





Authors:
Paper:
https://arxiv.org/abs/2408.08160
Introduction
The dream of an intelligent household robot that can manage and organize clothes is becoming more tangible with recent advancements in robotics. However, the challenge remains in developing a robot that can generalize its manipulation skills to a wide range of clothes and tasks. Traditional methods often fail when faced with new tasks or different types of clothing. This paper introduces a novel approach that leverages language instructions and a hierarchical learning method to enhance the generalization of clothes manipulation tasks.


Challenges in Clothes Manipulation
Clothes manipulation is inherently complex due to the sequential nature of the required actions and the high dimensionality of the state space. Different types of clothing have varied geometric structures, making it difficult to create a one-size-fits-all solution. The proposed method addresses these challenges by decomposing the manipulation tasks into three hierarchical levels: planning, grounding, and action.
Related Work
Learning for Deformable Object Manipulation
Previous research has focused on task-specific skills for manipulating deformable objects like ropes, cloths, and bags. These methods often use goal images to specify tasks, but they struggle to generalize to new goals. Unlike these approaches, the proposed method uses language instructions to specify and decompose tasks, enhancing generalization.
Language-conditioned Object Manipulation
Language provides an intuitive interface for human-robot interaction and can capture transferable concepts between different tasks. While previous work has focused on rigid objects, this paper extends language-conditioned manipulation to deformable objects like clothes.
State Representation of Deformable Objects
Effective state representation is crucial for manipulating deformable objects. Traditional methods use particles and mesh representations, but these can be high-dimensional and less effective for policy learning. This paper explores the use of semantic keypoints, which offer a lower-dimensional and more effective state representation for clothes.
Method
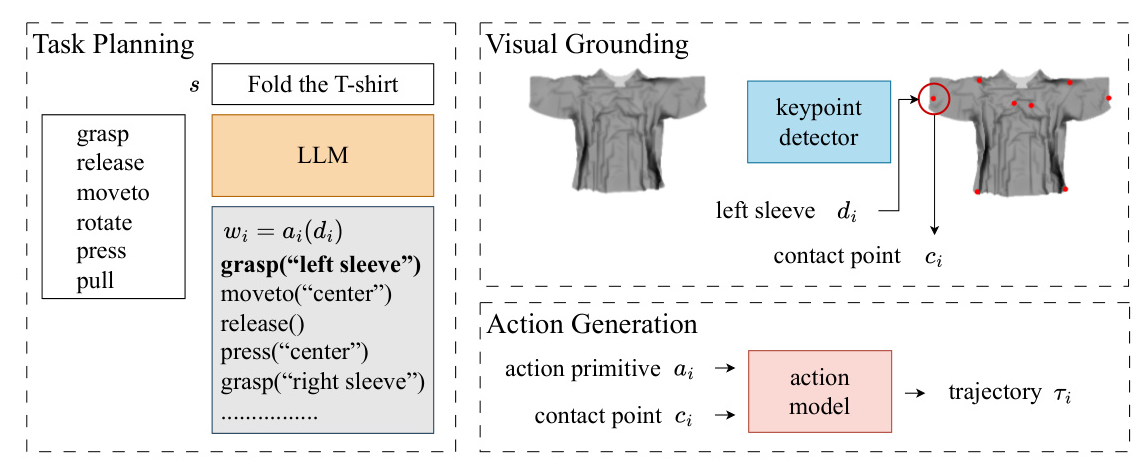
The proposed hierarchical learning method decomposes the problem of generating action trajectories for clothes manipulation into three levels: task planning, visual grounding, and action generation.

Task Planning
Large Language Models (LLMs) are used for task planning due to their extensive commonsense knowledge. The LLM is prompted to provide examples of clothes manipulation tasks, decompose these tasks into basic actions, and identify action primitives like grasp, release, moveto, rotate, press, and pull. These action primitives are then used to generate sub-tasks.
Visual Grounding
The visual grounding layer detects keypoints from observations and grounds contact point descriptions. A masked autoencoder is used to handle occlusion by learning a powerful spatiotemporal representation. The keypoint detector is fine-tuned to detect effective semantic keypoints, which are then used to ground contact points based on their descriptions.

Action Generation
The action model generates trajectories conditioned on action primitives and contact points. This model is based on manually designed rules to ensure accurate execution of the planned tasks.
Experiments
Simulation Experiment Setup
The proposed method was evaluated using the SoftGym benchmark, which was extended to include 30 common clothes manipulation tasks. These tasks were categorized by complexity into easy, medium, and hard tasks. The success metric was the mean particle position error between the achieved clothes states and an oracle demonstrator.
Simulation Experiment Results
The proposed method outperformed the baseline method, CLIPORT, in both seen and unseen tasks, especially as task complexity increased. The hierarchical learning approach enabled better generalization by learning transferable language and visual concepts across different tasks.

Conclusion
This paper presents a hierarchical learning method for generalizable clothes manipulation, leveraging language instructions and a large language model for task planning. Semantic keypoints are used for state representation, enabling effective manipulation under occlusion. The proposed method demonstrated superior performance in simulation experiments, showing promise for generalizing to unseen tasks with new object categories or requirements. Future work will explore generalization on object instances and closed-loop task planning for clothes manipulation.


