





Authors:
Valdemar Švábenský、Kristián Tkáčik、Aubrey Birdwell、Richard Weiss、Ryan S. Baker、Pavel Čeleda、Jan Vykopal、Jens Mache、Ankur Chattopadhyay
Paper:
https://arxiv.org/abs/2408.08531
Introduction
As cyber threats become increasingly complex, the demand for cybersecurity experts has surged. Effective teaching methods, such as hands-on exercises, are essential for training these experts. However, the complexity of cybersecurity exercises often leads to student frustration and impedes learning. This paper aims to develop automated tools to predict when a student is struggling, enabling instructors to provide timely assistance.
Goals and Scope of This Paper
The primary goal is to extract information from student actions in cybersecurity exercises to predict student success or potential risk of poor performance. The study focuses on university-level cybersecurity education but can be adapted to other contexts. The research poses two main questions:
1. How well do different machine learning classifiers predict (un)successful students in cybersecurity exercises?
2. Are the best classifiers in one context also the best in another context when trained using the same methods with a different student population?
Contributions to Research and Practice
The paper makes several contributions:
1. Collection of an original dataset from 313 students across two learning environments.
2. Automatic extraction of two feature sets from the data.
3. Training and evaluation of eight types of binary classification models for predicting student success.
4. Publication of data and code to support reproducibility and replicability.
Related Work in Predictive Models
Hands-on Cybersecurity Education
Previous studies have used student data to achieve various goals, such as clustering students based on performance. However, predicting student performance in cybersecurity exercises is less explored. For instance, Vinlove et al. used a small dataset and a single model to detect at-risk students, achieving 80% accuracy. Deng et al. used a naive Bayes classifier to predict course performance with 90.9% accuracy but evaluated only one classifier.
Other Areas of Computing Education
Research on student success prediction is more extensive in other computing domains. Hellas et al. reviewed 357 articles and noted that the best studies utilized data from multiple contexts and compared multiple methods. However, many studies had limitations such as single student populations and lack of data sharing.
Literature Gaps and Novelty of This Paper
The study addresses several gaps:
1. Focus on cybersecurity, a less-explored area compared to programming education.
2. Application of multi-contextual data from different institutions and semesters.
3. Prediction in smaller time frames, focusing on individual exercises rather than entire courses.
4. Comparison of various methods, evaluating eight models with a rich feature set.
5. Sharing of research artifacts, including data and code.
Research Methods
Format and Content of the Cybersecurity Exercises
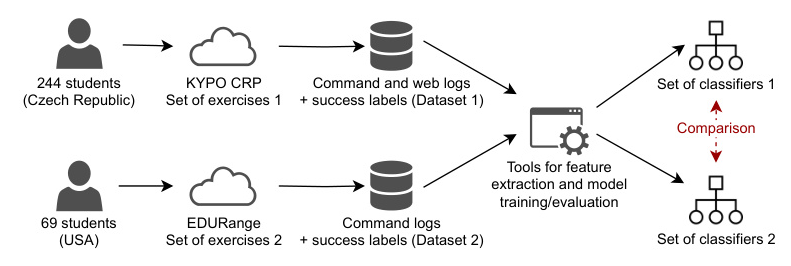
The study involves two learning environments: KYPO CRP and EDURange. KYPO CRP exercises involve breaching vulnerable emulated hosts using a Kali Linux VM, with tasks presented via a web interface. EDURange includes attack and defense exercises, with tasks completed using Linux command-line tools in a VM.
Data Collection in the Two Learning Platforms
KYPO CRP collects command logs and event logs, while EDURange uses a single logging format for terminal data. The study collected data from 244 students in KYPO CRP and 69 students in EDURange.
Data Cleaning and Filtering
The dataset underwent thorough manual and automated inspection to remove unreasonable values. The final dataset includes 21,659 command logs and 8,690 event logs from KYPO CRP, and 4,762 command logs from EDURange.
Definition of Class Labels and Data Labeling
Exercise success is defined as at least 50% completion. In KYPO CRP, this means not displaying solutions for more than 50% of tasks and submitting correct answers. In EDURange, it means finishing at least half of the tasks. The dataset is imbalanced towards successful students, reflecting the settings in which the platforms were employed.
Feature Extraction and Selection
For KYPO CRP, 25 features were engineered, while EDURange had 15 features. Features were derived from exercise problem-solving data, excluding personal information. Automated feature selection was applied using L1-regularized linear models.
Model Training and Evaluation
Eight classifiers were systematically compared: logistic regression, naive Bayes, support vector machines (linear and RBF kernel), K-nearest neighbors, decision tree, Random Forest, and XGBoost. Nested student-level cross-validation was used for model training and evaluation.
Results and Discussion
Classifier Performance in KYPO CRP
The decision tree achieved the highest balanced accuracy (88.4%) and sensitivity (86.9%). Random Forest had the best specificity (96.1%) and AUC (93.1%). The difference in balanced accuracy across models was small, suggesting that all classifiers were suitable for the context.
Comparison With EDURange
Results in EDURange were consistent with KYPO CRP. The decision tree again had the highest balanced accuracy (82%) and sensitivity (90%). Random Forest performed well with a balanced accuracy of 78.6% and AUC of 85.3%. The slightly worse performance in EDURange indicates that additional web interface data improves predictive power.
Limitations and Threats to Validity
- Internal Validity: The threshold for success is arbitrary, affecting results. However, this is a limitation of any binary classification.
- External Validity: Exercise sessions varied in aspects such as student demographics and modality. Despite differences, these variations may enhance generalizability.
Implications for Teaching Practice
The classifiers can be deployed to detect unsuccessful students, enabling instructors to provide timely assistance. Even with some misclassifications, the rate of false positives/negatives is manageable in hands-on cybersecurity courses.
Conclusions
Identifying at-risk students is crucial for providing targeted interventions. This study demonstrated that predicting student success based on exercise data is a promising approach that generalizes across contexts.
Open Research Challenges
Future work can explore predicting specific tasks where students will struggle, ranking students based on the likelihood of needing help, and detecting at-risk students as early as possible.
Publicly Available Supplementary Materials
The datasets and scripts for processing exercise logs, extracting features, and training classifiers are publicly available.
Illustrations

Figure 1: Overview of the study design.


Figure 2: Distribution of positive and negative training labels.

Figure 3: Features used for building models from KYPO CRP data.

Figure 4: Features used for building models from EDURange data.

Figure 5: Classifier performance using the 244 data points for KYPO CRP.

Figure 6: Classifier performance using the 69 data points for EDURange.


