





Authors:
Zhongjian Zhang、Xiao Wang、Huichi Zhou、Yue Yu、Mengmei Zhang、Cheng Yang、Chuan Shi
Paper:
https://arxiv.org/abs/2408.08685
Graph Neural Networks (GNNs) have shown remarkable success in various applications by leveraging their message-passing mechanisms to extract useful information from graph data. However, GNNs are highly vulnerable to adversarial attacks, particularly topology attacks, which can significantly degrade their performance. This paper explores the potential of Large Language Models (LLMs) to enhance the adversarial robustness of GNNs. The authors propose a novel framework, LLM4RGNN, which leverages the inference capabilities of LLMs to identify and mitigate adversarial perturbations in graph structures.
Introduction
Graph Neural Networks (GNNs) are powerful tools for learning representations from graph data. Despite their success, GNNs are susceptible to adversarial attacks, especially topology attacks, where slight perturbations in the graph structure can lead to a significant drop in performance. This vulnerability poses challenges for deploying GNNs in security-critical applications such as finance and medical networks.
Recent advancements in Large Language Models (LLMs) have shown their potential in enhancing the performance of GNNs by improving node features. However, it remains unclear whether LLMs can also enhance the adversarial robustness of GNNs. This paper investigates this question and proposes an LLM-based robust graph structure inference framework, LLM4RGNN, to improve the robustness of GNNs against adversarial attacks.
Preliminaries
Text-attributed Graphs (TAGs)
A Text-attributed Graph (TAG) is defined as ( G = (V, E, S) ), where ( V ) is the set of nodes, ( E ) is the set of edges, and ( S ) is the set of textual information associated with the nodes. The adjacency matrix ( A ) represents the connections between nodes. The goal is to train a GNN to predict the labels of unlabeled nodes based on the node features encoded from the text set ( S ).
Graph Adversarial Robustness
The paper focuses on poisoning attacks, which directly modify the training data to degrade the model’s performance. The adversarial robustness of a model ( f ) against poisoning attacks is defined as:
[ \max_{\delta \in \Delta} \min_{\theta} L(f_{\theta}(G + \delta), y_T) ]
where ( \delta ) represents the perturbation to the graph ( G ), ( \Delta ) represents all permitted perturbations, ( y_T ) is the node labels of the target set ( T ), ( L ) denotes the training loss, and ( \theta ) are the model parameters. The goal is to minimize the loss under the worst-case perturbation.
The Adversarial Robustness of GNNs Combining LLMs/LMs
The authors empirically investigate the robustness of GNNs combined with six LLMs/LMs against the Mettack attack with a 20% perturbation rate on the Cora and PubMed datasets. The results show that these models suffer from a significant decrease in accuracy, indicating that GNNs combined with LLMs/LMs remain vulnerable to topology perturbations.


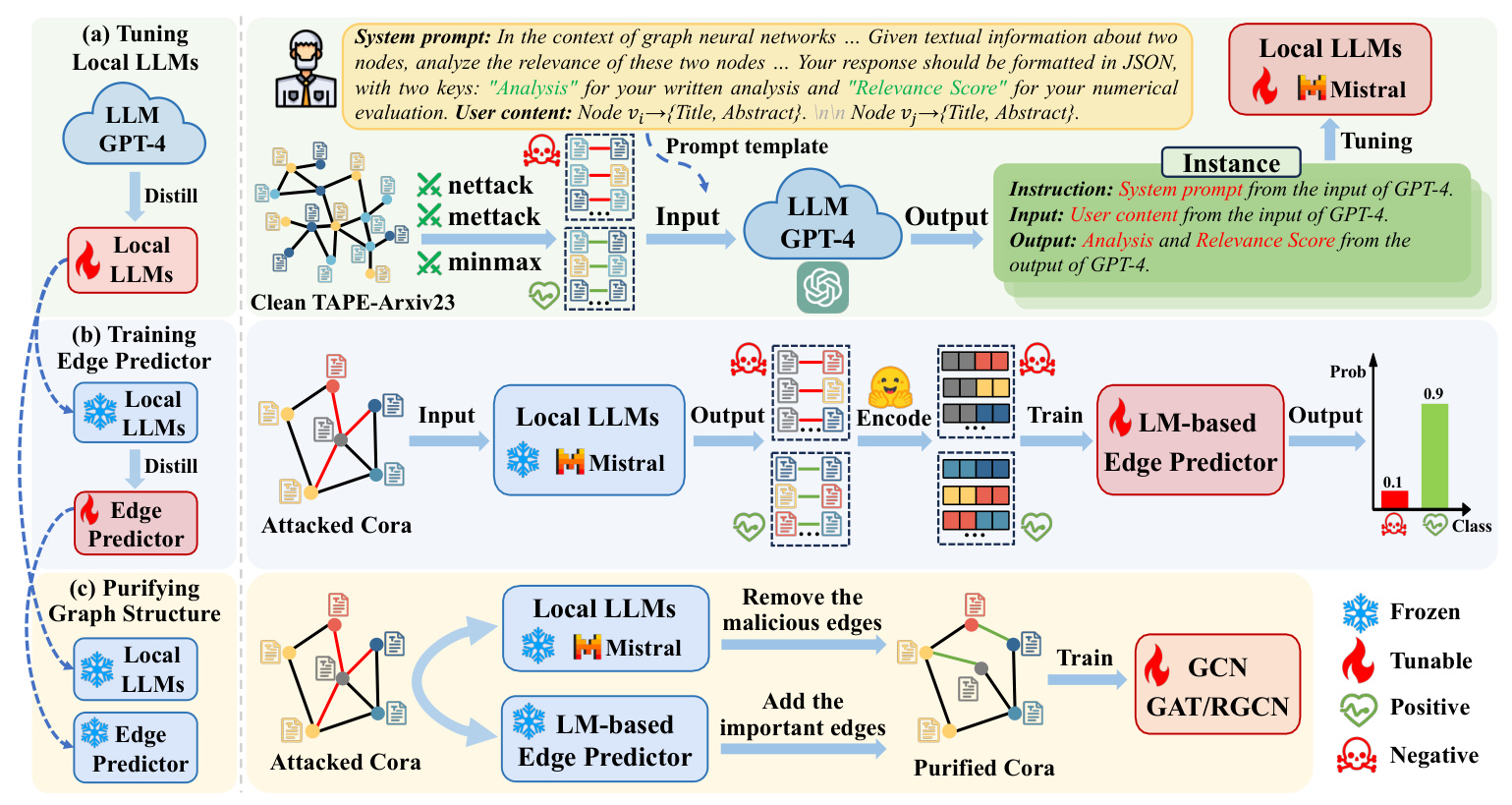
LLM4RGNN: The Proposed Framework
The proposed framework, LLM4RGNN, aims to enhance the robustness of GNNs by leveraging the inference capabilities of LLMs to identify and mitigate adversarial perturbations in graph structures.
Instruction Tuning a Local LLM
The framework involves instruction tuning a local LLM to distill the inference capability of GPT-4 into a local LLM for identifying malicious edges. The process involves constructing an instruction dataset using GPT-4’s assessments and analyses of edges, which is then used to fine-tune a local LLM.

Training an LM-based Edge Predictor
An LM-based edge predictor is trained to find missing important edges. The predictor uses sentence embeddings to encode the textual information of nodes and a multilayer perceptron (MLP) to predict the existence of important edges.
Purifying Attacked Graph Structure
The final step involves purifying the attacked graph structure by removing malicious edges and adding important edges identified by the local LLM and the edge predictor. This process aims to recover a robust graph structure, making GNNs more resilient to adversarial attacks.
Experiments
Experimental Setup
The experiments are conducted on four citation networks (Cora, Citeseer, PubMed, OGBN-Arxiv) and one product network (OGBN-Products). The robustness of various GNNs is evaluated against three popular poisoning topology attacks: Mettack, DICE, and Nettack.
Main Results
The results demonstrate that LLM4RGNN consistently improves the robustness of various GNNs across different datasets and attack scenarios. The framework achieves state-of-the-art (SOTA) robustness, even in cases where the perturbation ratio is high.

Model Analysis
Ablation Study
An ablation study is conducted to assess the contribution of key components of LLM4RGNN. The results show that both the local LLM and the edge predictor significantly contribute to improving the robustness of GNNs.

Comparison with Different LLMs
The framework’s generalizability is evaluated using different LLMs, including open-source models like Llama2 and Mistral. The results indicate that the well-tuned local LLMs are effective in identifying malicious edges and improving the robustness of GNNs.

Efficiency Analysis
The efficiency of LLM4RGNN is analyzed, showing that the framework does not significantly increase the complexity compared to existing robust GNN frameworks. The inference processes are parallelizable, making the framework practical for real-world applications.

Hyper-parameter Analysis
The sensitivity of LLM4RGNN to various hyper-parameters is analyzed. The results indicate that the framework is robust to different hyper-parameter settings, demonstrating its practicality and ease of use.

Conclusion
The paper explores the potential of LLMs to enhance the adversarial robustness of GNNs. The proposed framework, LLM4RGNN, leverages the inference capabilities of LLMs to identify and mitigate adversarial perturbations in graph structures. Extensive experiments demonstrate that LLM4RGNN significantly improves the robustness of GNNs, achieving SOTA defense results. Future work includes extending the framework to graphs without textual information.



