





Authors:
Tao Yang、Yangming Shi、Yunwen Huang、Feng Chen、Yin Zheng、Lei Zhang
Paper:
https://arxiv.org/abs/2408.10119
Introduction
Video generation, particularly text-to-video (T2V) generation, has garnered significant interest due to its wide range of applications, including video generation, editing, enhancement, and translation. However, generating high-quality (HQ) videos remains a challenging task due to the diverse and complex motions present in real-world scenarios. Most existing approaches attempt to address this challenge by collecting large-scale HQ videos, which are often inaccessible to the broader community.
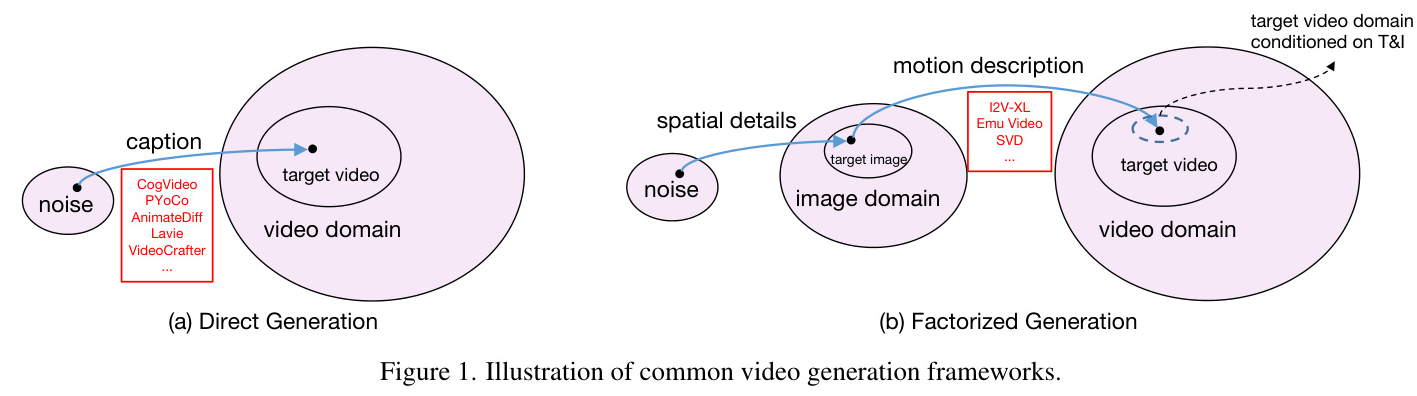
In this context, the paper “Factorized-Dreamer: Training A High-Quality Video Generator with Limited and Low-Quality Data” introduces a novel approach that leverages publicly available limited and low-quality (LQ) data to train a HQ video generator without the need for recaptioning or fine-tuning. The proposed method, Factorized-Dreamer, factorizes the T2V generation process into two steps: generating an image conditioned on a highly descriptive caption and synthesizing the video conditioned on the generated image and a concise caption of motion details.
Related Work
Text-to-Image Generation
Diffusion models have recently demonstrated powerful capabilities in generating HQ natural images, surpassing traditional generative models such as GANs, VAEs, and Flows. Early image generation models were conditioned on labels or focused on specific objects/sceneries. The seminal work of DALLE showed that T2I generation is possible, and subsequent models like Imagen and Stable Diffusion (SD) have further advanced the field by achieving photo-realistic T2I generation.
Text-to-Video Generation
T2V generation has gained increasing attention with the success of T2I synthesis. Most prior works leveraged T2I models for T2V generation, either by encoding motion dynamics in the latent space of a T2I model or by embedding temporal modules into a T2I model. However, these methods often produce LQ results or rely on proprietary datasets that are not publicly available.
Leveraging Knowledge from Images for Video Generation
To address the limitations of publicly available video-text datasets, different strategies have been proposed to leverage knowledge from image data for video generation. These include training a T2I model and then fine-tuning it on video datasets, training T2V models jointly on image-text and video-text pairs, and using CLIP image features as a condition. The proposed Factorized-Dreamer leverages image knowledge by factorizing the T2V generation into generating an image using a text prompt and synthesizing a final video based on the image and text conditions.
Research Methodology
Motivation
The target domain of a T2V model is significantly larger than that of a T2I model due to the extra temporal dimension. This necessitates a larger HQ training dataset, which is often not available. To address this, the proposed method shrinks the target domain conditioned on the text prompt by leveraging image knowledge for video generation. This factorized approach eliminates the need for recaptioning and alleviates issues related to LQ image features and watermarks.
Architecture
The architecture of Factorized-Dreamer consists of several critical components:
- Text-to-Image Adapter: Combines both image and text information for spatial modules using CLIP image features and a T2I adapter.
- Pixel-Aware Cross Attention (PACA): Perceives pixel-level details by using a plug-and-play module that takes conditioned image latent as input.
- Text Encoder for Motion Understanding: Employs the T5 text encoder for more precise motion understanding.
- PredictNet for Motion Supervision: Supervises the learning of video motions by predicting optical flows, improving motion coherence.


Noise Schedule
Diffusion models synthesize HQ data by progressively adding noise to a dataset and then learning to reverse this process. The noise schedule plays a key role in this process. The proposed method addresses issues related to the signal-to-noise ratio (SNR) by rescaling the noise schedule and introducing a shifting factor to make it more suitable for video generation tasks.
Training Strategy
The training strategy involves learning the Factorized-Dreamer model to predict the noise added to the noisy video latent conditioned on various inputs. The optimization objective includes a loss term for the PredictNet to improve motion coherence. The model is trained on publicly available datasets, including WebVid and PexelVideos, using a multi-stage training strategy.
Experimental Design
Experiment Setup
- Training and Testing Datasets: The model is trained on publicly available datasets, including WebVid and PexelVideos, and evaluated using the zero-shot T2V generation on the UCF101 dataset.
- Training Scheme: The training involves a multi-stage strategy, starting with low-resolution videos and progressing to high-resolution videos, with the final stage introducing PredictNet for motion supervision.
- Evaluation Metrics: The model is evaluated using EvalCrafter, Frechet Video Distance (FVD), Inception Score (IS), Frame consistency (FC), and Prompt consistency (PC) indices. User studies are also conducted for comprehensive evaluation.

Results and Analysis
Text-to-Video Generation
The proposed Factorized-Dreamer is compared with various T2V generation models, including direct T2V generation models and factorized video generation models. The results demonstrate that Factorized-Dreamer achieves competitive FVD and IS scores and ranks highly on the EvalCrafter benchmark, indicating its effectiveness in generating HQ videos using limited and LQ datasets.

Image-to-Video Generation
Factorized-Dreamer is also evaluated for image-to-video (I2V) generation tasks, showing superior performance compared to open-sourced methods and competitive performance against commercial approaches. The results highlight the model’s ability to generate text-aligned and physically realistic videos.

User Studies
User studies are conducted to evaluate the model’s performance in terms of visual quality, motion quality, prompt following, and temporal consistency. The results indicate that Factorized-Dreamer outperforms competing methods in several aspects, demonstrating its potential for practical applications.

Ablation Studies
A series of ablation experiments are conducted to study the impact of various design decisions, including the noise schedule, factorized generation, T5 text encoder, and PredictNet. The results confirm the importance of these components in achieving high-quality video generation.

Overall Conclusion
The paper presents Factorized-Dreamer, a novel approach for training a HQ video generator using limited and LQ datasets. The factorized spatiotemporal architecture, combined with several critical design decisions, enables the model to generate high-quality videos without the need for recaptioning or fine-tuning. Extensive experiments demonstrate the effectiveness and flexibility of Factorized-Dreamer across T2V and I2V tasks. While the model shows promising results, it still faces challenges related to inconsistent and incoherent motions and struggles to generate long videos. Future work will focus on addressing these limitations and further improving the model’s performance.



