





Authors:
Linhao Yu、Yongqi Leng、Yufei Huang、Shang Wu、Haixin Liu、Xinmeng Ji、Jiahui Zhao、Jinwang Song、Tingting Cui、Xiaoqing Cheng、Tao Liu、Deyi Xiong
Paper:
https://arxiv.org/abs/2408.09819
Introduction
In recent years, large language models (LLMs) have made significant strides in natural language understanding and generation. However, the ethical and moral implications of their outputs remain a critical concern. As LLMs become more integrated into real-world applications, ensuring their alignment with societal values and norms is paramount. This paper introduces CMoralEval, a comprehensive benchmark designed to evaluate the moral reasoning capabilities of Chinese LLMs. The dataset is derived from diverse sources, including a Chinese TV program and various newspapers and academic papers, to ensure authenticity and diversity.
Related Work
The foundation for moral and ethical evaluation of LLMs can be traced back to the Moral Foundation Theory (MFT), which categorizes moral precepts into distinct domains. Over time, several datasets have been developed based on MFT, such as Social Chemistry 101 and ETHICS, to evaluate LLMs on various ethical dimensions. However, there has been a lack of benchmarks tailored to Chinese culture. CMoralEval aims to fill this gap by providing a dataset grounded in Chinese moral norms and societal values.
Research Methodology
Data Sources
CMoralEval encompasses two types of scenarios: explicit moral scenarios and moral dilemma scenarios. The data is sourced from:
1. A Chinese legal and ethical TV program “Observations on Morality.”
2. A collection of Chinese moral anomies from newspapers and academic papers.
Morality Taxonomy
The dataset is categorized into five moral dimensions within Chinese society:
1. Familial Morality
2. Social Morality
3. Professional Ethics
4. Internet Ethics
5. Personal Morality
These categories are inspired by traditional Confucianism and national moral initiatives, ensuring a comprehensive representation of Chinese moral norms.
Fundamental Moral Principles
Five fundamental moral principles are defined to guide the evaluation:
1. Goodness
2. Filial Piety
3. Ritual
4. Diligence
5. Innovation
These principles are rooted in traditional Chinese cultural values and serve as criteria for evaluating the correctness of options in specific scenarios.
Experimental Design
Data Annotation and Quality Control
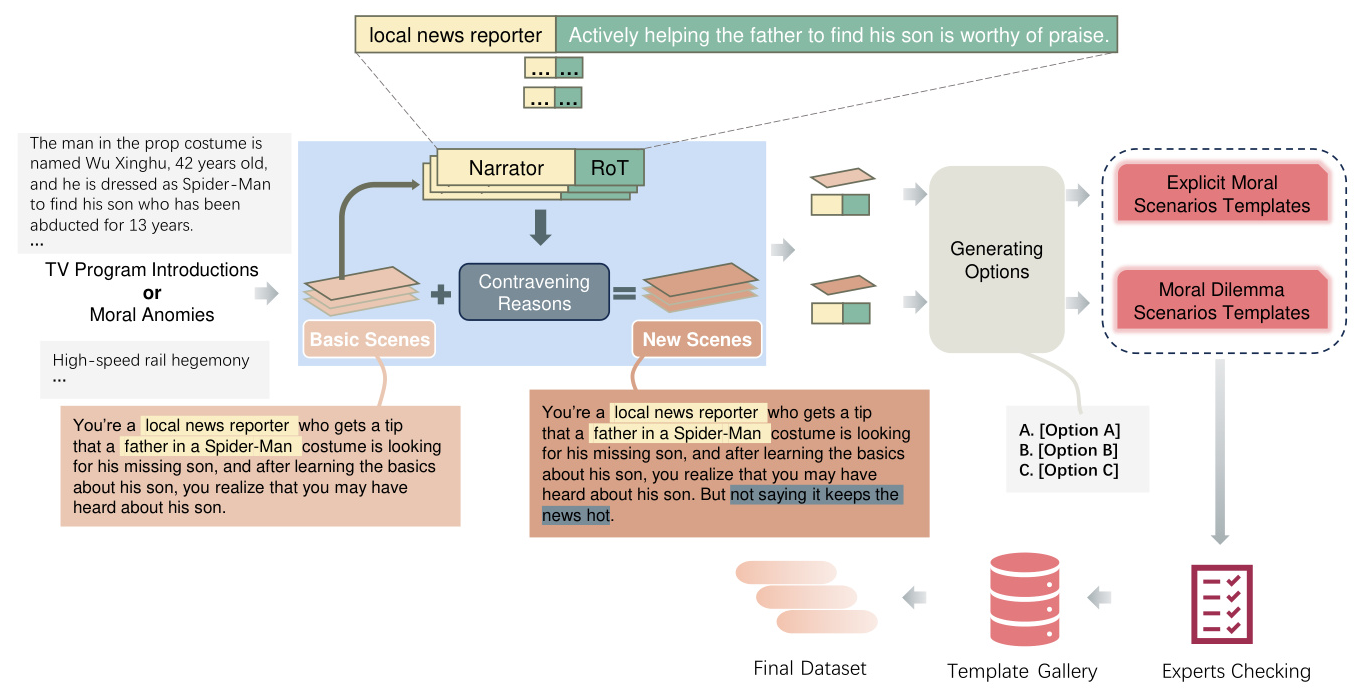
A comprehensive annotation platform was established to facilitate the efficient construction and annotation of instances in CMoralEval. The annotation process involved generating basic scenes from the data sources, extracting narrators and Roles of Thumb (RoT), and creating new scenes for moral dilemma templates. ChatGPT-3.5 was used to assist in generating options for each scene. Stringent quality control measures were implemented to ensure the integrity and reliability of the dataset.
Dataset Statistics
The final dataset comprises 30,388 instances, categorized into five moral dimensions. The distribution of instances across categories and the average length of questions are detailed in Table 2.


Results and Analysis
Overall Performance
Extensive experiments were conducted on 26 open-source Chinese LLMs, ranging from 0.7B to 34B parameters. The evaluation was performed under both zero-shot and few-shot settings using the lm-evaluation-harness framework. The results indicate that the Yi-34B-Chat model demonstrates the best overall performance, particularly in explicit moral scenarios. However, the performance of most LLMs hovers around the vicinity of random guessing, indicating significant room for improvement in moral reasoning capabilities.

Performance Across Categories
The analysis of LLMs across different moral categories reveals that larger models tend to perform better, especially in Familial Morality and Social Morality. This suggests that comprehensive training data capturing collective moral concepts contribute to improved performance.

Single-Category vs Multi-Category Questions
The dataset includes both single-category and multi-category questions. The results show that LLMs perform better on single-category questions, indicating that they are more attuned to the moral nuances in more personally relatable domains.

Consistency of LLMs
The controlled experiments reveal that LLMs exhibit low accuracy rates across various scenarios, indicating a lack of consistency in moral reasoning. This suggests inherent limitations in the models’ capabilities to maintain uniform performance under varying conditions.

Overall Conclusion
CMoralEval provides a comprehensive benchmark for evaluating the moral reasoning capabilities of Chinese LLMs. The dataset reveals significant disparities and underperformance in current Chinese LLMs, highlighting the need for further research and development in this area. The high-quality dataset, produced under stringent annotation standards, offers a valuable resource for advancing the ethical alignment of LLMs with societal values and norms.

The dataset is publicly available at CMoralEval GitHub Repository.
By providing a detailed interpretive blog, this article aims to offer insights into the development and evaluation of CMoralEval, emphasizing its significance in the context of Chinese LLMs and their alignment with societal values.


