





Authors:
Paper:
https://arxiv.org/abs/2408.06804
Introduction
Speaker identification (SID) is a crucial task in various applications such as forensics, security, and personalized services. It involves determining a speaker’s identity from an audio sample chosen from a pool of known speakers. This research delves into the essential components of SID, focusing on feature extraction and classification. The study emphasizes the use of Mel Spectrogram and Mel Frequency Cepstral Coefficients (MFCC) for feature extraction and evaluates six different model architectures to determine their performance.
Feature Extraction
Feature extraction is a critical step in speech analysis, transforming raw audio data into useful features. Two widely used techniques in this field are Mel Spectrogram and MFCC. The Mel Spectrogram visualizes the frequency content of an audio source across time, emphasizing human auditory perception, while MFCCs capture the spectral features of the audio signal in a compact representation.
Mel Spectrogram Feature Extraction
The Mel Spectrogram translates frequencies into the Mel scale, providing a visual representation of the frequency content over time.
MFCC Feature Extraction
MFCCs extract compact representations by capturing the spectral features of the audio signal.
Model Architecture
This study investigates six slightly distinct model architectures. The first model architecture incorporates elements from previous studies, including convolution layers for early feature extraction and a lightweight LSTM layer. Batch normalization and dropout layers are added to regularize the output and avoid overfitting. The final classification is performed using a softmax function.
Model Variations
- Model 2: Increased convolutional depth in the feature extractors.
- Model 3: Increased number of LSTM units and added an extra layer.
- Model 4: Added an extra dense layer following the CNN-LSTM configuration.
- Model 5: Reduced model complexity by recommending fewer convolution filters.
- Model 6: Used batch normalization across all CNN blocks to reduce overfitting.
Evaluation
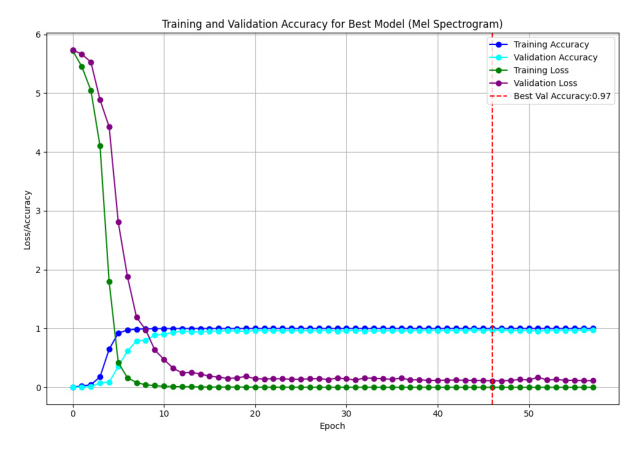
The models were trained using the TensorFlow Keras framework with the Adam optimizer and an early stopping callback to prevent overfitting. The results showed that models 1 and 5 outperformed others in terms of test accuracy, precision, recall, and F-score. Models using the Mel Spectrogram feature extractor generally outperformed those using the MFCC feature extractor.
Hyperparameter Tuning
A thorough hyperparameter tuning procedure was carried out for the best-performing model (Model 1). The optimal parameters found were a learning rate of 0.001, a dropout rate of 0.4, and the tanh activation function for the second layer, with relu for the remaining layers. These adjustments significantly improved the model’s performance.
Confusion Matrix
The confusion matrix for the top 20 projected speakers showed distinct diagonal components, indicating the model’s capacity to accurately predict speakers.
Analysis
A linguistic analysis was performed to assess the model’s gender and accent accuracy, ensuring neutrality and lack of bias.
Gender Accuracy
The model showed a slight variance in gender accuracy, performing slightly better in predicting female speakers. This indicates that the dataset is balanced and the model is unbiased towards any gender.
Accent Accuracy
The accent accuracy scores were similar across accents, with Standard Southern English being the easiest to predict and Newcastle the hardest. This highlights the need for further analysis and model development to address accent-related challenges in SID.
Conclusion
This study investigates the efficacy of Mel Spectrogram and MFCC as feature extraction approaches for SID, proposing robust model architectures designed for this purpose. The best model achieved high accuracy, precision, recall, and F-score, demonstrating the usefulness of these techniques. Gender accuracy analysis revealed minimal variation, confirming dataset balance and lack of gender bias. However, accent accuracy showed more noticeable discrepancies, indicating areas for future research and model improvement.
References
- S. Sremath Tirumala and S. R. Shahamiri, “A review on deep learning approaches in speaker identification,” in Proc. 8th Int. Conf. on Signal Processing Systems, 2016.
- A. Antony and R. Gopikakumari, “Speaker identification based on combination of MFCC and UMRT based features,” Procedia Computer Science, 2018.
- Y. Lukic et al., “Speaker identification and clustering using convolutional neural networks,” IEEE 26th International Workshop on Machine Learning for Signal Processing, 2016.
- Z. Zhao et al., “A lighten CNN-LSTM model for speaker verification on embedded devices,” Future Generation Computer Systems, 2019.
- D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” 2017.


