





Authors:
Xinlang Yue、Yiran Liu、Fangzhou Shi、Sihong Luo、Chen Zhong、Min Lu、Zhe Xu
Paper:
https://arxiv.org/abs/2408.10479
Introduction
Order-dispatching, the process of assigning passenger orders to available drivers in real-time, is a critical function in ride-hailing platforms. This process significantly impacts the service experience for both drivers and passengers. There are two primary research scopes in this domain: macro-view and micro-view order-dispatching (MICOD). The macro-view focuses on long-term, city-level efficiency optimization, while MICOD deals with localized spatiotemporal scenarios characterized by high stochasticity.
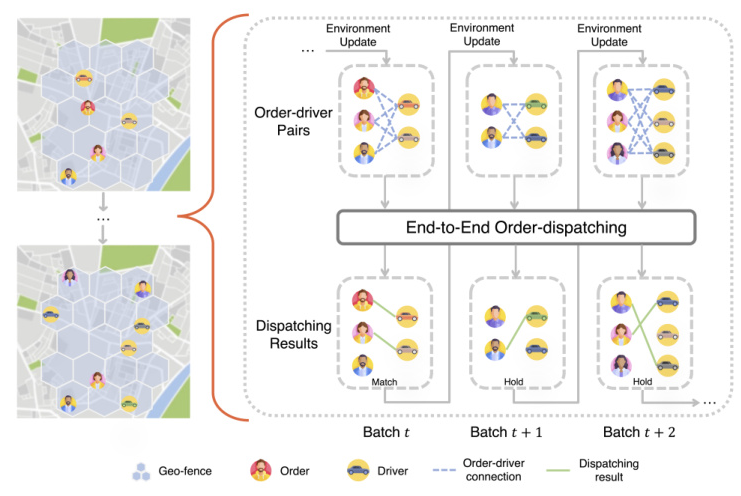
MICOD involves matching an unspecified number of drivers and orders within each decision window, optimizing goals such as driver income and pickup distance over multiple batches within a localized area. The major challenge in MICOD arises from its bilateral dynamics, where both the number and contextual attributes of drivers and orders remain unknown in upcoming batches. This problem can be regarded as a sequential decision-making problem, where each decision entails solving a combinatorial optimization (CO) task on order-driver (o-d) assignment.
Existing industrial methodologies typically follow a two-stage pattern of “holding + dispatching,” which includes general CO approaches like the greedy method, the Hungarian algorithm, and the stable matching method. However, these methods do not guarantee global optimization across multiple batches. To address this, Didi Chuxing has developed a one-stage end-to-end reinforcement learning (DRL) based approach that uniformly solves behavior prediction and combinatorial optimization in a sequential decision-making manner.
Related Works
Reinforcement Learning in Ride-Hailing
Reinforcement learning (RL) has been widely applied to large-scale ride-hailing problems, often formulated in a Markov Decision Process (MDP) setting. Various approaches have been explored, including modeling each driver as an agent, multi-agent RL (MARL) frameworks, and hierarchical settings. However, most existing works assume driver homogeneity and ignore contextual diversity.
Online Matching in Order-Dispatching
Research on online matching has been conducted in various industries, including online allocation and crowd-sourcing. The MICOD scenario is unique due to its changing bilateral dynamics and batching operating manner. Some works consider drivers’ and orders’ eligibility for entering the bipartite matching and investigate batched window optimization using RL methods to achieve long-term gains. However, these approaches treat the dispatching process as part of the environment changes rather than actions.
Research Methodology
MICOD Formulation
A typical MICOD problem in Didi must comply with the following:
- Micro-view: The spatiotemporal range is restricted to a brief time period (usually 10 minutes) and a geo-fence (around 30 square kilometers).
- Dynamic contextual patterns: Both drivers and orders may emerge or go offline following their own or joint behavioral patterns.
- Batch mode: MICOD performs order-dispatching in a batch mode, where the size-unspecified o-d assignment can be formulated as a CO problem.
The objective is to maximize the cumulative gain over the entire period of all batches, leveraging contextual information for each o-d assignment.
Two-layer MDP Framework
The problem is modeled as an MDP process, with the order-dispatching system as the agent and the action being the selection of o-d pairs as dispatching results. Due to the dynamic contexts in MICOD, the action space changes in each batch, making regular MDP transitions hard to model. Instead, the problem is decomposed into a two-layer MDP framework with the same agent.
Outer-layer MDP
- Agent: The centralized order-dispatching system.
- State: Consists of global-level and local-level information.
- Action: Represents the combinatorial o-d assignment decision in each batch.
- Policy: Specifies the probability of selecting a combination of pairs as action.
- State transition and initial state distribution: Captures the results and bilateral uncertainty induced by the workflow.
- Reward: Aligned with different optimization goals, such as maximizing driver income or minimizing pickup distances.
Inner-layer MDP
- Agent: The centralized order-dispatching system.
- Sub Action: Two categories – Decision (choosing an o-d pair) and Hold (predicting whether to end the current dispatching process).
- Sub State: Represents intermediate dynamics of state and all previously generated sub-actions.
- Inner-layer Reward: Set to 0 within each sub-state transition, with the same reward as in the outer-layer received when a complete action is finished.
- Sub Policy: Decomposed into corresponding sub-policies for each sub-step.
Deep Double Scalable Network (D2SN)
D2SN is an encoder-decoder structure network designed to generate assignments with auto-regressive factorization, adapting to the scalability of the action space. The encoder processes the contextual information of all o-d pairs, while the decoder outputs the decision probability of each o-d pair and the hold action decision.
Encoder
The encoder takes the input of contextual information of all o-d pairs and outputs a latent embedding of all pairs using multi-head attention blocks and position-wise feed-forward operations.
Decoder
The decoder takes the latent embedding and global contextual information as input and outputs the decision probability of each o-d pair and the hold action decision. It includes a shared module to normalize feature dimensions before the two action modules.
Cooperation
The auto-regressive sub-action sampling within the encoder-decoder cooperation generates sub-actions at each sub-step, updating the state and sub-state accordingly.
Deep Reinforcement Learning with D2SN
The two-layer MDP adopts clipped proximal policy optimization (PPO), with DRL operating in the outer-layer and the inner-layer modeled with D2SN. The training consists of an auto-regressive actor (D2SN) and a value-independent critic, with network parameters optimized using mini-batch Adam.
Experimental Design
Industrial Benchmarks
Real-world trajectories from multiple cities in China in 2023 were used to create benchmarks classified into 12 unique types based on the combination of demand and supply (D&S) ratios and ranges of driver capacity.
Simulator
An MICOD-customized simulator operates in a batch mode of 2 seconds for each 10-minute dataset, generating orders and drivers and simulating contextual dynamics and behavioral patterns.
Baselines
Six competitive baselines were used for comparison, including naive CO methods (Greedy, Kuhn-Munkres, Gale-Sharpley) and two-stage approaches (Restricted Q-learning, Interval Delay, Spatiotemporal Hold).
Evaluation Metrics
Two tasks were focused on: Average Pickup Distance (APD) and Total Driver Income (TDI). The APD task aims to minimize the average pickup distance and maximize the complete ratio, while the TDI task considers both the complete ratio and the income of all drivers.
Implementation Details
DRL baselines were optimized with the same training strategy and input features, converging within a maximum of 50 epochs. The o-d feature embedding dimension was set to 256, and the learning rate was set to 0.002 with Adam. Evaluations were conducted with different seeds over 30 runs, and experiments were conducted on a server with an Intel Xeon Platinum CPU and an Nvidia RTX A6000 GPU.
Results and Analysis
Main Results
D2SN displayed notable advantages over baselines in both APD and TDI tasks. It outperformed the deployed policy Spatiotemporal Hold in all scenarios, indicating its potential for online performance.
APD Task
D2SN achieved the highest complete ratio in all L1 tasks, demonstrating its capability to jointly satisfy order requests and pickup experience over the entire time period.
TDI Task
D2SN showed robust improvement in terms of TDI and complete ratio, especially in scenarios with higher D&S ratios, indicating its ability to capture contextual changes and predict cancellation behaviors.
Performance Analysis
Ablation Study
An ablation study validated the effectiveness of D2SN by removing the Hold module, showing that the Decision module alone performed similarly to Kuhn-Munkres but lagged behind D2SN in terms of APD and TDI.
Hold Module Analysis
The Hold module of D2SN was effective in holding pairs with far pickup distances to downsize APD and holding pairs that may negatively impact drivers’ income, demonstrating its advantage in maximizing TDI and minimizing APD.
Overall Conclusion
This study addresses the challenges of MICOD in online ride-hailing by proposing an end-to-end DRL framework with a novel network D2SN. The framework uniformly resolves prediction, decision-making, and optimization without any CO algorithms, showing significant improvements in matching efficiency and user experience. The approach has the potential to benefit other domains of online resource allocation and solve practical optimization problems.













