





Authors:
Zongjie Li、Daoyuan Wu、Shuai Wang、Zhendong Su
Paper:
https://arxiv.org/abs/2408.08343
Introduction
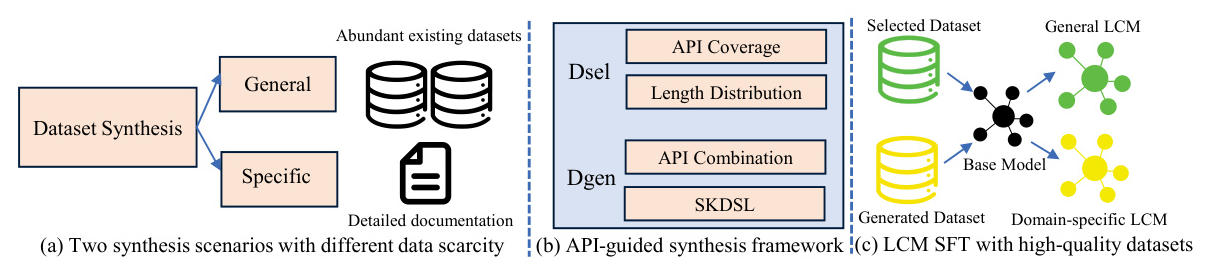
Large Code Models (LCMs) have shown exceptional performance in various code-related tasks. However, their out-of-the-box performance may not be optimal for all use cases. Supervised Fine-Tuning (SFT) is a critical approach to align these models with specific requirements, enhancing their performance in particular domains. The challenge lies in synthesizing high-quality SFT datasets due to uneven quality and scarcity of domain-specific datasets. Inspired by APIs, which encapsulate rich semantic information in a concise structure, the authors propose DataScope, an API-guided dataset synthesis framework designed to enhance the SFT process for LCMs in both general and domain-specific scenarios.
Background
Large Code Models
LCMs, such as CodeLlama and StarCoder, are specialized variants of Large Language Models (LLMs) tailored for code-related tasks. These models are pre-trained on vast code corpora and fine-tuned on task-specific datasets to optimize their performance. The Transformer architecture, which relies on attention mechanisms, is commonly used in these models.
Supervised Fine-tuning
SFT involves further training pre-trained models on carefully curated instruction datasets, typically comprising formatted instruction-response pairs. This process aligns models with human expectations and enhances their capabilities. SFT can be categorized into full parameter supervised fine-tuning and parameter-efficient fine-tuning (PEFT), with the former being the focus of this study.
Two Mainstream LCM Fine-tuning Scenarios
- General Scenario: Fine-tuning models to improve general code generation capabilities using abundant existing datasets.
- Domain-Specific Scenario: Fine-tuning models to enhance performance in specific domains using domain-specific datasets, which are often scarce and require expertise to curate.
A Motivation Example
The authors illustrate the benefits of using APIs in LCM program comprehension through an example. Two semantically equivalent code snippets are presented, one using a highly abstracted API call and the other with the API call expanded. The LCM’s responses and internal attention patterns reveal that API abstractions improve token efficiency, semantic comprehension, and internal attention patterns, thereby enhancing the model’s performance.


API-guided Dataset Selection (Dsel): Design and Evaluation
Problem Formulation
The goal is to select a subset from an SFT dataset to optimize the performance of a model trained on this subset. The optimization problem is formulated to maximize API coverage while maintaining a representative distribution of code lengths.
Selection Algorithm
A sub-optimal greedy algorithm is proposed to efficiently solve the optimization problem. The algorithm iteratively selects examples that maximize the incremental API coverage while maintaining the diversity of code lengths.

Experimental Setup for General Scenario
The authors evaluate Dsel on two datasets: CODEE and OSS, using CodeLlama models of different sizes (7B, 13B, and 34B parameters). The Humaneval benchmark is used to assess the performance of SFT models on code generation tasks, with Pass@k as the primary metric.

Results for Dsel
Dsel consistently achieves higher API coverage and lower JS divergence compared to baselines. Models fine-tuned using Dsel-selected subsets outperform those trained on the full SFT dataset, especially for larger models. This demonstrates the effectiveness of Dsel in improving the performance of larger models while using fewer examples.

API-guided Dataset Generation (Dgen)
Problem Statement and Approach Overview
Dgen addresses the challenge of dataset scarcity in domain-specific scenarios by generating high-quality SFT datasets leveraging API combinations. The process involves three steps: API collection, instruction generation, and dataset generation.

Generation Algorithm
- API Collection: Extract APIs from the library’s official documentation and categorize them into basic and advanced types.
- Instruction Generation: Prepare instructions for querying the LLM to synthesize the SFT dataset, using API sets of varying difficulty levels and a domain-specific language (SKDSL) to govern code structure.
- Dataset Generation: Use the generated instruction prompts to query the LLM, producing library-specific instruction and response code pairs, which undergo format and content validation.
Bench: A Benchmark for Evaluating Code Generation in Specific Domains
Bench is a novel benchmark designed to assess model performance on specific domains. The creation process involves problem selection, instruction rewriting, and human inspection to ensure the quality and relevance of the included questions.

Experimental Setup for Specific Scenario
The authors evaluate Dgen on Bench using CodeLlama models and various metrics, including CodeBLEU, cyclomatic complexity, Silhouette Coefficient, and Calinski-Harabasz Index.
Results for Dgen
Fine-tuning models using Dgen-generated datasets consistently improves their performance on all three libraries compared to the base versions without fine-tuning. The combination of different API sets and the use of SKDSL contribute to the improvement in model performance.

Related Work
The authors discuss related work in component-based program synthesis, SFT dataset selection, and SFT dataset generation. They highlight the unique aspects of Dsel and Dgen, such as focusing on LCMs and using APIs in combination with program skeletons to generate high-quality SFT datasets.
Conclusion
DataScope, comprising Dsel and Dgen, addresses the challenges of dataset quality and scarcity in both general and domain-specific scenarios. The API-guided approach to dataset synthesis improves the efficiency and effectiveness of fine-tuning, enhancing model performance and providing a scalable solution for LCMs. Further research in this direction will lead to more powerful and adaptable LCMs, opening new avenues for AI-assisted software development.


