





Authors:
Wei Sun、Xiaosong Zhang、Fang Wan、Yanzhao Zhou、Yuan Li、Qixiang Ye、Jianbin Jiao
Paper:
https://arxiv.org/abs/2408.08723
Introduction
Novel View Synthesis (NVS) is a critical task in computer vision, aiming to generate new views of a scene from a set of input images. Traditional methods like Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS) require accurate camera poses, typically obtained through Structure-from-Motion (SfM) techniques. However, SfM is time-consuming and prone to errors, especially in textureless or repetitive regions. This paper introduces a novel approach, Correspondence-Guided SfM-Free 3D Gaussian Splatting (CG-3DGS), which eliminates the need for SfM by integrating pose estimation directly within the NVS framework.
Related Work
Novel View Synthesis
Various 3D scene representations have been explored for NVS, including planes, meshes, point clouds, and multi-plane images. NeRFs have gained prominence for their photorealistic rendering capabilities, while point-cloud-based representations like 3DGS offer real-time rendering efficiency. However, these methods typically depend on pre-computed camera parameters derived from SfM techniques.
SfM-Free Modeling for Novel View Synthesis
Recent efforts in SfM-free NVS include methods like iNeRF, NeRFmm, and BARF, which integrate pose estimation within the NVS framework. These methods often rely on per-pixel image loss functions, leading to excessive gradients and unstable optimization when initial pose estimates are inaccurate. The proposed CG-3DGS addresses these issues by leveraging 2D correspondences for better pixel alignment and robust optimization.
Method
Revisiting 3D Gaussian Splatting
3D Gaussian Splatting (3DGS) models scenes using 3D Gaussians, optimized based on input training views and associated camera poses. Each Gaussian is described by parameters such as position, scale, rotation, base color, view-dependent spherical harmonics, and opacity. The rendering process involves projecting these Gaussians onto the 2D image plane and blending their attributes to generate the final image.
Correspondence-Guided Pose Optimization
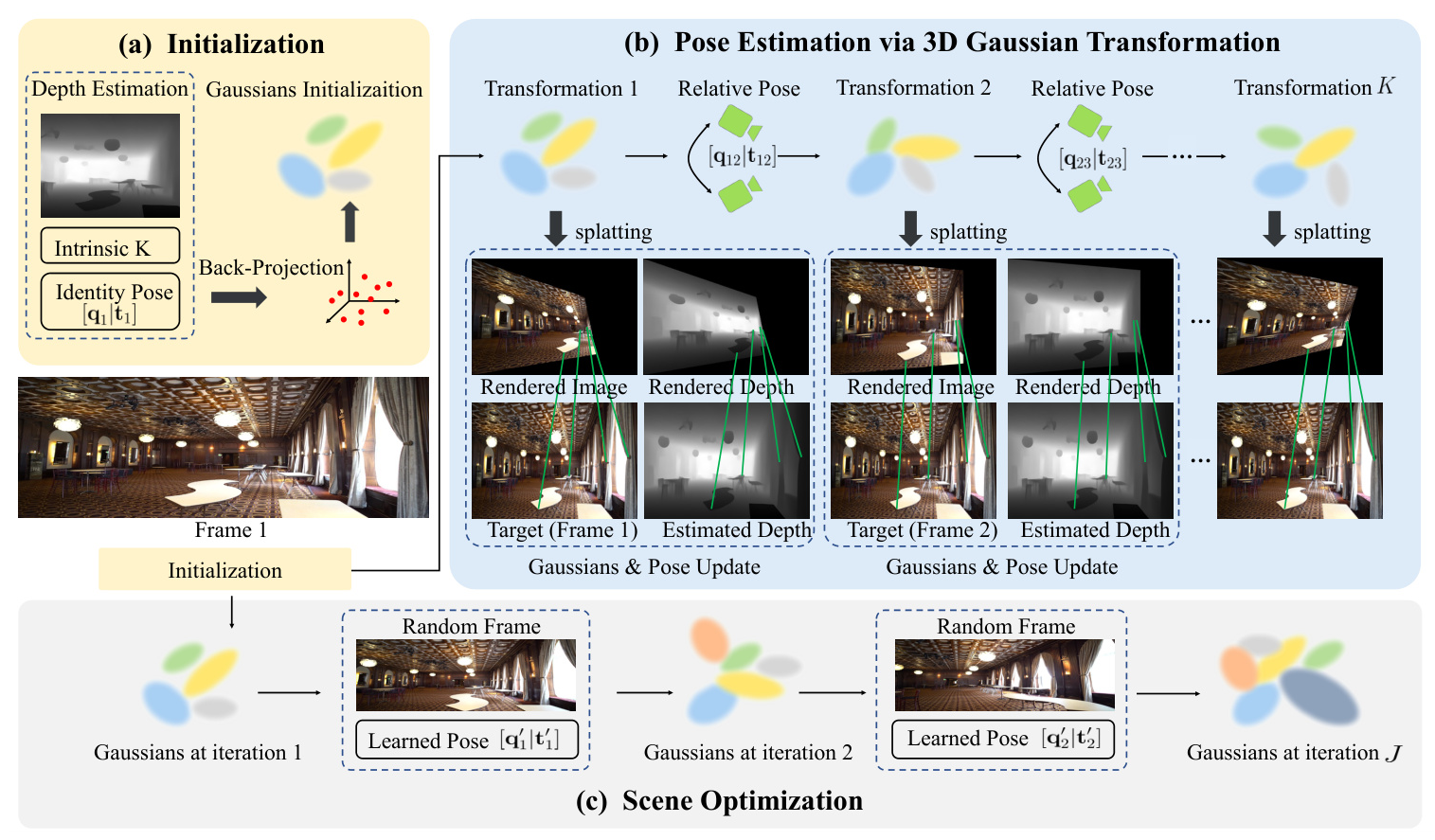
Initialization from Monocular Depth
The initial frame’s depth map is generated using a monocular depth network, and a point cloud is constructed by back-projecting the depth map. This point cloud initializes the 3D Gaussians, which are then optimized to reduce the correspondence-based loss between the rendered image and the ground truth.
Pose Estimation via 3D Gaussians Transformation
Camera pose estimation involves predicting the transformation of 3D Gaussians. A learnable SE-3 affine transformation is applied to the Gaussians, and the transformation is refined by minimizing the photometric loss between the rendered images and subsequent frames.
Correspondence-Based Loss
2D correspondences between the ground truth image and the rendered result are established using off-the-shelf detectors. The optimization objective is to align these correspondences, enabling gradient back-propagation from the 2D screen-space location to the associated 3D surface location. The correspondence-based loss consolidates RGB and depth matching components.
Approximated Surface Rendering
To transmit gradient information from 2D screen-space to 3D surface locations, an approximated surface rendering technique is employed. This method avoids time-consuming surface reconstruction and facilitates efficient optimization.
Scene Optimization
Following camera pose optimization, a new set of 3D Gaussians is optimized to represent the scene. The optimization process involves minimizing the photometric loss while keeping the camera poses fixed.
Experiments
Experimental Setup
Datasets
Experiments are conducted on real-world datasets, including Tanks and Temples and CO3D-V2. These datasets feature diverse scenes with varying levels of camera movement complexity.
Metrics
Performance is evaluated using standard metrics for novel view synthesis (PSNR, SSIM, LPIPS) and camera pose estimation (Absolute Trajectory Error, Relative Pose Error).
Implementation Details
The implementation leverages the PyTorch framework, with optimization parameters specified in 3DGS. Experiments are performed on a single RTX 3090 GPU.
Comparing with SfM-Free Methods
Novel View Synthesis
The proposed method consistently outperforms competing methods across all evaluated metrics, achieving superior PSNR values and producing sharper images with better retention of small objects.
Camera Pose Estimation
The learned camera poses achieve comparable performance with state-of-the-art results, demonstrating the robustness of the proposed method in scenarios with complex camera motions.
Performance in Complex Camera Motions
The method’s robustness is further validated on the CO3D videos, which feature intricate and demanding camera movements. The proposed method excels in both novel view synthesis and pose estimation, reinforcing its precision and robustness.
Ablation Study
Effectiveness of Correspondence
The impact of correspondence-guided optimization is assessed by comparing performance with traditional pixel-wise supervision. Correspondence-guided optimization significantly enhances both novel view synthesis and pose estimation accuracy.
Comparison with 3DGS with SfM Poses
The proposed method delivers performance on par with the conventional 3DGS model that utilizes SfM-derived poses, with significant improvements in challenging scenes.
Conclusion
The proposed Correspondence-Guided SfM-Free 3D Gaussian Splatting method enhances novel-view synthesis by avoiding SfM pre-processing. The approach effectively optimizes relative poses between frames through correspondence estimation and achieves a differentiable pipeline using an approximated surface rendering technique. Experimental results confirm the superiority of the method in terms of quality and efficiency.
Illustrations
- Overview of CG-3DGS: Initialization, Pose Estimation, and Scene Optimization

- Comparison of Traditional and Proposed Methods for Pixel Alignment

- Qualitative Comparison for Novel View Synthesis on Tanks and Temples

- Novel View Synthesis Results on Tanks and Temples

- Pose Accuracy on Tanks and Temples

- Novel View Synthesis Results on CO3D V2




