





Authors:
Xiaomeng Jin、Jeonghwan Kim、Yu Zhou、Kuan-Hao Huang、Te-Lin Wu、Nanyun Peng、Heng Ji
Paper:
https://arxiv.org/abs/2408.10086
Introduction
Multimodal Language Models (MLMs) have shown remarkable capabilities in understanding and integrating various modalities, including text, images, and videos. However, the process of manually annotating high-quality image-text pair data for fine-tuning and alignment is both costly and time-consuming. Existing multimodal data augmentation frameworks often face challenges such as semantic inconsistency between texts and images or the generation of unrealistic images, leading to a knowledge gap with real-world examples. To address these issues, the authors propose ARMADA (Attribute-Based Multimodal Data Augmentation), a novel method that leverages knowledge-guided manipulation of visual attributes of mentioned entities to generate semantically consistent and realistic image-text pairs.
Related Work
External Knowledge Proxies
External symbolic knowledge bases (KBs) like Wikidata and large language models (LLMs) contain vast amounts of real-world, entity-centric knowledge. While symbolic KBs have been used in various domains of natural language processing for augmentation, their use in the multimodal domain is still underexplored. LLMs, despite their occasional hallucinatory outputs, possess rich world knowledge that enables them to generalize attributes of various kinds. ARMADA combines the relational knowledge of KBs and the generalization abilities of LLMs to perform knowledge-guided multimodal data augmentation.
Vision Language Models
Vision Language Models (VLMs) have achieved state-of-the-art performances across various downstream tasks such as image-to-text retrieval and visual question answering (VQA). However, these models require extensive amounts of image-text pair datasets for pre-training or fine-tuning, highlighting the need for robust augmentation methods.
Data Augmentation
Existing data augmentation methods primarily focus on augmenting a single modality, either text or image. In the multimodal domain, methods like MixGen and LeMDA have been proposed, but they often suffer from issues such as low-quality generated data or lack of interpretability and controllability. ARMADA aims to address these limitations by leveraging entity-related attributes from knowledge bases and using LLMs for entity-independent perturbations.
Research Methodology
Extracting Entities and Visual Attributes from Text
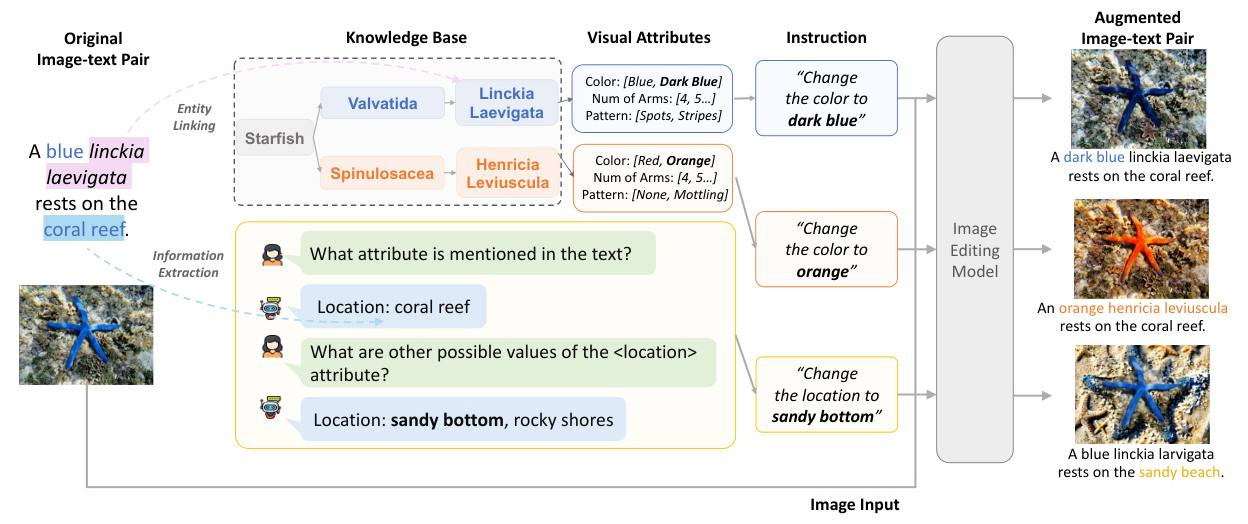
The primary goal of ARMADA is to generate new images by modifying the visual attributes of mentioned entities. The first step involves identifying the mentioned entities and their visual attributes within a given piece of text using LLMs. For example, from the sentence “A blue linckia laevigata rests on the coral reef,” the entity is linckia laevigata, the visual attributes are color and location, and the attribute values are blue and coral reef, respectively.
KB-based Visual Attribute Substitution
After identifying visual attributes, ARMADA determines potential substitutions for their attribute values using attributes from entity-centric KBs. The KB is constructed by parsing information from Wikidata and Wikipedia, creating an attribute-level KB consisting of entities and their attributes. The framework performs two types of attribute value substitutions: within a single entity and across sibling entities.
LLM-based Visual Attribute Substitution
In cases where the extracted entity or visual attribute is too general and cannot be linked to any node in the KB, ARMADA uses LLMs to obtain new values for auxiliary visual attributes. This approach leverages the commonsense knowledge of LLMs to provide alternative attribute values for such cases.
Image Editing
After modifying an image-text pair with a new text, ARMADA employs an image editing model, InstructPix2Pix, to edit the image according to the new text. The model takes an image and an instruction on how to modify the image, outputting the modified image following the instruction.
Augmented Data Selection
To determine the validity of the augmented data, ARMADA calculates the similarity between a generated image and its original counterpart using the Fréchet Inception Distance (FID) score. This ensures that the generated images exhibit a reasonable amount of difference from the original images, maintaining the quality of the augmented data.
Experimental Design
Foundation Models and Baseline Methods
The experiments use CLIP and LLaVA-1.5 as the foundation models. The performance of ARMADA is compared against five baseline methods: Zero-shot, NoAug, NaiveAug, MixGen, and LeMDA.
Image Classification
The iNaturalist 2021 dataset is used for image classification. The dataset consists of large-scale species of plants and animals in the natural world. The models are evaluated based on Precision, Recall, and F1 scores.
Visual Question Answering
The VQA v2.0 dataset is used for the visual question answering task. The performance is evaluated based on textual similarities using Universal Sentence Encoder (USE) and BERTScore.
Image-Text Retrieval
The Flickr30k dataset is used for image-text retrieval, which includes two subtasks: text-to-image and image-to-text retrieval. The performance is evaluated using Recall@K.
Image Captioning
The image captioning task aims to generate natural language descriptions of an image. The performance is evaluated based on textual similarities using USE and BERTScore.
Results and Analysis
Image Classification
ARMADA achieves the best results among all existing methods, demonstrating significant improvements in Precision, Recall, and F1 scores. The method effectively generates new images by modifying the visual attributes of entities, facilitating a more comprehensive learning of fine-grained concepts by foundation models.
Visual Question Answering
ARMADA surpasses the best baseline method MixGen by 1.1% on USE and 1.4% on BERTScore, demonstrating its effectiveness in generating semantically consistent and knowledge-grounded multimodal data.
Image-Text Retrieval
While the improvement of ARMADA over baseline methods in this task appears less significant, it still achieves the best performance, highlighting the robustness of the proposed method.
Image Captioning
ARMADA achieves the best performance over all baseline methods, with a performance gain of 4.0% on USE score over NoAug and 2.3% over MixGen. The method effectively generates high-quality captions that closely align with the gold-standard annotations.
Overall Conclusion
ARMADA is a novel data augmentation method that leverages KBs and LLMs to generate semantically consistent and knowledge-grounded multimodal data. The proposed framework significantly improves the performance of MLMs on various downstream tasks without the need for high-cost annotated data. Future work aims to incorporate more modalities into the framework and design a new visual attribute editing model to further enhance the quality of the augmented data.








