





Authors:
Paper:
https://arxiv.org/abs/2408.06509
Introduction
Explainable AI (XAI) methods, such as SHAP, are crucial for uncovering feature attributions in black-box models. These methods help identify if a model’s predictions are influenced by “protected features” like gender or race, which can indicate unfairness. However, adversarial attacks can undermine the effectiveness of these XAI methods. This paper introduces a novel family of data-agnostic attacks called shuffling attacks, which can adapt any trained machine learning model to fool Shapley value-based explanations. The authors demonstrate that Shapley values cannot detect these attacks, though algorithms estimating Shapley values, such as linear SHAP and SHAP, can detect them to varying extents.
Related Work
The paper builds on existing research that modifies a base function without accessing its training data to create an adversarial function that alters the input’s outcome. The proposed method is unique as it does not require data access, unlike previous approaches that rely on data poisoning or scaffolding techniques. The shuffling attacks are designed to be executed by model distributors or brokers, making them more versatile and harder to detect.
Attack Strategies
Shapley Values
Shapley values, originating from cooperative game theory, attribute payouts to a game’s players. In the context of machine learning, they measure the contribution of each feature to the model’s output. The paper explains the mathematical formulation of Shapley values and how they are calculated.
Adversarial Shuffling
Shuffling attacks exploit the order-agnostic nature of expectation calculations in value functions. By shuffling the output vector based on a protected feature, the attacks ensure that the Shapley value for that feature remains zero, effectively hiding its influence on the model’s predictions.
Algorithmic Implementation
The paper provides pseudocode for three types of shuffling attacks: Dominance, Mixing, and Swapping. Each attack manipulates the output scores based on the protected features, giving unfair advantages to certain groups. The Dominance attack ensures that all male candidates receive higher scores than female candidates. The Mixing attack gives male candidates a higher probability of receiving higher scores. The Swapping attack swaps the scores of male and female candidates to ensure males receive higher scores.
Techniques to Modify the Attacks
The paper discusses techniques to relax the attacks and make them less detectable. These include restricting the attack’s frequency, count, and region. Additionally, the attacks can be modified to target in-distribution data if the adversary has access to the training data.
Estimating SHAP’s Detection Capability
The authors demonstrate that estimation algorithms for Shapley values can detect non-zero attributions from shuffling attacks. They provide a theoretical framework for estimating the effectiveness of these attacks using linear models and show that the detection capability varies based on the attack and the underlying data.
Experiments
Datasets
The experiments use three real-world datasets: Graduate Admission Data, Diabetes Risk Data, and German Credit Data. Each dataset includes both scoring and protected features.
Graduate Admissions Prediction
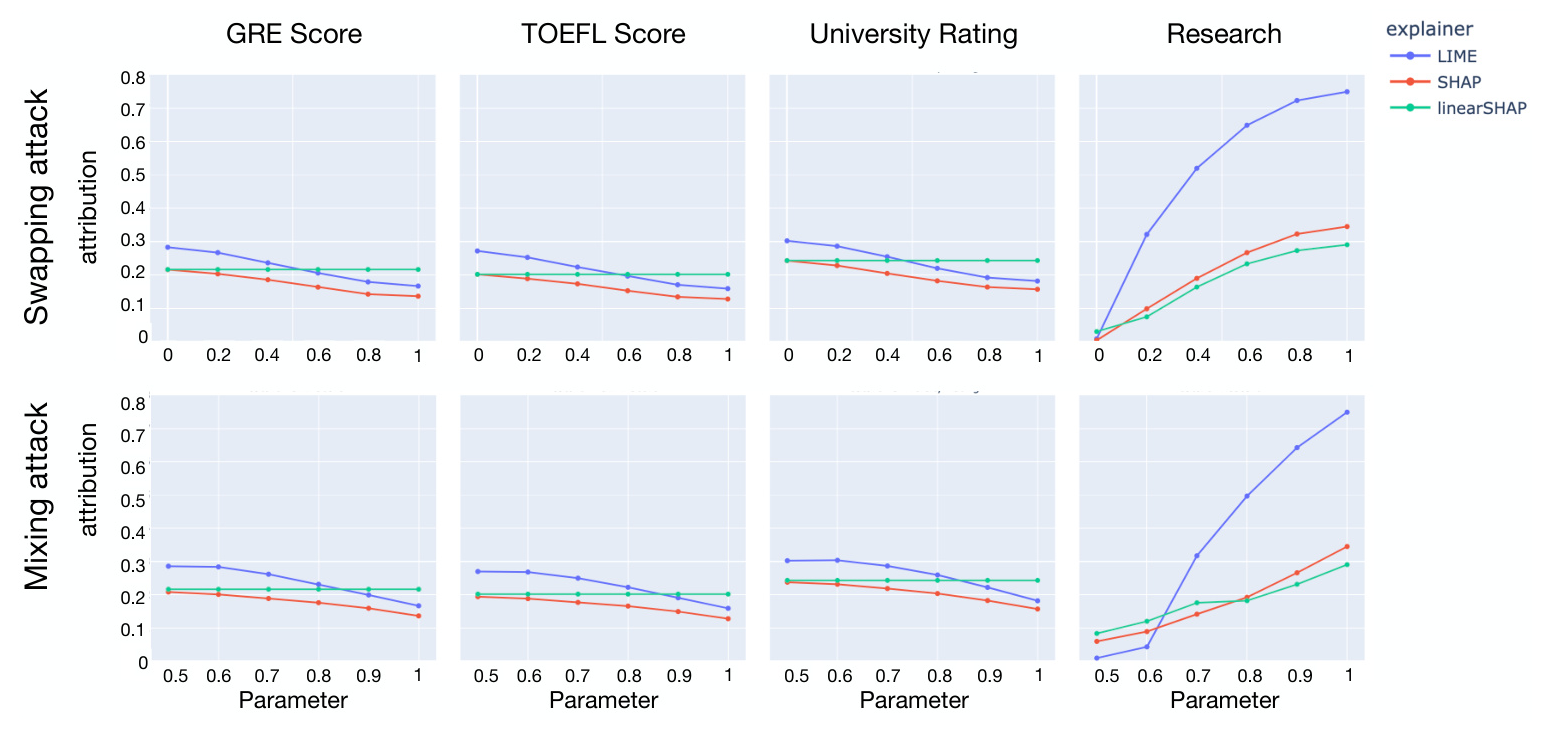
The experiments on the Graduate Admission Data demonstrate the characteristics of the three attacks. The results show that the Dominance attack is the most effective, followed by the Mixing and Swapping attacks. The detection capabilities of different explainers (LIME, SHAP, and linearSHAP) are compared, showing that SHAP and linearSHAP are more effective at detecting the attacks than LIME.


Diabetes Prediction
The experiments on the Diabetes Risk Data demonstrate the effectiveness of hybrid attacks using combinations of Dominance, Mixing, and Swapping algorithms. The results show that attacks using both gender and age as protected features are more effective at hiding unfairness. The fairness metrics drop significantly under these attacks, indicating their impact on model fairness.

Credit Prediction
The experiments on the German Credit Data show that the Dominance attack can achieve similar results to scaffolding deception by targeting the top-k percent region of the data. This attack is effective for decisions based on top instances and remains persistent even with data shifting.

Discussion
The paper highlights the robustness of shuffling attacks under data shifting and their ability to fool SHAP. It also discusses potential defenses against these attacks, such as using incomplete coalitions or heuristic feature attribution methods like LIME. The authors emphasize the need for future research to develop robust detection methods for more complex shuffling attacks and explore the cascading impact of unfair scoring functions.
Conclusion and Future Work
The paper concludes that shuffling attacks are powerful enough to fool SHAP and other XAI methods. Future work will focus on developing robust detection methods, exploring the impact of shuffling attacks on higher-order Shapley values, and designing XAI methods to explain model unfair behaviors. The authors also plan to develop a testing framework and user interface for conducting attacks on XAI methods and investigating fairness-preserving interventions.
Ethical Statement
The authors aim to raise awareness about the risks of using Shapley value-based feature attribution explanations in auditing black-box machine learning models. They acknowledge the potential misuse of their proposed attacks but believe that their work will foster the development of trustworthy explanation methods and contribute to the research on auditing the fairness of AI-based decision systems.



