





Authors:
Yujia Wu、Yiming Shi、Jiwei Wei、Chengwei Sun、Yuyang Zhou、Yang Yang、Heng Tao Shen
Paper:
https://arxiv.org/abs/2408.06740
Introduction
Personalized text-to-image generation has become a significant area of research due to its ability to create high-fidelity portraits of specific identities based on user-defined prompts. Traditional methods often involve test-time fine-tuning or adding an additional pre-trained branch, which can be inefficient and struggle to maintain identity fidelity while preserving the model’s original generative capabilities. This paper introduces DiffLoRA, a novel approach that leverages diffusion models to predict personalized low-rank adaptation (LoRA) weights from reference images, integrating these weights into the text-to-image model for efficient and accurate personalization during inference without further training.
Related Work
Personalization in Diffusion Models
Diffusion models have seen extensive use in personalized image generation, utilizing pre-trained text encoders like CLIP to encode text prompts into latent space. Methods such as DreamBooth and Textual Inversion require extensive fine-tuning, while more recent techniques offer tuning-free personalization by adding branches to inject identity information during inference. DiffLoRA stands out by predicting and loading LoRA weights from a reference image into the SDXL model, eliminating the need for retraining.
Parameter Generation
Hypernetworks dynamically generate model weights, offering flexibility and efficiency. Diffusion models as hypernetworks have shown superior outcomes compared to other frameworks. DiffLoRA leverages these advancements to predict LoRA weights, integrating them into existing Parameter-Efficient Fine-Tuning (PEFT) methods for flexible applications across various tasks.
Preliminaries and Motivation
Latent Diffusion Models
Latent Diffusion Models (LDMs) operate on latent representations instead of original samples, using a VAE to project images into latent space. The diffusion process minimizes the discrepancy between predicted and actual noise at each timestep, guided by condition embeddings to produce diverse and contextually relevant latent representations.
Why Predict LoRA Weights?
LoRA weights are easier to predict compared to MLP weights due to their low-rank structures, which reduce the parameter count and computational complexity. This efficiency is demonstrated through a toy experiment, showing that low-rank features are easier to compress and reconstruct, supporting the hypothesis that LoRA weights are more efficient to predict.
Method
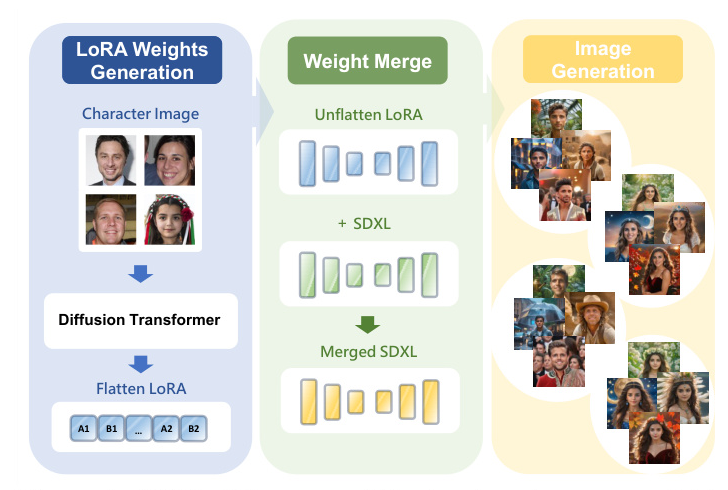
LoRA Weights Generation
DiffLoRA generates accurate LoRA weights using a LoRA weight autoencoder (LAE) combined with a diffusion model. The LAE compresses LoRA weights into a latent space, and the diffusion transformer model predicts encoded LoRA latent representations. The Mixed Image Features (MIF) mechanism integrates face and image features to guide the denoising process. The dataset construction pipeline generates LoRA weights for multiple identities, facilitating DiffLoRA training.
LoRA Weight Autoencoder
The LAE compresses and reconstructs LoRA weights, targeting structural and informational correlations. The weight-preserved loss function enhances the reconstruction of larger weights, improving the quality of generated images. The LAE can compress the original LoRA weights by nearly 300 times.


Mixed Image Features
MIF leverages both facial details and general image information to improve identity feature extraction. A gate network combines face and image embeddings, dynamically integrating detailed facial features and general image features for enhanced identity extraction.

Denoising Process
The diffusion model, based on the DiT architecture, processes LoRA latent representations with noise added and predicts the original latent representations. Adaptive Layer Normalization (AdaLN) mechanisms incorporate mixed features to guide the diffusion process.

LoRA Weight Pipeline
The pipeline generates a high-quality LoRA weight dataset by collecting facial images, generating diverse images using PhotoMaker, filtering and preprocessing images, and training the SDXL model with DreamBooth.

Experiments
Training Details
The LAE is optimized using AdamW on 4 NVIDIA 3090 GPUs, and the diffusion model is trained with a 16-layer, 1454-dimension DiT model. Mixed image features are created by randomly sampling images of the same identity during training.
Evaluation Metrics
Metrics include DINO and CLIP-I for identity fidelity, CLIP-T and Image Reward for text-image consistency, Face Sim for facial similarity, FID for image quality, and personalization speed for inference cost.
Evaluation Dataset
The evaluation dataset consists of 25 identities with 30 prompts, ensuring a comprehensive evaluation of the model’s generalization ability.
Comparisons
DiffLoRA outperforms baseline methods like LoRA-DreamBooth, Textual Inversion, InstantID, and PhotoMaker in terms of image diversity, realism, identity fidelity, and inference cost.

Ablation Studies
Ablation studies reveal the impact of different components on the quality of generated images. The Mixed Image Features (MIF) and Weight-Preserved Loss significantly enhance identity preservation and image quality.

Conclusion
DiffLoRA introduces a novel method for human-centric personalized image generation, leveraging a latent diffusion-based hypernetwork framework to predict LoRA weights for specific identity adaptation in the SDXL model. This tuning-free approach achieves high-fidelity portraits without extra inference cost, outperforming existing methods in text-image consistency, identity fidelity, generation quality, and inference efficiency.



