





Authors:
Maxim Ifergan、Leshem Choshen、Roee Aharoni、Idan Szpektor、Omri Abend
Paper:
https://arxiv.org/abs/2408.10646
Introduction
Pretrained large language models (LLMs) have shown an impressive ability to encode and retrieve factual knowledge across various languages. However, there is a significant variation in their performance across different languages, with a noticeable bias towards high-resource languages. This inconsistency raises questions about how LLMs represent factual knowledge in different languages. Do they store distinct knowledge copies for each language, or do they use a single, shared representation of the factual knowledge that is decoded into different languages?
This study explores multilingual factual knowledge through two main aspects: the model’s ability to answer a query consistently across languages and the ability to “store” answers in a shared representation for several languages. By repurposing knowledge editing methods, the study aims to measure the extent of representation sharing across languages. The findings reveal that high consistency does not necessarily imply shared representation, particularly for languages with different scripts. Moreover, script similarity is found to be a dominant factor in representation sharing.
Related Work
Cross-lingual Knowledge Consistency
Previous studies have highlighted the issue of cross-lingual knowledge inconsistency in LLMs. While monolingual knowledge consistency has been extensively studied, limited work has been done on cross-lingual knowledge consistency. Some studies have proposed metrics to measure similarity across multiple candidate answers, whether correct or incorrect. However, these approaches often focus on pairwise language comparisons and do not provide a comprehensive assessment of cross-lingual knowledge consistency.
Cross-lingual Knowledge Representation Sharing
Several studies have explored cross-lingual knowledge representation sharing through different approaches. Some have analyzed neuron activation/deactivation when evaluating knowledge in different languages, while others have investigated the language source of the acquired data. These studies have shown that semantically equivalent content in different languages tends to produce similar activation patterns, suggesting a connection between knowledge in different languages. However, these studies do not provide a quantitative assessment of the amount of shared knowledge.
Multilingual Knowledge Editing
Previous work on multilingual knowledge editing has primarily focused on comparing and improving editing methods’ performance in multilingual settings. This study, however, uses these editing tools as analytical tools to understand representation sharing across languages and across models with different multilingual configurations.
Research Methodology
Measuring Cross-lingual Knowledge Consistency (CKC)
To measure CKC, the study defines a model’s Knowledge Base (KB) for a specific language as a set of facts the LLM knows in that language. The pairwise relationship of knowing a fact in one language to knowing it in another is captured by defining the conditional probability of a fact being known in one language given that it is known in another. The overall CKC of a model is computed as the average number of languages in which the LLM knows a fact.
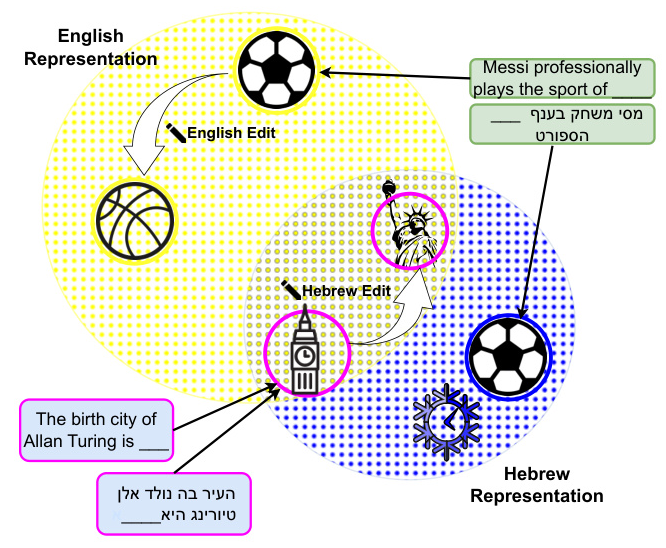
Measuring Cross-lingual Knowledge Representation Sharing (CKR)
Measuring CKR requires more than just evaluating model outputs. The study uses an editing method that modifies the model’s parameters to provide a wrong answer for a query in a given language and examines the impact of such a change on the same fact query in other languages. The amount of pairwise CKR between languages is estimated by defining the conditional probability of a fact being represented in one language given that it is represented in another.
Experimental Design
Data
The study introduces CLIKE (Cross-LIngual Knowledge Editing), a dataset for evaluating and editing factual knowledge of pretrained LMs across languages and paraphrased expressions. CLIKE contains approximately 35k facts spanning 13 languages with 7 scripts. Each fact is modeled as a language-independent (subject, relation, object) triplet, and each relation has 3 paraphrased natural language templates for every language.
Models
The study examines a range of LLMs with 7B parameters and decoder-only architectures. These include multilingual models (BLOOM-7B), bilingual models (Qwen-7B), monolingual English models (Llama-2-7B and Mistral-7B-v0.1), and language-extended models (Chinese-llama-2-7B and Hebrew-Mistral-7B).
Knowledge Editing Methods
Three knowledge editing methods are employed: Finetuning (FT), ROME, and MEMIT. These methods leverage causal mediation analysis to identify and modify the relevant components of the model responsible for storing factual knowledge. The EasyEdit code library is used to perform all language model knowledge edits.
Metrics and Evaluation
The Exact Match (EM) metric is used to evaluate all answers to queries across the experiments. Model performance and CKC in a given language are assessed by computing the overall accuracy for a language and the mean score in one language across all paraphrases for facts known in another language. For the knowledge editing experiments, the effectiveness of edits is assessed using three standard metrics: Reliability, Generalization, and Locality.
Results and Analysis
The Issue of Knowledge Variability
LLMs exhibit significant variability in their factual knowledge retrieval across different languages. The analysis reveals a striking disparity: while models demonstrate knowledge of 42.5% of the facts on average in at least one language, their best-performing language achieves only 27.6% accuracy, and their average performance across all 13 languages in the CLIKE dataset is merely 11.8%. If models could share knowledge across all languages, the best-performing language could potentially increase its accuracy by up to 53%.


Consistency Does Not Imply Representation Sharing
The study decouples CKC and CKR between languages, examining both general measures across languages and pairwise language relationships. The analysis reveals that high CKC does not necessarily imply high CKR. Models tend to exhibit CKC across more languages than they share representations between. This persistent gap highlights that consistent answers do not necessarily translate to shared internal representations.

The Key Role of the Language Script
The study highlights the importance of the script of a language for multilingual knowledge. Languages within the same script family exhibit the highest degree of CKR across all models. While most CKR occurs among languages that use the same script, there is still some knowledge transfer between languages with different scripts. This cross-script transfer is particularly evident between Cyrillic and Latin script languages.

Impact of Model Design Languages
The study reveals that the design of a model’s language support affects its CKR and CKC patterns. Multilingual models like BLOOM demonstrate notable transfer between seemingly unrelated language pairs, while bilingual models like Qwen show high accuracy in their primary languages but limited cross-script knowledge sharing. Monolingual English models exhibit strong associations between script similarity and knowledge sharing even in ostensibly monolingual models.
Language Extended LMs
Additional pretraining on both English and an extended language (EL) impacts cross-lingual CKC and shared representation in initially monolingual models. While gaining substantial knowledge in EL, models sacrifice much of their original English expertise. This suggests that even with targeted pretraining, models struggle to forge robust representations sharing across linguistically distant languages.

Overall Conclusion
This study investigated the relationship between cross-lingual knowledge consistency and representation sharing in LLMs. The findings reveal that high consistency across languages does not necessarily imply shared internal representations, particularly for languages with different scripts. The study introduced a novel methodology and dataset for quantifying these phenomena, providing a more nuanced understanding of how LLMs represent and retrieve factual knowledge. The significant disparity observed in factual knowledge retrieval across languages underscores the importance of developing more effective multilingual knowledge representations. These insights are expected to guide the development of more efficient and equitable multilingual models, ultimately enhancing their performance across all languages.
Limitations
The main limitation of this study lies in the constraints imposed by the chosen editing methods and their focus on specific model components. By primarily targeting middle layers associated with factual knowledge storage, the analysis may have overlooked important cross-lingual interactions occurring elsewhere in the model architecture. Additionally, the study focused exclusively on decoder-only language models with 7B parameters, limiting the generalizability of the findings across different architectures and sizes. The CLIKE dataset, while diverse, may not fully represent the breadth of factual knowledge or linguistic phenomena, potentially influencing the observed patterns of cross-lingual representation.


