





Authors:
Steve Yuwono、Dorothea Schwung、Andreas Schwung
Paper:
https://arxiv.org/abs/2408.06397
Introduction
In modern manufacturing systems, the integration of Artificial Intelligence (AI), Internet of Things (IoT), and Cyber-Physical Systems (CPS) technologies has revolutionized operational efficiency by enabling functions like fault tolerance, self-optimization, and anomaly detection. These advancements have led to the development of modular production units controlled by decentralized systems, necessitating distributed optimization methodologies to dynamically adjust to fluctuating demands. This paper introduces a novel game structure called Distributed Stackelberg Strategies in State-Based Potential Games (DS2-SbPG) to address these challenges.
Literature Review
Multi-Objective Optimizations
Multi-objective optimization involves optimizing multiple conflicting objectives simultaneously. This field includes various mathematical models and algorithms aimed at finding trade-off solutions along the Pareto frontier. In self-learning domains, multi-objective optimization is applied in defining objective functions guiding the learning process, such as reward functions in deep multi-agent reinforcement learning (MARL) and utility functions in dynamic game theory (GT).
Decentralized Learning Manufacturing Systems
Decentralized learning in manufacturing systems involves distributed knowledge acquisition and performance enhancement across multiple entities. This approach enhances adaptability, resilience, and efficiency in complex manufacturing environments by enabling agents to learn and decide based on local information autonomously. Dynamic GT has been shown to be more proficient and applicable in self-learning distributed multi-agent systems (MAS) compared to MARL and model predictive controllers.
Dynamic GT with Engineering Applications
GT is a mathematical framework used to model and analyze interactions between rational decision-makers. Dynamic GT extends traditional GT to analyze situations where players’ decisions evolve over time, capturing the sequential nature of actions and the feedback loop between decisions and outcomes. This approach is valuable in distributed self-learning MAS, where agents interact and make adaptive decisions based on local information.
Problem Descriptions
The primary goal is to achieve self-optimization of modular manufacturing systems in a fully distributed manner, eliminating the need for a centralized control instance. Each sub-system has multiple distinct objectives, such as satisfying production demand, minimizing power consumption, and avoiding bottlenecks. The challenge lies in managing conflicting and diverse utility functions between players to optimize global objectives and managing multi-objectives within each local objective.



Preliminary Game Structures
State-based Potential Games
Potential games model strategic interactions among rational agents, where players’ payoffs depend on their actions and the environment’s state. State-based Potential Games (SbPGs) extend potential games by incorporating state information into strategic interactions. SbPGs ensure convergence to Nash equilibrium points under best-response dynamics.
Stackelberg Games
Stackelberg games explore hierarchical interactions among rational players, characterized by a leader-follower dynamic. The leader can pre-commit to a strategy, and the follower subsequently responds to the leader’s actions. This hierarchical form allows for more efficient outcomes compared to simultaneous-move games.


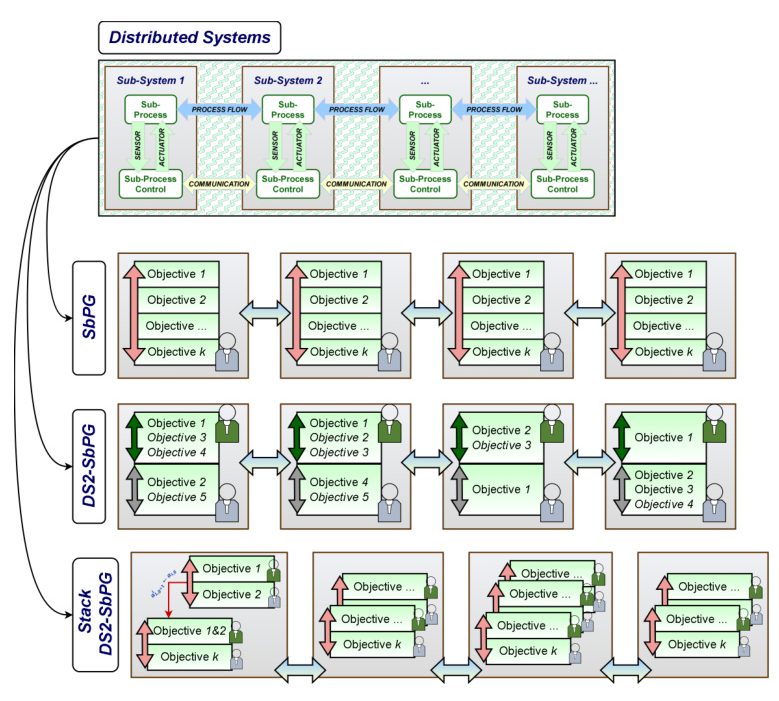
Distributed Stackelberg Strategies in State-Based Potential Games
DS2-SbPG for Single-Leader-Follower Objective
DS2-SbPG integrates the Stackelberg strategy as an integral component for each player in an SbPG. Each player consists of a leader and a follower, each with individual actions and utility functions. The leader holds the strategic advantage of initiating decisions before followers react.
Stack DS2-SbPG for Multi-Leader-Follower Objective
Stack DS2-SbPG extends the approach to accommodate strategies for multi-leader-follower objective scenarios. Each player has a hierarchical order of roles based on the priority of the objectives. This approach allows for a comprehensive optimization approach by accommodating numerous objectives independently.


Learning Algorithm
The learning algorithm for DS2-SbPG involves gradient-based learning for optimizing the policies of leaders and followers. The leader anticipates the follower’s best response, while the follower plays the best response to the leader’s actions. The learning process involves updating performance maps and employing Stackelberg game-based gradient update laws.



Proof of Convergence
The paper provides proof of convergence for DS2-SbPG and Stack DS2-SbPG, ensuring that the proposed approach maintains the dynamic potential game structure, which is known for its robustness and convergence.



Experimental Results and Discussion
Testing Environment: The Bulk Good Laboratory Plant
The Bulk Good Laboratory Plant (BGLP) is a decentralized manufacturing system with modular functionalities for bulk goods transportation. The system manages the transport of bulk goods through a network of various actuators and reservoirs, enabling transfers between four operational modules: loading, storage, weighing, and filling.

Training Setup on the BGLP
Each player in the BGLP corresponds to an individual actuator with multiple objectives, such as maintaining fill levels, minimizing power consumption, and meeting production demand. The training setup involves computing coalition strategies between leader and follower objectives and evaluating utility functions for each objective.
Experimental Results
The experimental results demonstrate the effectiveness of DS2-SbPG and Stack DS2-SbPG in optimizing multi-objective problems in distributed manufacturing systems. Both approaches show significant improvements in power consumption and overall performance compared to the standard SbPG.





[illustration: 19]
Conclusions
The paper introduces DS2-SbPG, a novel game structure for self-learning decentralized manufacturing systems, suitable for solving multi-objective optimization problems. DS2-SbPG integrates Stackelberg strategies within each player of SbPGs while preserving a distributed approach. The experimental results highlight the potential of DS2-SbPG in real-world applications, demonstrating significant improvements in power consumption and overall performance. Future work will focus on enhancing DS2-SbPG to handle constrained optimization problems and exploring its potential in diverse self-learning domains.


