





Authors:
Yuanhao Zeng、Fei Ren、Xinpeng Zhou、Yihang Wang、Yingxia Shao
Paper:
https://arxiv.org/abs/2408.10841
Introduction
Large Language Models (LLMs) have shown exceptional capabilities across various tasks, but their application in specific domains often necessitates additional fine-tuning. Instruction tuning has become a popular method to address this need, aiming to enable LLMs to follow task-specific instructions. However, research indicates that instruction tuning primarily fits models to specific task formats rather than imparting new knowledge or capabilities. This limitation is particularly evident with smaller datasets, contradicting the ideal scenario where LLMs learn adaptable downstream task capabilities.
The core issue arises from the discrepancy between instruction tuning data distribution and the diverse real-world instruction distribution, leading to the learning of biased features during instruction tuning. These biased features deviate from ideal task-specific features. To address this challenge, the authors introduce DELIA (Diversity-Enhanced Learning for Instruction Adaptation), leveraging the buffering effect of extensive diverse data in LLM training to transform biased features into approximations of ideal features without explicit training objectives towards ideal features.
Related Work
Limitations of Instruction Tuning
Instruction tuning has been widely adopted to enhance model performance on specific tasks, but numerous studies have revealed inherent flaws in this approach. For instance, Sclar et al. (2023) demonstrated that such models could become excessively sensitive to prompt variations, compromising their robustness. Sun and Dredze (2024) observed that fine-tuning often results in models fitting specific task formats, hindering their ability to adapt to novel presentations of similar tasks. Wang et al. (2022b) argued that instruction-tuned models become overly specialized in specific task formats rather than learning underlying semantics.
Approaches to Improving Instruction Following
Researchers have proposed various solutions to address the challenges of instruction tuning. At the framework level, Li et al. (2023) and Zhao et al. (2024) proposed frameworks that iteratively self-improve training data quality. Vernikos et al. (2020) proposed modifying the training objective with an adversarial classifier to mitigate domain overfitting. Architectural modifications have also been explored, such as multiple PEFT modules (Wang et al. 2022a) and introducing noise during embedding to improve generalization capabilities (Jain et al. 2023).
Synthetic Data for Model Improvement
Synthetic data generation has emerged as a promising solution to instruction tuning challenges, offering the introduction of human-interpretable prior knowledge and scalable, data-driven performance improvement. Liu et al. (2023) explored manipulating instruction positioning in training data. Dong et al. (2024) focused on balancing specialized and general knowledge retention. Mecklenburg et al. (2024) involved extracting and synthesizing atomic facts for more robust knowledge representation.
Research Methodology
Problem Definition
The training objective of LLMs is to minimize the cross-entropy loss function. In the context of instruction tuning, for a given instruction, the goal is to minimize the following loss:
[
\mathcal{L(\theta)=-\mathbb{E}{x\sim p(x)}[\sum{t=i n s}^{r e s p o n s e}\log\hat{q}{\theta}(x{t}|x_{<t})]}
]
However, there is a discrepancy between the ideal distribution of downstream tasks (p_d) and the general alignment distribution (p_g) of open-source LLMs. The goal is to enable LLMs to acquire downstream task capabilities through instruction tuning, i.e., to find parameters (\theta_d) that minimize:
[
\mathcal{L(\theta_{d})}=-\mathbb{E_{x}..p_{d}(x)}[\sum_{t=i n s}^{r e s p o n s e}\log\hat{q}{\theta{d}}(x_{t}|x_{<t})]
]
Ideal Features vs. Biased Features
LLMs are expected to learn ideal features for downstream tasks through (p_d), enabling task completion under any instructions with similar semantics. However, the ideal distribution (p_d) for downstream tasks is unknown and incalculable. The actual training distribution (p’_d) deviates from the ideal downstream task distribution (p_d), leading to biased features.
Distribution Difference Hypothesis
Based on empirical observations, the hypothesis is that (p_d) is closer to (p_g) than (p’_d):
[
D_{KL}(p’d||p_g) > D{KL}(p_d||p_g)
]
This divergence arises from the goal of enabling LLMs to perform downstream tasks under any instructions with similar semantics after instruction tuning. However, the training data inevitably contains biases, leading to biased features in (p’_d).
DELIA Method: Bridging the Gap Between Biased and Ideal Features
To address the discrepancy in features, the DELIA method introduces extensive diverse data to mitigate the gap between (p’_d) and (p_d).
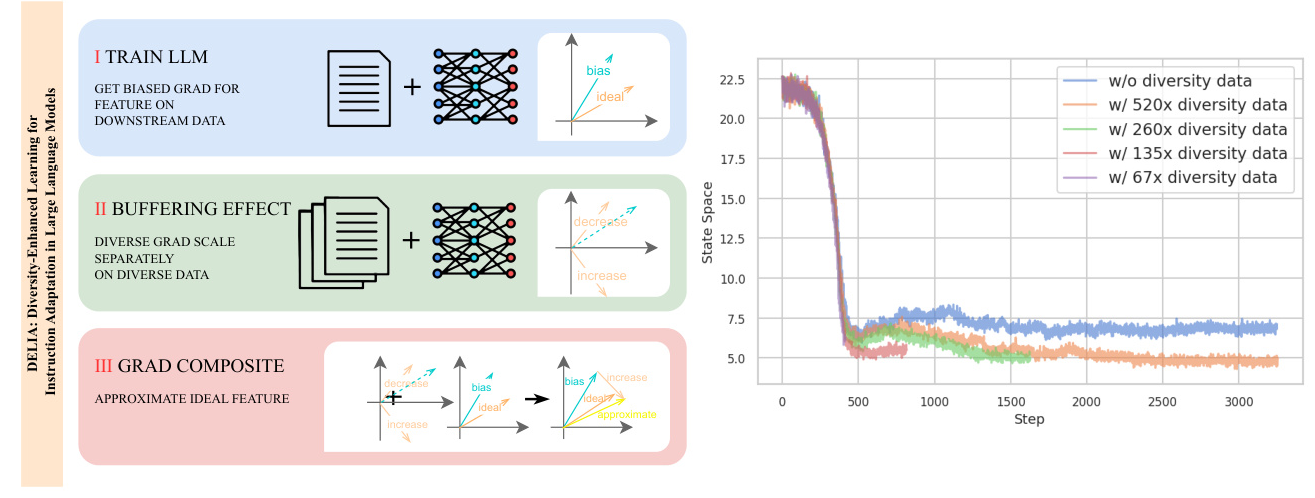
Buffering Effect
Introducing extensive diverse training data sampled from similar LLMs can produce the following effects:
1. When trained independently, these data generate gradients that largely cancel each other out, resulting in minimal changes to the LLM’s parameters.
2. When trained together with downstream task data, the training process reduces the gradients produced by data similar to the downstream task and increases the gradients produced by data significantly different from the downstream task.
This gradient differential allows the model to learn biased features while also learning content biased towards general features, termed the buffering effect.
Mathematical Derivation
The mathematical derivation illustrates the working principle of the DELIA method. By introducing extensive diverse data, the gradients learned towards (p’_d) are transformed into approximations of gradients learned towards (p_d). This mechanism allows the model to maintain adaptability to downstream tasks while learning more general and robust feature representations.
Algorithm
The DELIA method involves the following steps:
- Initialize fine-tuned model with pre-trained LLM.
- Add special tokens and initialize embedding weight.
- Sample diverse question-answer pairs from LLM.
- Anisotropically diversify instructions of downstream task data.
- Train LLM on each data point and update model parameters.
- Sample examples from diverse data and train LLM on them.
- Return fine-tuned LLM.
Experimental Design
Experiment Setup
The experiments evaluate DELIA’s effectiveness through intermediate representation analysis, formatted text generation, and English-Icelandic translation tasks.
Models and Datasets
- Experiment 1: Evaluation of intermediate representations using the Llama 2-7B-Chat model on the Leverage Learning formatted text dataset.
- Experiment 2: Formatted text generation task using the Llama 2-7B-Chat model on the Leverage Learning formatted text dataset.
- Experiment 3: English-Icelandic translation task using the gemma-7B-it model on the WMT-21 dataset.
Baselines
The baselines include Random Baseline, Common Instruction Tuning, Mean Embedding, Fact-based, DMT, Controlled Text Generation, and DiPMT.
Intermediate Representation Analysis
The task involves generating JSON-formatted text with the “thought” key from instructions without explicit token semantics. The evaluation metric is the L2 norm between and key words in its prior description.
Practical Experiment Tasks and Datasets
The performance of DELIA is evaluated on formatted text generation and English-Icelandic translation tasks. The evaluation metrics are generation accuracy for formatted text generation and bleurt score for translation.
Results and Analysis
Intermediate Representation Analysis
DELIA demonstrates significant advantages in learning semantic representations, with performance improving as sample size increases. DELIA effectively utilizes increasing training samples even at small data scales, achieving excellent semantic understanding.


Practical Experiment Results
Formatted Text Generation
DELIA significantly outperforms various baselines under the given data scale.

English-Icelandic Translation
DELIA performs excellently, highlighting its potential in low-resource language translation tasks.

Ablation Experiment
The ablation experiment results show that removing either the diversified downstream tasks or the extensive diversified data leads to significant deterioration in all metrics. This indicates that DELIA’s performance improvement is due to the synergistic effect of both types of diversification.

Overall Conclusion
This study introduces DELIA, a method that improves feature learning in instruction tuning by leveraging the buffering effect of diverse data in large language model training. DELIA significantly outperforms common instruction tuning methods and other baselines across various tasks. The approach uniquely aligns the internal representations of new special tokens with their prior semantics, surpassing known knowledge injection methods. While DELIA opens new possibilities, limitations such as the gap between ideal and actual diverse data, the existence of an optimal approximation point, and experimental scale constraints provide directions for future research.


