





Authors:
Max Nelson、Shannon Wotherspoon、Francis Keith、William Hartmann、Matthew Snover
Paper:
https://arxiv.org/abs/2408.06484
Introduction
Cross-lingual conversational speech summarization is a challenging task due to the scarcity of resources. While transcriptions exist for many languages, translated conversational speech is rare, and datasets containing summaries are non-existent. This paper builds upon the Fisher and Callhome Spanish-English Speech Translation corpus by supplementing the translations with summaries generated using GPT-4. The goal is to generate similar summaries despite transcription and translation errors. The paper presents a baseline cascade-based system using open-source speech recognition and machine translation models, tests a range of LLMs for summarization, and analyzes the impact of transcription and translation errors. The Mistral-7B model, when adapted for this task, performs significantly better than off-the-shelf models and matches the performance of GPT-4.
Technical Approach and Dataset Creation
Datasets
The study focuses on the Fisher and Callhome corpora of Spanish conversational telephone speech (CTS). These corpora contain crowd-sourced English translations of Spanish telephone calls. The existence of English reference translations is critical as they are used for reference summary generation. The Callhome corpus comes with a predefined train/test split, while the Fisher data adopts the data splits defined by Post et al. The results are reported across both Callhome test splits (Devtest, Evltest) and all three Fisher test splits (Dev, Dev2, Test).


Summary Generation
Human-generated translations exist for this dataset, but there are no existing summaries. Collecting human summaries would be expensive and time-consuming, so summaries are generated using GPT-4. GPT-4 is given access to reference translations when generating the summaries. During evaluation, an LLM will be given input that contains both ASR and machine translation (MT) errors. The goal is to generate a summary from errorful input that can match the reference summary. For both the training and test sets, GPT-4 generates four total summaries for each test conversation by sampling outputs with a temperature of 0.5. The context, prompt, and a reasonable length summary all fit within a context window of 2048 tokens. If a conversation exceeds the 1200-word limit, it is split into equal-sized chunks and treated as separate conversations. The summaries range in size from 144 to 443 words, with a median size of 268 words.

LLM Adaptation
The study tests off-the-shelf LLMs and experiments with supervised fine-tuning for task adaptation. LoRA fine-tuning is used to adapt the models, with all fine-tuning experiments run with 4-bit quantization and fp16 precision. A LoRA adaptor is learned for every linear layer in the model with r = 64. The training data are GPT-4 reference summaries paired with either the reference English transcripts (Ref) or the outputs of the Whisper-NLLB speech translation system (MT from ASR). The study varies which inputs are used during fine-tuning to evaluate the extent to which domain-matched input improves summarization quality.
Experimental Setup
ASR Model
The Whisper-large-v3 model is used for ASR. While a dataset and language-specific model could likely outperform the Whisper model in the CTS domain, the Whisper model is chosen due to its wide use and reproducibility. The WER of the Whisper model on each of the five test sets is shown in the second column of Table 2.

MT Model
The NLLB 1.3 Billion parameter dense model is used for machine translation. As with Whisper for ASR, a domain-specific model would likely outperform the NLLB model on CTS, but NLLB is used for better reproducibility. The BLEU scores for NLLB on the test sets are shown in Table 2. The third column uses the Whisper ASR output as input to NLLB, while the last column uses the reference Spanish transcriptions.

LLMs for Summarization
GPT-4 is used to generate the reference summaries. A range of open-source and API-based models are evaluated against the GPT-4 generated references. The API-based models considered are GPT-3.5 and GPT-4. The open-source models considered are the 7 and 13 billion parameter versions of Llama 2, the 7 billion parameter Mistral, and the 45 billion mixture-of-experts model Mixtral-8×7. All inference is run with 4-bit quantization and fp16 precision. All open-source models tested are the officially released chat or instruct-tuned versions.
Results
Zero-shot
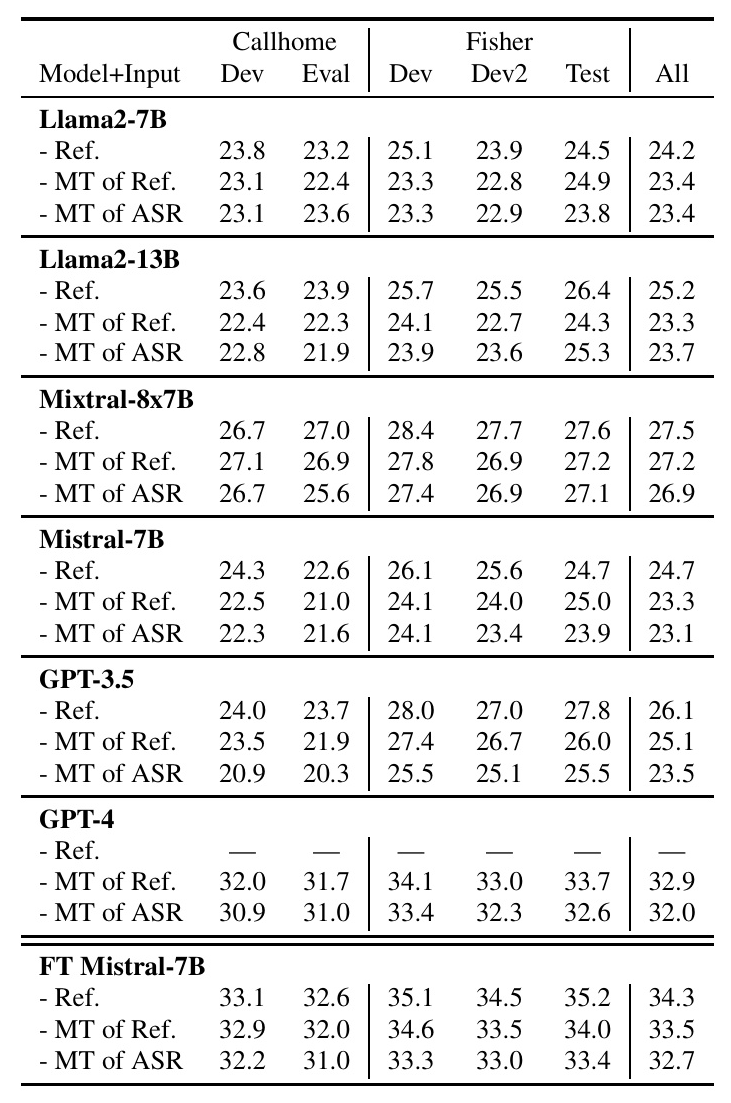
The quality of summaries is evaluated with ROUGE-L. Baseline results are shown in Table 3. Each row represents a different input condition. The performance of each model becomes progressively worse as more error is introduced through MT and ASR, but the drop in performance is less than anticipated. The performance of the open-source models follows the expected ranking, with the larger MoE model Mixtral outperforming the smaller, dense Mistral and Llama 2 models. The performance of the open-source models is impressive, with Mixtral outperforming GPT-3.5 across input types. GPT-4 obtains a ROUGE-L score almost 50% higher than some of the competing open-source models.

Finetuning
Fine-tuning improves the performance of the Mistral-7B model by almost 10 ROUGE points, making it comparable to or even outperforming GPT-4. Table 4 shows performance when fine-tuning on only the reference transcripts, only the MT of ASR transcripts, and the combination of both. The results indicate that fine-tuning on reference transcripts yields the best performance for summarizing reference transcripts, although the differences are small. Table 5 shows how performance varies as the amount of fine-tuning data increases, with a roughly linear increase in ROUGE.

An example summary using GPT-4 with input from reference translations or ASR+MT highlights the issues introduced through ASR and MT errors. Errors in ASR+MT not only impact the factual information in the summary but also the implied tone.
Conclusions
The study establishes an evaluation framework for CTS summarization and creates reference summaries for a well-known Spanish CTS corpus with existing English translations using GPT-4. The experiments establish a baseline for a cascaded approach to summarization using publicly available models. While GPT-4 outperforms existing open-source models, fine-tuning the Mistral-7B model matches GPT-4’s performance. Future work will explore contextual summarization and incorporating additional information based on alternative hypotheses for both transcription and translation.
References
- Zhang, T., Ladhak, F., Durmus, E., Liang, P., McKeown, K., & Hashimoto, T. B. (2024). Benchmarking large language models for news summarization. Transactions of the Association for Computational Linguistics, 12, 39-57.
- Valenza, R., Robinson, T., Hickey, M., & Tucker, R. (1999). Summarisation of spoken audio through information extraction. In ESCA Tutorial and Research Workshop (ETRW) on Accessing Information in Spoken Audio.
- Koumpis, K., & Renals, S. (2000). Transcription and summarization of voicemail speech. In ICSLP. International Speech Communication Association.
- Hori, C., Furui, S., Malkin, R., Yu, H., & Waibel, A. (2002). Automatic summarization of English broadcast news speech. In Proceedings of the second international conference on Human Language Technology Research (pp. 241-246).
- Murray, G., Renals, S., & Carletta, J. (2005). Extractive summarization of meeting recordings. In Proc. Interspeech 2005 (pp. 593-596).
- Sharma, R., Chen, W., Kano, T., Sharma, R., Arora, S., Watanabe, S., Ogawa, A., Delcroix, M., Singh, R., & Raj, B. (2023). Espnet-summ: Introducing a novel large dataset, toolkit, and a cross-corpora evaluation of speech summarization systems. In 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) (pp. 1-8). IEEE.
- Zou, Y., Zhao, L., Kang, Y., Lin, J., Peng, M., Jiang, Z., Sun, C., Zhang, Q., Huang, X., & Liu, X. (2021). Topic-oriented spoken dialogue summarization for customer service with saliency-aware topic modeling. In Proceedings of the AAAI Conference on Artificial Intelligence, 35(16), 14665-14673.
- Furui, S., Kikuchi, T., Shinnaka, Y., & Hori, C. (2004). Speech-to-text and speech-to-speech summarization of spontaneous speech. IEEE Transactions on Speech and Audio Processing, 12(4), 401-408.
- Kano, T., Ogawa, A., Delcroix, M., Matsuura, K., Ashihara, T., Chen, W., & Watanabe, S. (2023). Summarize while translating: Universal model with parallel decoding for summarization and translation. In 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) (pp. 1-8). IEEE.
- Liu, F., & Liu, Y. (2013). Towards abstractive speech summarization: Exploring unsupervised and supervised approaches for spoken utterance compression. IEEE Transactions on Audio, Speech, and Language Processing, 21(7), 1469-1480.
- Post, M., Kumar, G., Lopez, A., Karakos, D., Callison-Burch, C., & Khudanpur, S. (2013). Improved speech-to-text translation with the fisher and callhome Spanish–English speech translation corpus. In Proc. IWSLT.
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2022). Lora: Low-rank adaptation of large language models. In ICLR.
- Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. (2023). Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning (pp. 28492-28518). PMLR.
- Costa-jussà, M. R., Cross, J., Çelebi, O., Elbayad, M., Heafield, K., Heffernan, K., Kalbassi, E., Lam, J., Licht, D., Maillard, J., et al. (2022). No language left behind: Scaling human-centered machine translation. arXiv preprint arXiv:2207.04672.
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. (2022). Training language models to follow instructions with human feedback.
- Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. d. l., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. (2023). Mistral 7b. arXiv preprint arXiv:2310.06825.
- Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., Casas, D. d. l., Hanna, E. B., Bressand, F., et al. (2024). Mixtral of experts. arXiv preprint arXiv:2401.04088.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35, 24824-24837.
- Lin, C.-Y., & Och, F. J. (2004). Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In Proceedings of the 42nd annual meeting of the association for computational linguistics (ACL-04) (pp. 605-612).
- Fabbri, A. R., Kryściński, W., McCann, B., Xiong, C., Socher, R., & Radev, D. (2021). Summeval: Re-evaluating summarization evaluation. Transactions of the Association for Computational Linguistics, 9, 391-409.


