





Authors:
Oscar Dilley、Juan Marcelo Parra-Ullauri、Rasheed Hussain、Dimitra Simeonidou
Paper:
https://arxiv.org/abs/2408.08214
Introduction
Federated Learning (FL) is a privacy-enhancing technology that allows distributed machine learning (ML) by training models locally and aggregating updates, thus bypassing centralized data collection. This approach is increasingly popular in sectors like healthcare, finance, and personal computing. However, FL inherits fairness challenges from classical ML and introduces new ones due to differences in data quality, client participation, communication constraints, aggregation methods, and underlying hardware. Addressing these challenges, the paper proposes Federated Fairness Analytics—a methodology for measuring fairness in FL systems.
Technical Background
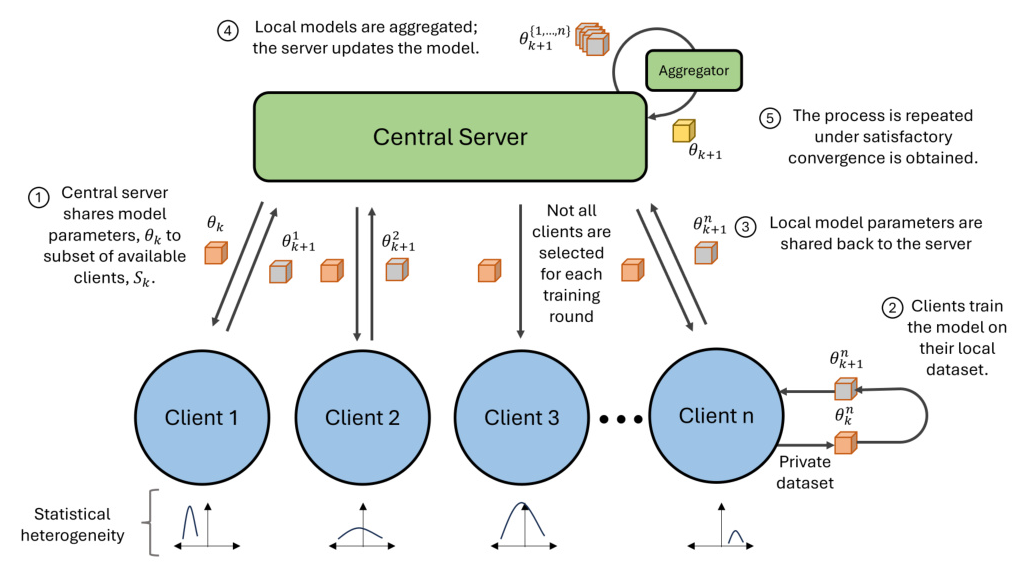
To define the fairness problem and the effects of heterogeneity, the paper considers a typical FL system architecture. In each training round, a central server selects a subset of clients to participate. Each client trains the model on its local dataset and sends the updated parameters back to the server, which aggregates them to update the global model. This process is repeated until satisfactory convergence is achieved.


The paper assumes a centrally orchestrated, horizontal FL system where the feature space is consistent across clients. The system is task-agnostic, and the sensitive attributes are known to both clients and the server. Clients are treated as black boxes with no information about their database size, dataset distribution, or communication capability.
Related Work
Existing Definitions of Fairness
Fairness in centralized ML is a well-established problem, but FL demands its own set of definitions due to its additional complexity. Existing research offers various approaches to fair-FL, but they often define fairness narrowly. The paper builds on these definitions to propose a more comprehensive, measurable, and symptom-driven definition of fairness in FL.
Methods to Measure Fairness
Metrics are required to measure fairness. Some centralised metrics, such as disparate impact, demographic parity, equalised odds, and equal opportunity, are still insightful in the context of individual client performance in FL. The paper uses Jain’s Fairness Index (JFI) to measure uniformity and Shapley values to measure client contributions.
Fairness Conscious Approaches to FL
Several existing works propose novel approaches to address aspects of the fairness problem in FL. These approaches target uniformity of accuracy achieved by clients in classification tasks or mitigate discrimination against protected groups. However, none of these approaches attempt to quantify or solve the full spectrum of fairness concerns.
Proposed Techniques to Quantify Fairness
The paper proposes four notions of fairness, each with an associated metric:
- Individual Fairness: Measures if all clients perform proportionately to their contribution using JFI.
- Protected Group Fairness: Measures if subgroups of the population with sensitive attributes perform equivalently to those without using equalised odds difference metrics.
- Incentive Fairness: Measures if clients are rewarded proportionately to their contributions using JFI.
- Orchestrator Fairness: Measures if the server succeeds in orchestrating a learning ecosystem that maximizes the objective function.

These notions address the limitations of previous definitions and are symptomatically defined and easily quantified. The paper also introduces a general fairness metric, ( F_T ), which is a weighted sum of the four notions of fairness.
Experimental Design
The experimental work aims to test the fairness metrics on a wide range of FL scenarios. The experiments vary in FL approach, ML task, data setting, and heterogeneity. The paper selects the most prominent FL approaches, datasets, and models for experimentation.
FL Approaches
The paper evaluates a pair of the most promising approaches from the literature against the baseline approach, FedAvg. The selected approaches are q-FedAvg and Ditto, which are known for their fairness-conscious designs.
Data Sets and Models
The paper uses the following datasets and models:
- CIFAR-10: A dataset of 60,000 32×32 pixel color images of 10 classes, using a CNN model.
- FEMNIST: A dataset of 805,263 28×28 pixel images of handwritten characters, using a CNN model.
- NSL-KDD: A dataset of 185,400 internet traffic records with 42 attributes, using a binary classification model.
Introducing Heterogeneity
The datasets are split across clients with both iid and non-iid partitioning to modulate statistical heterogeneity. The experiments sample 5 clients per round with varying sample rates.

Results and Discussion
Federated Fairness Analytics enables the quantification, explanation, and visualization of fairness in FL systems. The results demonstrate that fairness is sensitive to the approach, data setting, and heterogeneity. Key insights include:
- Fairness is invariant with the change from FedAvg to q-FedAvg in iid settings.
- Statistical heterogeneity degrades fairness performance with FedAvg.
- Fairness is not static through training time, showing sporadic behavior in early rounds and settling later.

Fairness-Performance Trade-off
The results show a trade-off between fairness and performance. For example, Ditto trades performance for fairness in the FEMNIST task, while q-FedAvg offers the best fairness and performance in the NSL-KDD task.

Conclusion
Fairness remains an unsolved problem in FL. The paper defines and measures fairness in FL systems using four complete, symptom-driven notions. The proposed Federated Fairness Analytics methodology enables fairness-explainable-AI by providing insights into the effects of design decisions on fairness. The results demonstrate that fairness-conscious FL approaches offer marginal improvements in fairness in non-iid settings. Future work may include testing more approaches to reduce unfairness, improving scalability, and investigating fairness performance in unsupervised learning and foundational models.



