





Authors:
Dario Zanca、Andrea Zugarini、Simon Dietz、Thomas R. Altstidl、Mark A. Turban Ndjeuha、Leo Schwinn、Bjoern Eskofier
Paper:
https://arxiv.org/abs/2408.09948
Introduction
Background and Motivation
Understanding human attention is a pivotal aspect of vision science and artificial intelligence (AI). Human visual attention allows for selective processing of relevant visual information while ignoring irrelevant details. This cognitive process is essential for various applications, including neuroscience and AI-driven technologies. Traditional models of human attention have primarily focused on free-viewing scenarios, where the observer’s gaze is driven by bottom-up saliency. However, less is known about task-driven image exploration, where the observer’s gaze is influenced by specific tasks, such as image captioning.
Problem Statement
To bridge this gap, the study introduces CapMIT1003, a dataset designed to study human attention during captioning tasks. Additionally, the study presents NevaClip, a zero-shot method for predicting visual scanpaths by combining Contrastive Language-Image Pretrained (CLIP) models with Neural Visual Attention (NeVA) algorithms. NevaClip aims to generate fixations that align the representations of foveated visual stimuli and captions, thereby enhancing our understanding of human attention and advancing scanpath prediction models.
Related Work
Existing Models of Human Attention
Previous research has extensively explored the relationship between eye movement patterns and high-level cognitive factors, demonstrating the influential role of task demands on visual attention. Seminal works have investigated how different tasks affect eye movements and visual attention dynamics. Despite the significant interest in task-driven visual exploration, most existing computational models, whether classical or machine learning-based, have focused on free-viewing scenarios, overlooking the influence of specific tasks.
Contributions of the Study
To address this gap, the study proposes computational models that simulate human attention scanpaths during the captioning process. The study introduces CapMIT1003, an expanded version of the MIT1003 dataset, which includes click-contingent task-driven image exploration. Furthermore, the study combines NeVA algorithms with CLIP models to generate task-driven scanpaths under human-inspired constraints of foveated vision, achieving state-of-the-art results for the newly collected dataset.
Research Methodology
CapMIT1003 Dataset
The CapMIT1003 dataset was developed using a web application that presents images from the MIT1003 dataset to participants. Participants are prompted to provide captions while performing click-contingent image explorations, simulating foveated vision. Each click reveals information in an area corresponding to two degrees of visual angle, and participants can click up to 10 times before providing a caption. The dataset includes 27,865 clicks on 4,573 observations over 153 sessions, with all clicks and captions stored in a database.
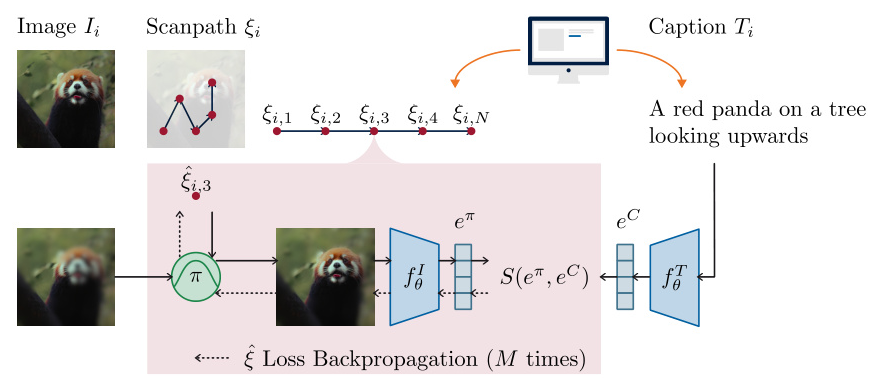
NevaClip Algorithm
The NevaClip algorithm predicts visual scanpaths by combining past predicted fixations with an initial guess to create a foveated version of the image. This foveated image is passed to CLIP’s vision embedding network to obtain an image embedding. The cosine similarity loss between the image embedding and the text embedding (obtained by passing the caption to CLIP’s text embedding network) is computed to measure how well the current scanpath aligns with the given caption. By backpropagating this loss and updating the fixation accordingly, NevaClip finds the fixation that minimizes the alignment loss.


Experimental Design
Experimental Setup
The experimental setup adheres to the original implementation of the NeVA algorithm, with 20 optimization steps adapted to run on CLIP backbones. The study evaluates three variations of the NevaClip algorithm: NevaClip (correct caption), NevaClip (different caption, same image), and NevaClip (different caption, different image). Two baselines (Random and Center) and four competitor models are included for comparison.
Baselines and Models
The study evaluates the performance of NevaClip against several baselines and competitor models. The Random and Center baselines provide a reference for the quality of the results. The competitor models include G-Eymol, Neva (original), CLE, and WTA+Itti. The performance is measured using ScanPath Plausibility (SPP) scores, computed for each sublength and averaged across all sublengths.
Results and Analysis
ScanPath Plausibility
The results show that NevaClip (correct caption) outperforms all other approaches in the CapMIT1003 (captioning task) dataset. NevaClip (different caption, same image) performs slightly worse, while NevaClip (different caption, different image) performs similarly to the Random baseline. Among competitors, G-Eymol and Neva (original) perform well despite not incorporating any caption information. In the MIT1003 (free-viewing) dataset, NevaClip (correct caption) and NevaClip (different caption, same image) also perform better than state-of-the-art models, indicating a substantial overlap between the two tasks.

Analysis of Results
The results suggest that capturing attention in captioning tasks is more challenging than in free-viewing tasks, as it involves multiple factors such as image content, language, and semantic coherence. The ranking of models remains consistent across both tasks, with free-viewing models performing reasonably well on both datasets. This observation indicates that the initial phases of exploration are predominantly driven by bottom-up factors rather than task-specific demands.
Overall Conclusion
Summary of Findings
The study introduces CapMIT1003, a dataset designed to study human attention during captioning tasks, and presents NevaClip, a zero-shot method for predicting visual scanpaths. The results demonstrate that NevaClip outperforms existing human attention models in plausibility for both captioning and free-viewing tasks. The study enhances our understanding of human attention and advances scanpath prediction models.
Future Directions
A possible limitation of the study is the click-contingent data collection method. Future studies may complement this data collection with actual gaze data and explore differences between the two modalities. Additionally, further research could investigate the application of NevaClip in other task-driven visual exploration scenarios to validate its generalizability and robustness.
By addressing these limitations and exploring new directions, future research can continue to advance our understanding of human visual attention and improve the performance of scanpath prediction models.


