





Authors:
Xin Wang、Hector Delgado、Hemlata Tak、Jee-weon Jung、Hye-jin Shim、Massimiliano Todisco、Ivan Kukanov、Xuechen Liu、Md Sahidullah、Tomi Kinnunen、Nicholas Evans、Kong Aik Lee、Junichi Yamagishi
Paper:
https://arxiv.org/abs/2408.08739
Introduction
The ASVspoof initiative aims to advance the development of detection solutions, known as countermeasures (CMs) and presentation attack detection (PAD) solutions, to differentiate between genuine and spoofed or deepfake speech utterances. ASVspoof 5, the fifth edition of this challenge, introduces significant changes in track definitions, databases, spoofing attacks, and evaluation metrics. Unlike the 2021 challenge, which had distinct logical access (LA), physical access (PA), and speech deepfake (DF) sub-tasks, ASVspoof 5 combines LA and DF tasks into two tracks: (i) stand-alone spoofing and speech deepfake detection (CM, no ASV) and (ii) spoofing-robust automatic speaker verification (SASV).
Track 1 simulates a scenario where an attacker uses public data and speech deepfake technology to generate spoofed speech resembling a victim’s voice, which is then posted on social media. Track 2 assumes a telephony scenario where synthetic and converted speech are injected into a communication system without acoustic propagation. Participants can develop single classifiers or fused ASV and CM sub-systems, using either a pre-trained ASV sub-system provided by the organizers or their own bespoke systems.
Database
The ASVspoof 5 database has evolved significantly in terms of source data and attack algorithms. Built upon the MLS English dataset, it evaluates CM and SASV systems on detecting spoofing attacks using non-studio-quality data. The dataset includes data from over 4,000 speakers recorded with diverse devices, contrasting with the previous VCTK dataset, which had around 100 speakers recorded in an anechoic chamber.
The database construction involved three steps with two groups of data contributors. The first group used MLS partition A to build TTS systems, and the second group used MLS partition B to build and tune TTS and VC systems. These systems were then used to clone voices in MLS partition C, with some combined with adversarial attacking techniques like Malafide and Malacopula filters. The training, development, and evaluation sets are disjoint, ensuring no data leakage.




Performance Measures
Track 1: From EER to DCF
Track 1 submissions assign a real-valued bona fide-spoof detection score to each utterance. Unlike past ASVspoof challenges that used EER as the primary metric, Track 1 uses a normalized detection cost function (DCF). The DCF is defined as:
[ \text{DCF}(\tau_{cm}) = \beta \cdot P_{cm}^{\text{miss}}(\tau_{cm}) + P_{cm}^{\text{fa}}(\tau_{cm}) ]
where ( P_{cm}^{\text{miss}}(\tau_{cm}) ) is the miss rate and ( P_{cm}^{\text{fa}}(\tau_{cm}) ) is the false alarm rate, both functions of a detection threshold ( \tau_{cm} ). The constant ( \beta ) is defined as:
[ \beta = \frac{C_{\text{miss}}}{C_{\text{fa}}} \cdot \frac{1 – \pi_{\text{spf}}}{\pi_{\text{spf}}} ]
The primary metric for Track 1 is the minimum DCF (minDCF), with the actual DCF (actDCF) and cost of log-likelihood ratios (Cllr) as complementary metrics. EER is also reported.
Track 2: From SASV-EER to a-DCF
Track 2 allows submissions of either single SASV scores or a triplet of scores (SASV, CM, and ASV). The primary metric is the minimum architecture-agnostic detection cost function (a-DCF), defined as:
[ \text{a-DCF}(\tau_{sasv}) = \alpha P_{sasv}^{\text{miss}}(\tau_{sasv}) + (1 – \gamma) P_{sasv}^{\text{fa,non}}(\tau_{sasv}) + \gamma P_{sasv}^{\text{fa,spf}}(\tau_{sasv}) ]
where ( P_{sasv}^{\text{miss}}(\tau_{sasv}) ) is the ASV miss rate, ( P_{sasv}^{\text{fa,non}}(\tau_{sasv}) ) is the false alarm rate for non-targets, and ( P_{sasv}^{\text{fa,spf}}(\tau_{sasv}) ) is the false alarm rate for spoofing attacks. The constants ( \alpha ) and ( \gamma ) are defined as:
[ \alpha = \frac{C_{\text{miss}} \pi_{\text{tar}}}{C_{\text{fa,non}} \pi_{\text{non}} + C_{\text{fa,spf}} \pi_{\text{spf}}} ]
[ \gamma = \frac{C_{\text{fa,spf}} \pi_{\text{spf}}}{C_{\text{fa,non}} \pi_{\text{non}} + C_{\text{fa,spf}} \pi_{\text{spf}}} ]
The primary metric is the minimum a-DCF (min a-DCF), with ASV-constrained minimum tandem detection cost function (t-DCF) and tandem equal error rate (t-EER) as additional metrics.


Common ASV, Surrogate Systems, and Challenge Baselines
Common ASV System by Organizers
The common ASV system uses an ECAPA-TDNN speaker encoder and cosine similarity scoring, trained on VoxCeleb 1 and 2. The ASV EER values on the evaluation data show higher EERs when spoofing attacks are mounted.

Baseline Systems
Track 1 adopts RawNet2 and AASIST as CM baseline systems, both operating on raw waveforms. Track 2 uses a fusion-based system and a single integrated system, with the latter performing better in evaluations.
Surrogate Systems
The surrogate ASV system is based on ECAPA-TDNN with a probabilistic linear discriminant analysis scoring backend. Surrogate CM systems include AASIST, RawNet2, and LCNNs with LFCC, trained on bona fide data from MLS partition A and spoofed attacks created by the first group of data contributors.
Evaluation Platform
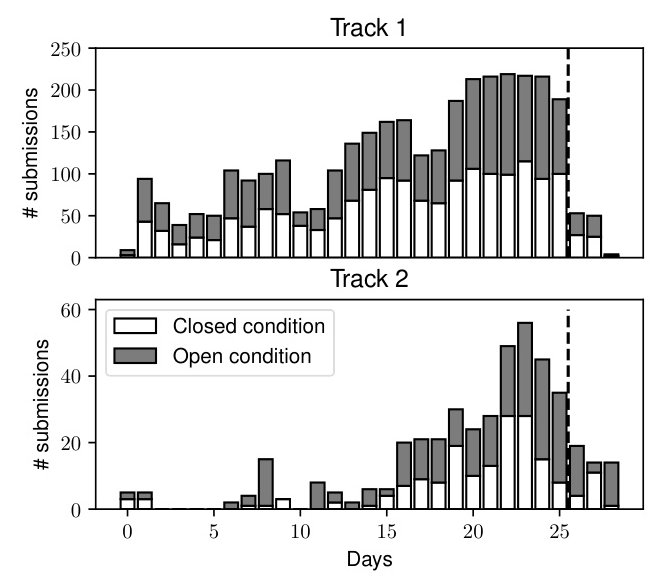
ASVspoof 5 used the CodaLab website for submissions and results. The challenge had two phases: a progress phase with daily submissions and an evaluation phase with a single submission. The number of submissions during these phases is illustrated below.

Challenge Results
Track 1
Results for Track 1 show that most submissions in the closed condition outperformed the baselines in terms of minDCF. The top-5 submissions achieved minDCF values below 0.5 and EERs below 15%. In the open condition, submissions using pre-trained self-supervised learning (SSL) models performed better.

Track 2
Track 2 results indicate that spoofing-robust ASV is more demanding than stand-alone CM. Most submissions outperformed the baselines, with the top-3 submissions in the closed condition showing significant improvements in min a-DCF values. The use of SSL-based features was common among top submissions.


Conclusions
ASVspoof 5 supports the evaluation of both stand-alone speech spoofing and deepfake detection and SASV solutions. The challenge introduced more complex tasks, crowd-sourced data, advanced spoofing attacks, and new adversarial attacks. Despite the use of lower-quality data, most challenge submissions outperformed the baselines, highlighting the need for further research and improvements in score calibration.
Acknowledgements
The ASVspoof 5 organizing committee thanks the challenge participants and data contributors. The challenge was supported by various organizations and funding bodies, including A*STAR, Pindrop, KLASS Engineering, JST, PRESTO, the French Agence Nationale de la Recherche, and the Academy of Finland. Part of the work used the TSUBAME4.0 supercomputer at Tokyo Institute of Technology.


