaning and context of the query, expanding the search space to include semantically related documents.
By combining these distinct approaches, the model comprehensively addresses various query types and retrieval challenges. The resulting search results are then meticulously reranked to prioritize documents that most closely align with the user’s information need.
Experimental Design
LLM-Based Structured Query Generation
- Understanding the User Query: The LLM parses the query to understand its underlying components, identifying key elements within the query.
- Extracting Relevant Entities and Attributes: The LLM extracts specific entities and attributes that are pertinent to the search.
- Generating the Structured Query: Using the extracted entities and attributes, the LLM constructs a structured query in a format that can be easily processed by the search engine.
Keyword Search
- Tokenization of the User Query: The query is broken down into individual tokens.
- Query Expansion (Optional): Synonyms or related terms are added to the original query to increase the chances of retrieving relevant documents.
- Matching Tokens with Document Text: The search engine scans the corpus of documents to find matches for the query tokens.
- Scoring and Ranking: Each document is assigned a relevance score based on the number and quality of keyword matches.
Semantic Search Using Vectors
- Generating Query Embeddings: The query is converted into an embedding vector that captures its semantic meaning.
- Document Embeddings: Each document in the corpus is pre-processed to generate its own embedding vector.
- Cosine Similarity Search: The search engine retrieves documents whose vectors have the highest cosine similarity to the query vector.
- Ranking Based on Semantic Relevance: The documents retrieved through semantic search are ranked based on their similarity scores.
Reranking of Results
- Aggregation of Results: The documents retrieved by the three methods are aggregated into a single list.
- Reciprocal Rank Fusion (RRF) Algorithm: The RRF algorithm merges ranked lists from different search engines or methods, giving higher rank to documents that are ranked highly across multiple lists.
- Final Output: The final output is a reranked list of documents that represent the best combination of keyword matches, structured query results, and semantic relevance.


Results and Analysis
Improved Retrieval Accuracy
The combination of structured queries, keyword matching, and semantic embeddings led to more accurate retrieval results, particularly in scenarios where traditional keyword-based search would struggle to understand user intent.
Robustness Across Query Types
The hybrid model demonstrated robustness across different types of queries, including short, long, and ambiguous queries. While keyword search excelled in matching specific terms, the LLM and semantic searches provided the necessary context to improve overall relevance.
Performance Considerations
Although the hybrid approach introduces additional computational steps, the benefits in terms of retrieval accuracy outweigh the costs. Furthermore, the reranking process ensures that the final results are both comprehensive and efficient.
Overall Conclusion
This paper presents a novel hybrid search model that integrates LLM-based query structuring, keyword search, and semantic vector search to enhance document retrieval accuracy. By addressing the limitations of traditional keyword-based search engines and capitalizing on the strengths of semantic understanding, the proposed model offers a more comprehensive approach to information retrieval. The hybrid search model demonstrated its effectiveness in various scenarios, consistently delivering relevant and contextually appropriate search results. The use of the Reciprocal Rank Fusion algorithm for reranking further optimized the final output, ensuring that the most pertinent documents are prioritized.
Future work could explore the application of this hybrid model to more specialized domains, as well as the integration of additional machine learning techniques for further refinement. Additionally, optimizing the computational efficiency of the hybrid model remains an area for ongoing research.


