





Authors:
Xiao Wang、Yao Rong、Fuling Wang、Jianing Li、Lin Zhu、Bo Jiang、Yaowei Wang
Paper:
https://arxiv.org/abs/2408.10488
Introduction
Sign Language Translation (SLT) is a crucial task in the realm of AI-assisted disability support. Traditional SLT methods rely on visible light videos, which are susceptible to issues such as lighting conditions, rapid hand movements, and privacy concerns. This paper introduces a novel approach using high-definition event streams for SLT, which effectively mitigates these challenges. Event streams offer a high dynamic range and dense temporal signals, making them resilient to low illumination and motion blur. Additionally, their spatial sparsity helps protect the privacy of the individuals being recorded.
The authors present a new high-resolution event stream sign language dataset, termed Event-CSL, which fills a significant data gap in this research area. The dataset includes 14,827 videos, 14,821 glosses, and 2,544 Chinese words in the text vocabulary, collected across various indoor and outdoor scenes. The paper also proposes a novel baseline method leveraging the Mamba model’s ability to integrate temporal information from CNN features, resulting in improved SLT outcomes.
Related Work
Sign Language Translation
Sign Language Translation has garnered significant attention in computer vision, aiming to convert sign language videos into spoken text to facilitate communication for the deaf community. Various approaches have been proposed, including:
- Camgöz et al. introduced the SLT problem and proposed a Transformer-based architecture for end-to-end learning of sign language recognition and translation.
- GloFE extracts common concepts from text and uses global embeddings for cross-attention lookups.
- Zhou et al. proposed a two-stage approach combining contrastive language image pre-training with masking self-supervised learning.
- SignNet II and GASLT are Transformer-based models enhancing text-to-sign translation performance.
State Space Model
State Space Models (SSMs) describe dynamic systems using differential or difference equations. Recent advancements include:
- Rangapuram et al. utilized recurrent neural networks to parameterize linear state-space models.
- Gu et al. proposed the Structured State Space (S4) sequence model and the Linear State Space Layer (LSSL).
- Mamba and VMamba are sequence modeling methods addressing computational efficiency and global receptive fields.
Inspired by these works, the authors propose augmenting local CNN features using SSM for event-based SLT.
Research Methodology
Overview
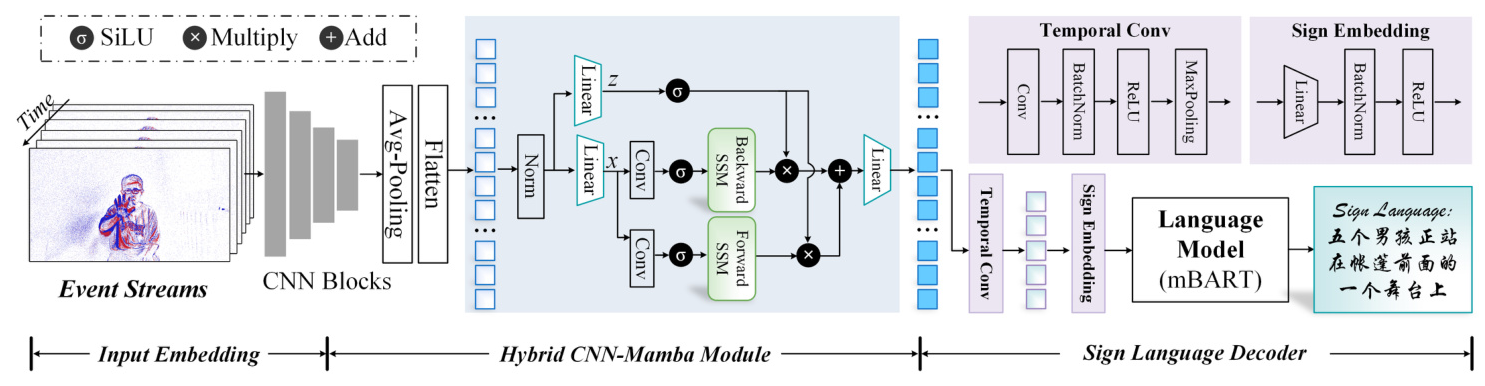
The proposed event-based SLT framework involves stacking event streams into frames, feeding them into a residual network for feature extraction, and using Mamba blocks to capture long-range temporal features. The enhanced features are then processed through a temporal convolutional module and a sign embedding module before being decoded into Chinese language sentences using a Transformer-based language model.
Input Representation
Event streams are transformed into event images, resized to a fixed resolution, and processed in mini-batches during training.
Network Architecture
- Hybrid CNN-Mamba Vision Backbone Network: Combines ResNet-18 for local feature extraction with Mamba layers for long-range temporal context modeling.
- Sign Language Decoder: Uses a temporal convolutional module and a sign embedding module to generate sign language sentences, initialized with pre-trained mBART parameters.
Loss Function
The cross-entropy loss function is used to calculate the distance between annotated sign language and generated sentences.
Experimental Design
Event-CSL Dataset
The Event-CSL dataset is collected following protocols ensuring diversity in views, camera motions, scenes, light intensity, action continuity, and sign language content. It includes 14,827 videos, 14,821 glosses, and 2,544 Chinese words, divided into training, validation, and testing subsets.
Statistical Analysis
The dataset surpasses existing event-based sign language datasets in terms of video count, resolution, gloss, and text vocabulary. A word cloud visualization of the textual annotations is provided.
Benchmark Baselines
The performance of several SLT algorithms is reported as baselines for future comparisons, including gloss-based and gloss-free methods.
Results and Analysis
Dataset and Evaluation Metric
Experiments are conducted on four event-based SLT datasets: Event-CSL, EvSign, PHOENIX-2014T-Event, and CSL-Daily-Event. BLEU and ROUGE-L metrics are used to assess performance.
Implementation Details
The model uses the SGD optimizer with a cosine annealing scheduler, implemented in PyTorch and tested on A800 GPUs.
Comparison on Public SLT Datasets
The proposed method outperforms state-of-the-art methods on the Event-CSL, EvSign, PHOENIX-2014T-Event, and CSL-Daily-Event datasets, demonstrating its effectiveness.
Ablation Study
Component analysis on the Event-CSL dataset shows the impact of each module. The hybrid CNN-Mamba backbone significantly improves performance by modeling long-range temporal relations.
Efficiency Analysis
The proposed method is efficient in terms of parameters, GPU memory, and speed compared to Transformer-based architectures.
Visualization
Qualitative results show the generated sentences compared to reference sentences, demonstrating the model’s reliability in capturing the meaning of sign language videos.
Limitation Analysis
Future improvements include designing architectures to fully exploit high-definition event-based SLT and using larger language models for better performance.
Overall Conclusion
This study introduces a novel approach to SLT using high-definition event streams, addressing limitations of traditional methods. The Event-CSL dataset and the proposed baseline method demonstrate significant advancements in SLT, paving the way for future research and development in this field.





















Code:
https://github.com/event-ahu/openesl


