





1. Abstract
This paper introduces CHAIN-OF-KNOWLEDGE (CoK), a framework designed to enhance Large Language Models’ (LLMs) knowledge reasoning abilities by integrating knowledge from Knowledge Graphs (KGs). CoK consists of two main components:
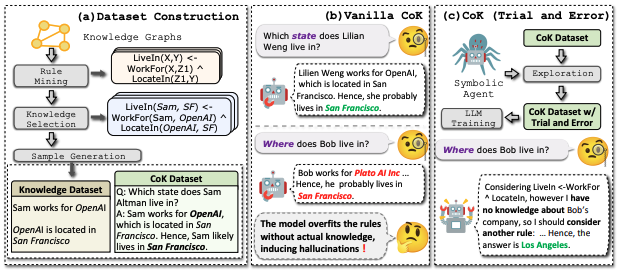
- Dataset Construction: The authors create the KNOWREASON dataset by mining compositional rules from KGs, selecting relevant triples, and generating natural language samples.
- Model Learning: CoK employs a trial-and-error mechanism to prevent rule overfitting, simulating the human process of internal knowledge exploration.
Extensive experiments demonstrate the effectiveness of CoK in improving LLMs’ knowledge reasoning abilities and general reasoning performance on various benchmarks.
2. Rapid Reading
a. Research Methodology
- Innovation and Improvement: CoK addresses the underexplored area of knowledge reasoning in LLMs, offering a comprehensive framework for dataset construction and model learning. The trial-and-error mechanism is a key innovation that mitigates rule overfitting, improving generalization.
- Problem Solved: CoK addresses the limitations of existing LLMs in handling complex reasoning tasks, particularly knowledge reasoning. By leveraging KGs and incorporating trial-and-error learning, CoK enables LLMs to reason more effectively and generalize better to unseen rules.
b. Experiment Process
- Design: The authors conducted experiments in both anonymized and regular settings. In the anonymized setting, they evaluated the impact of CoK on knowledge reasoning abilities without the influence of LLMs’ inherent knowledge. In the regular setting, they assessed the effectiveness of CoK in real-world scenarios and its impact on general reasoning abilities.
- Dataset: The KNOWREASON dataset, constructed using rules mined from Wikidata, served as the primary training data. The dataset was divided into anonymized and regular versions, with the anonymized version used for continuous pretraining and the regular version for instruction fine-tuning.
- Experiment Results: CoK and CoK (T&E) consistently outperformed baselines on both ID and OOD datasets in the anonymized setting, demonstrating their effectiveness in improving knowledge reasoning abilities. CoK (T&E) further reduced rule dependency, leading to better generalization on OOD datasets. In the regular setting, CoK (T&E) also showed significant improvements on downstream tasks, highlighting its broader utility.
- Significance: The results indicate that CoK effectively enhances LLMs’ knowledge reasoning abilities and general reasoning performance. The trial-and-error mechanism is crucial for mitigating rule overfitting and improving generalization.
c. Main Advantages
- Comprehensive Framework: CoK provides a systematic approach to integrating knowledge reasoning into LLMs, encompassing dataset construction and model learning.
- Trial-and-Error Mechanism: This innovative technique addresses the issue of rule overfitting, enabling LLMs to generalize better to unseen rules.
- Broad Utility: CoK improves LLMs’ performance not only on knowledge reasoning tasks but also on other reasoning benchmarks, demonstrating its potential for various applications.
3. Summary
a. Contributions
- Research Methodology: CoK offers a novel framework for enhancing LLMs’ knowledge reasoning abilities, including dataset construction and model learning with trial-and-error.
- Experiment Results: Extensive experiments demonstrate the effectiveness of CoK in improving knowledge reasoning abilities and general reasoning performance.
- Conclusion: CoK effectively integrates knowledge reasoning into LLMs, enabling them to reason more effectively and generalize better to unseen rules.
b. Main Innovations
- Trial-and-Error Mechanism: This innovative technique addresses the issue of rule overfitting, improving generalization and making CoK more robust.
- Comprehensive Framework: CoK provides a systematic approach to knowledge reasoning, making it easier to implement and apply in various scenarios.
c. Future Research Directions
- Exploring More Complex Rules: Investigating the impact of longer and more complex rules on knowledge reasoning abilities and generalization.
- Expanding to Other Domains: Applying CoK to other domains beyond knowledge reasoning, such as commonsense reasoning and symbolic reasoning.
- Combining with Other Techniques: Integrating CoK with other techniques, such as few-shot prompting and reinforcement learning, to further enhance LLMs’ reasoning abilities.
View PDF:https://arxiv.org/pdf/2407.00653


